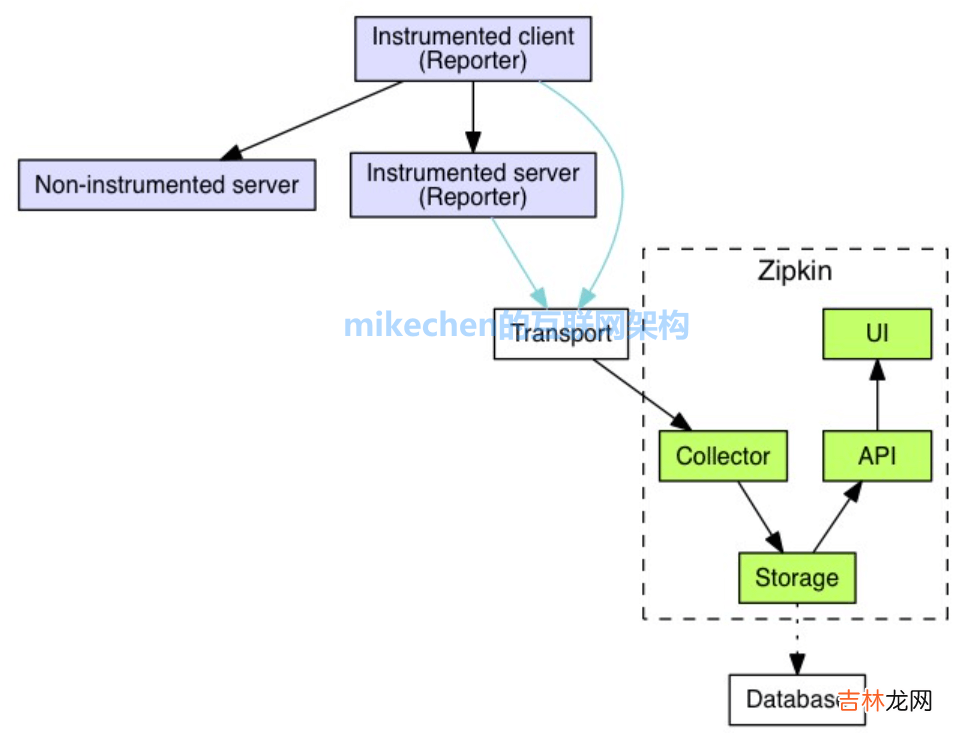
2. Zipkin 核心组件Zipkin (服务端)包含四个组件 , 分别是 collector、storage、search、web UI 。
文章插图
【图文详解 微服务 Zipkin 链路追踪原理】1) collector 信息收集器
collector 接受或者收集各个应用传输的数据 。
2) storage 存储组件
zipkin 默认直接将数据存在内存中 , 此外支持使用 Cassandra、ElasticSearch 和 Mysql。
3) search 查询进程
它提供了简单的 JSON API 来供外部调用查询 。
4) web UI 服务端展示平台
主要是提供简单的 web 界面 , 用图表将链路信息清晰地展示给开发人员 。
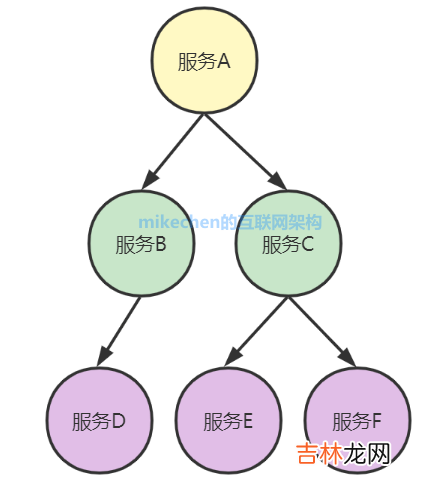
3. Zipkin 核心结构当用户发起一次调用时 , Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id , 并为这条链路中的每一次分布式调用生成一个 span id 。
一个 trace 由一组 span 组成 , 可以看成是由 trace 为根节点 , span 为若干个子节点的一棵树 , 如下图所示:
文章插图
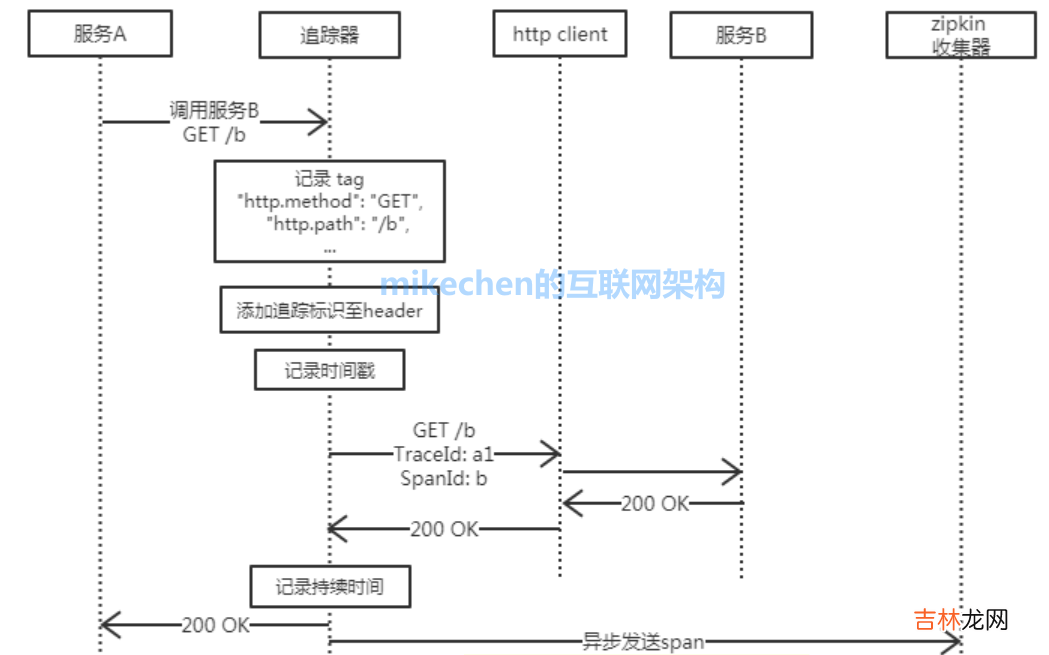
