2.1 Apache Geode的架构 2.1.1 通信拓扑
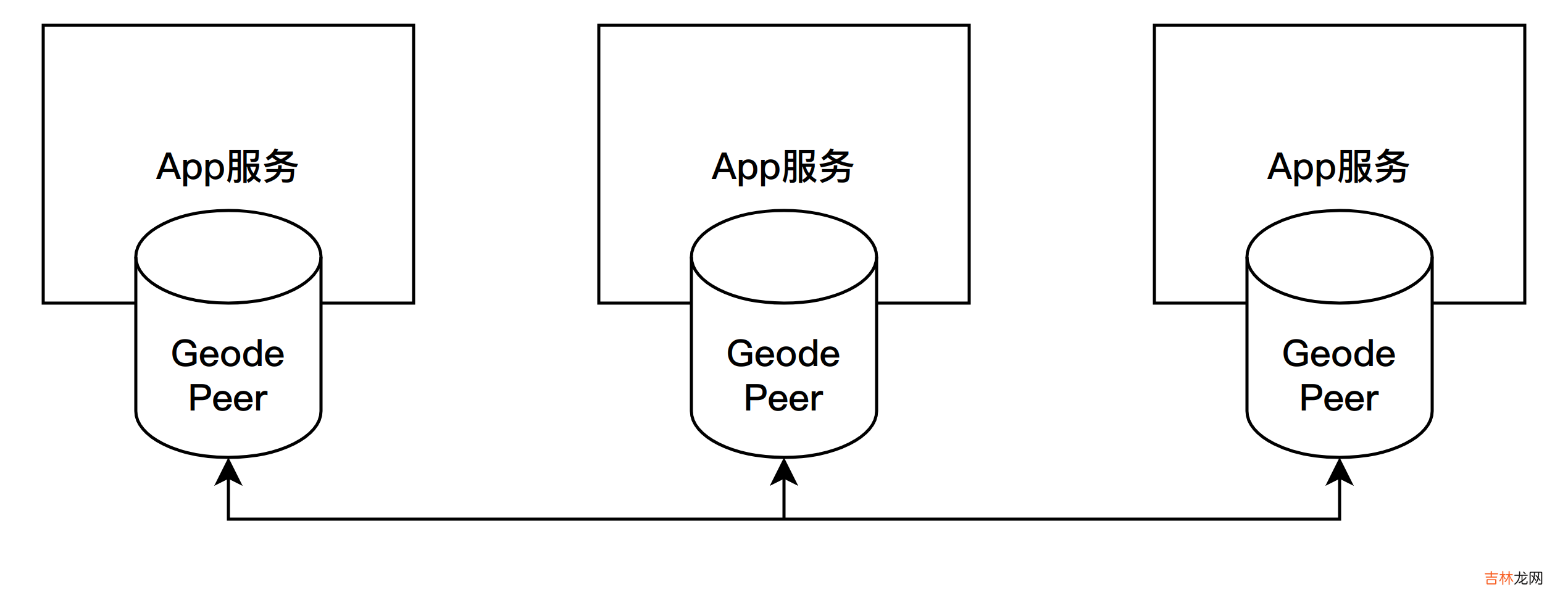
- 2.1.1.1 点对点
文章插图
点对点(Peer To Peer)的部署模式没有服务器的概念,所有参与缓存的节点一视同仁,这种部署模式主要用于把缓存嵌入到集群中每个应用节点上 。
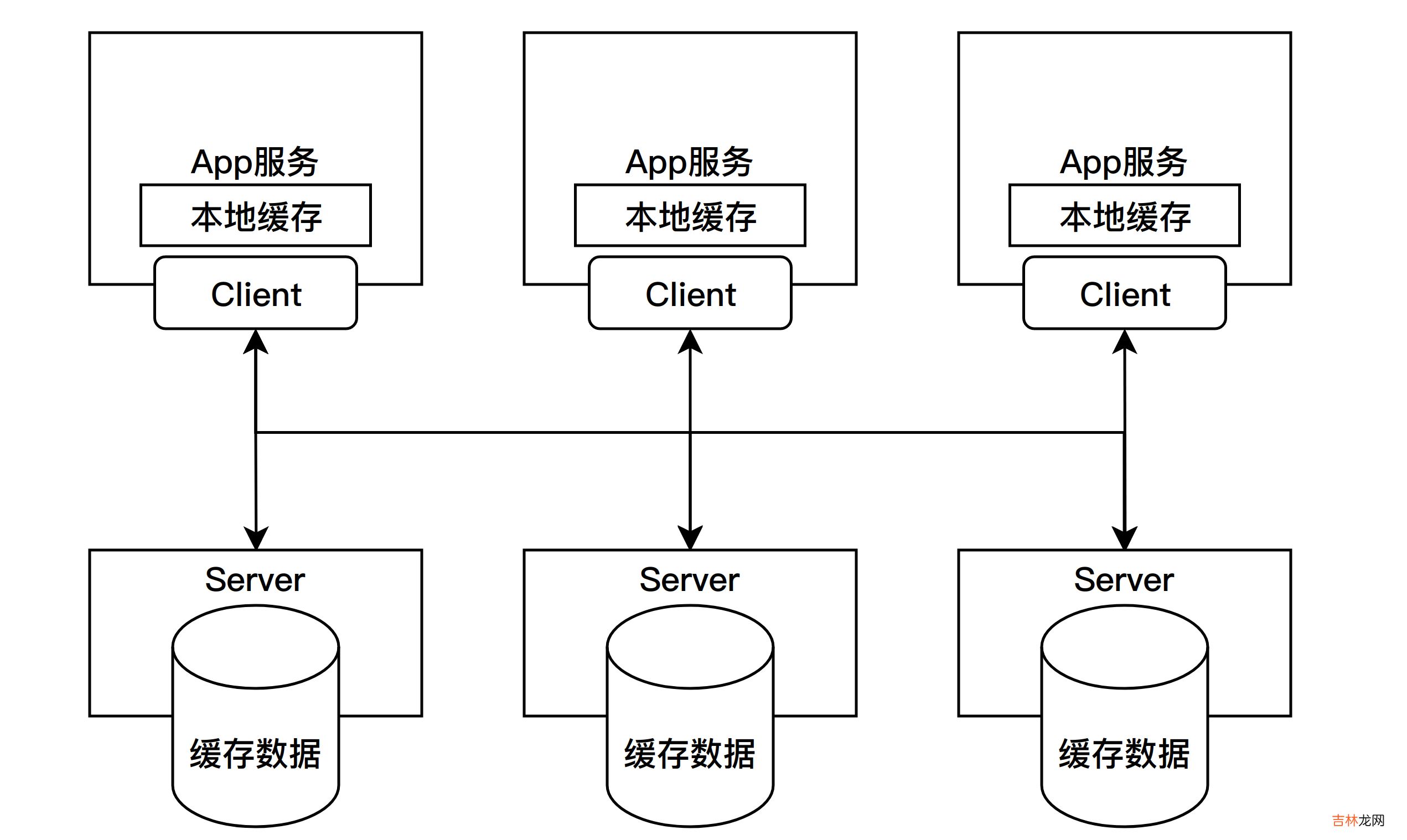
- 2.1.1.2 客户端/服务器
文章插图
客户端/服务器部署下,Apache Geode作为独立的集群服务存在,这样部署的好处是,客户端只选择性地保留一小部分本地缓存,将大部分缓存数据委托给服务集群,节点和节点之间不需要频繁地进行数据分发,也更便于进行扩展 。
Client可以配置连接到哪个Server服务器,但更合理的配置方式是连接到某个Locator上,由这个Locator为Client分配一个负载较低的Server,Client启动后只会和Locator沟通一次,在获知被分配到的Server的IP和端口之后,每次读写都会直接连接到Server上 。
2.1.3 数据存储形式和区域市面上大部分的内存数据存储,都将数据按键值对的格式进行存放,Geode也是如此 。但与Redis等简单的KV不同,Geode将KV数据们按数据区域(Region)进行组织 。对于不同的区域可以单独配置(如是否分区或需要副本) 。
数据区域可以类比于关系型数据库中的表的概念,是一系列结构相同的数据结构的集合 。实际上,在实现上数据区域就是一个ConcurrentMap<K, V>,其键就是一条数据的唯一性标识(类型任意,只要重写了equals和hashcode以便于Region确认键的唯一),其值是一个表达完整数据概念的对象,这样其实也让一条数据中按类的成员又划分出了列的概念 。基于这种类似关系型数据库的存储模式,Geode提供了一种类似于SQL的查询语言,称为OQL,并支持多区域查询(类似于连表查询) 。下面是一个OQL查询的小例子:
