对于同步到从节点以及迁移工具的数据 , 会在头部添加id字段 , 针对不同来源的数据或者无需同步到远端的数据通过id来标识区分;本地业务客户端写入的数据需要同步到远端数据中心 , 分配id大于0;来源于其他数据中心的数据分配id小于0;一些仅用于主从心跳交互的命令数据分配id也小于0 。
同步工具解析完数据后 , 过滤掉id小于0的命令 , 只需要向远端写入id大于0的数据 , 即本地业务客户端写入的数据 。来源于其他数据中心的数据均不回写到远端数据中心 。
4、过期与淘汰数据目前过期与淘汰均由各数据中心redis节点分别独立处理 , 由过期与淘汰删除的数据不进行同步;即由过期与淘汰产生的删除命令其id分配为小于0 , 并由同步工具过滤掉 。
(1)同步产生的问题为什么不同步过去?因为在内存中hash表里面保存的数据没有标记数据中心来源 , 过期与淘汰的数据有可能来自于其他数据中心 , 如果来自于其他数据中心的数据被过期或淘汰并且又同步到远端其他数据中心 , 就会出现数据双写冲突的场景 。双写冲突可能会导致数据不一致 。
(2)不同步产生的问题对于过期数据来说 , 不同步删除可能会导致不同数据中心数据显示不一致 , 但是一定会最终一致 , 且不会出现脏读;
对于淘汰数据来说 , 目前的不同步删除的方案 , 假如出现淘汰 , 会导致不同数据中心数据不一致;目前只有通过运维手段 , 比如充足预分配、及时关注内存使用率告警 , 来规避淘汰数据现象发生 。
5、数据迁移在redis集群模式中 , 一般是在发生横向扩容增加集群主节点数时 , 需要进行槽以及数据的迁移 。
redis集群中数据迁移以槽为维度进行迁移 , 将槽中所有数据从源节点迁移到目标节点 , 然后将槽号标记为由新的目标节点负责 , 同时每迁移完一个Key , 会在源节点中进行删除 , 将migrate命令替换为del命令;同时迁移数据是在源节点中给目标节点发送restore命令实现 。
我们数据迁移的策略依然是 , 各个数据中心独立的完成扩容与数据迁移工作 , 迁移过程产生的del和restore命令不进行跨数据中心同步;把替换后的del命令和发送给目标节点的restore命令都分配小于0的id , 于是同步过程中会由同步工具进行过滤掉 。
六、redis性能经测试 , redis多活实例(默认开启rlog日志) , 相对于原生redis实例(开启aof持久化)性能基本一致;如下图所示:
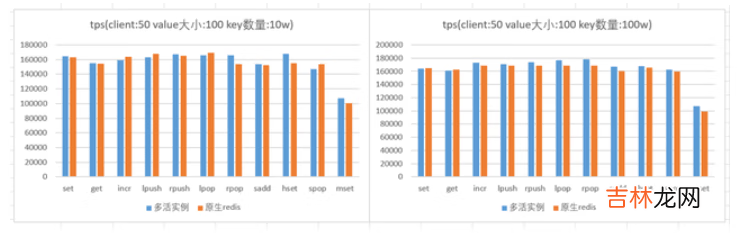
文章插图
注:以上图表使用redis benchmark进行压测 , 压测时 , 客户端和服务端在同一个机器上
七、待优化项1、多写冲突多个数据中心同时写 , key冲突问题暂未解决 。
后续解决方案为使用CRDT协议;CRDT(Conflict-Free Replicated Data Type)是各种基础数据结构最终一致算法的理论总结 , 能根据一定的规则自动合并 , 解决冲突 , 达到强最终一致的效果 。
目前解决方案为业务对写入不同机房的数据进行拆分 , 以保证不会出现冲突 。
2、list类型幂等性五种基本类型里面 , list类型大部分操作都是非幂等的 , 暂时未做幂等性改造优化 。不建议使用或者业务自身保证使用list的数据操作幂等 。
经验总结扩展阅读












- DNF装备怎么跨界在哪跨界
- 五 JPA - 原生SQL实现增删改查
- 中级会计职称考试能跨省报考吗
- 跨界歌王第4季何时播出?
- 原生之罪中的桦城是哪里?
- 跨界歌王邓伦在第几季?
- 跨年是什么意思?
- 跨服式聊天是什么意思?
- DNF怎么获得十周年史诗跨界石?
- 华夏金卡异地跨行取款手续费是多少?