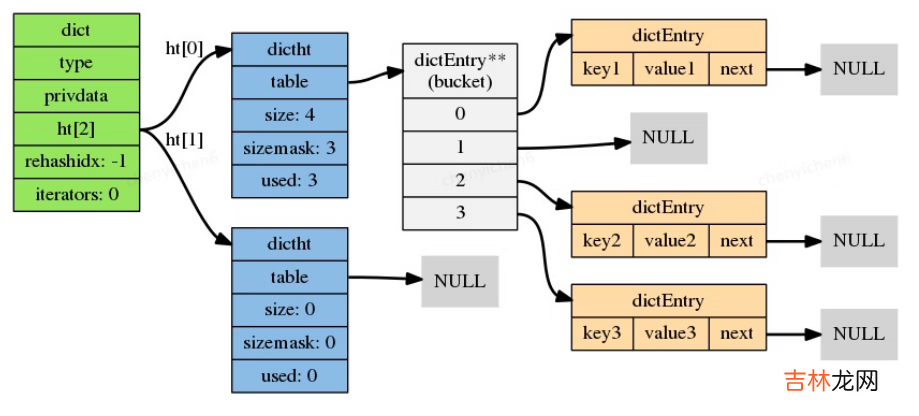
- 负载因子:哈希表已保存节点数量/哈希表大小,load_factor = ht[0].used/ht[0].size
- 扩展操作:
- 服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于 1;
- 服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5;
- 当哈希表的负载因子小于 0.1 时,程序自动开始对哈希表执行收缩操作 。
- 同时持有2个哈希表
- 将rehashidx的值设置为0,表示rehash工作正式开始
- 在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1] ,当rehash工作完成之后,程序将rehashidx属性的值增一
- 某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成
dict.h/redisObject
Typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS;int refcount;void *ptr;}- type:4:约束客户端操作时存储的数据类型,已存在的数据无法修改类型,4bit
- encoding:4:值在redis底层的编码模式,4bit
- lru:LRU_BITS:内存淘汰策略
- refcount:通过引用计数法管理内存,4byte
- ptr:指向真实存储值的地址,8byte
文章插图
3 String类型3.1 String类型使用场景String 字符串存在有三种类型:字符串,整数,浮点 。主要有以下使用场景
1)页面动态缓存比如生成一个动态页面,首次可以将后台数据生成页面,并且存储到redis字符串中 。再次访问,不再进行数据库请求,直接从redis中读取该页面 。特点是:首次访问比较慢,后续访问快速 。
2)数据缓存在前后分离式开发中,有些数据虽然存储在数据库,但是更改特别少 。比如有个全国地区表 。当前端发起请求后,后台如果每次都从关系型数据库读取,会影响网站整体性能 。我们可以在第一次访问的时候,将所有地区信息存储到redis字符串中,再次请求,直接从数据库中读取地区的json字符串,返回给前端 。
3)数据统计redis整型可以用来记录网站访问量,某个文件的下载量 。(原子自增自减)
4)时间内限制请求次数比如已登录用户请求短信验证码,验证码在5分钟内有效的场景 。当用户首次请求了短信接口,将用户id存储到redis 已经发送短信的字符串中,并且设置过期时间为5分钟 。当该用户再次请求短信接口,发现已经存在该用户发送短信记录,则不再发送短信 。
5)分布式session当我们用nginx做负载均衡的时候,如果我们每个从服务器上都各自存储自己的session,那么当切换了服务器后,session信息会由于不共享而会丢失,我们不得不考虑第三应用来存储session 。通过我们用关系型数据库或者redis等非关系型数据库 。关系型数据库存储和读取性能远远无法跟redis等非关系型数据库 。
经验总结扩展阅读













- 2023过小年能贴春联吗 春联一般什么时候贴
- 抖音带货达人是真的吗
- 洗脸巾执行标准GB和Q哪个好 一次性洗脸巾怎么挑选
- 给灶王爷上香每月的初一十五吗 给灶王爷上香是早上还是晚上
- 2023年货节发货快吗 年货节一般是什么时候
- 太平洋车险和平安车险哪个好一些 各有各的优势
- 1一5儿童玩具批发市场在哪里
- 7月15烧纸是提前还是当天呢 7月15一般几点烧纸
- 2023暑期出行求财哪一天最好 暑假适合出行求财的日子有哪
- 2022年哪一天立冬 2022年立冬时间是几月几号