class DictPlatform implements DataSerializable { short platformId; String name; String status;}class TestServiceImpl { public void query() { String queryString = "SELECT dp.platformId, dp.name FROM /dict_platform dp WHERE dp.status >= 0;" QueryService queryService = cache.getQueryService(); Query query = queryService.newQuery(queryString); SelectResults results = (SelectResults)query.execute(); DictPlatform p = (DictPlatform)results.iterator().next(); }}
- 2.1.3.1 区域的分布式存储和复制
数据区域可配置的类型主要为 Partitioned , Replicated , Distributed non-replicated , Non-distributed 这四种 。下面重点介绍前两种类型 。
- Partitioned 分区区域如果某个区域数据量很大,一个成员放不下,可以将这个区域划分为多个bucket,分别存储在不同的server上,为了保证高可用,可以让不同的bucket的副本分布在多个server上,以某个server上的bucket作为master,很类似于Apache Kafka的设计 。当存储不够,可以增加新的server,增加新server后的需要发起重平衡,重平衡不需要停机,但可能会导致正在执行的事务失败 。可以从任何一个副本中读取到数据,如果和Client联系的那个Server没有想访问的分区的副本,需要经过server间的一跳,将请求转给目标server 。因此,分区的读性能稍差 。
经验总结扩展阅读
- 基于 Apache Hudi 极致查询优化的探索实践
- 如何读懂狗心里在想什么
- 一文搞定 Spring事务
- 可爱在性感面前一文不值是什么意思?
- 一文带你读懂小米手环6和7的区别 小米手环7比6多了什么功能
- 一文看懂华为充电新技术 华为mate30支持无线充电吗
- 苹果如何录入nfc门禁卡 (一文了解iPhone手机添加门禁卡的方法)
- cad表格怎么统一文字高度?
- 牵手一文有哪些方面的含义 牵手一文都有哪些方面的含义
- 情人节:读懂9位作家的婚姻,你就知道何谓家、何谓爱











