比较适合使用Redis来生成每天从0开始的流水号 。比如订单号=日期+当日自增长号 。可以每天在Redis中生成一个Key,使用INCR进行累加 。
Redis生成ID优点:
1)不依赖于数据库,灵活方便,且性能优于数据库 。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助 。
Redis生成ID缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度 。
2)需要编码和配置的工作量比较大 。
4.利用zookeeper生成唯一IDzookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号 。
很少会使用zookeeper来生成唯一ID 。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁 。因此,性能在高并发的分布式环境下,也不甚理想 。
5.snowflake雪花算法生成ID这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
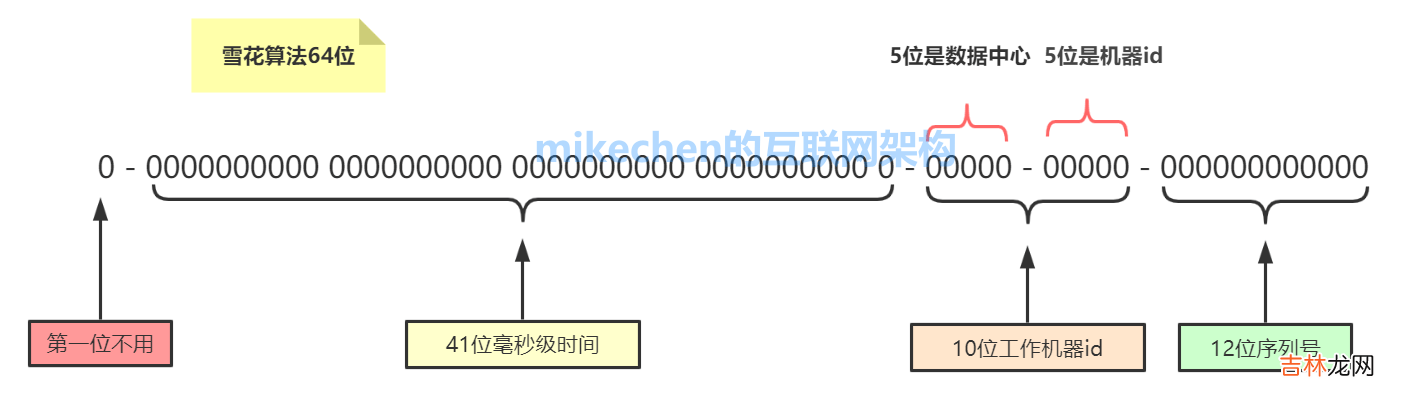
文章插图
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器 。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器 。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义 。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的 。
雪花算法ID优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的 。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的 。
- 可以根据自身业务特性分配bit位,非常灵活 。
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态 。
作者简介陈睿|mikechen,10年+大厂架构经验,《BAT架构技术500期》系列文章作者,专注于互联网架构技术 。
阅读mikechen的互联网架构更多技术文章合集
Java并发|JVM|MySQL|Spring|Redis|分布式|高并发
【5种分布式ID生成方案 分布式ID详解】
经验总结扩展阅读
















- aardio + Python 可视化快速开发桌面程序,一键生成独立 EXE
- 女生成人自考大专报什么专业 哪些专业吃香
- .Net下的分布式唯一ID
- 微信人生成绩单怎么测试?
- 生石灰加水生成什么
- 卫星轨道的5种分类方式
- 蜡烛燃烧后生成了什么
- 搬家的五谷杂粮是哪5种
- 淘宝订单截图制作自定义 淘宝订单制作截图生成器
- iPhone手机5种最简单的解锁方法 苹果手机锁屏密码怎么解除