4. Zipkin 的工作流程一个应用的代码发起 HTTP get 请求 , 经过 Trace 框架拦截 , 大致流程如下图所示:
文章插图
1)把当前调用链的 Trace 信息 , 添加到 HTTP Header 里面;
2)记录当前调用的时间戳;
3)发送 HTTP 请求 , 把 trace 相关的 header 信息携带上;
4)调用结束之后 , 记录当前调用话费的时间;
5)把上面流程产生的信息 , 汇集成一个 span , 再把这个 span 信息上传到 zipkin 的 Collector 模块 。
Zipkin 的部署与运行Zipkin 的 github 地址:https://github.com/apache/incubator-zipkin
Zipkin 支持的存储类型有 inMemory、MySql、Cassandra、以及 ElasticsSearch 几种方式 , 正式环境推荐使用 Cassandra 和 ElasticSearch 。

文章插图
总结通过本文 , 我们知道了 Zipkin 的作用、使用场景、架构、核心组件 , 以及 Zipkin 的工作流程等 , 希望对大家掌握微服务有所帮助 。
作者简介陈睿 | mikechen , 10年+大厂架构经验,「mikechen 的互联网架构」系列文章作者 , 专注于互联网架构技术 。
阅读「mikechen 的互联网架构」40W 字技术文章合集
Java并发 | JVM | MySQL | Spring | Redis | 分布式 | 高并发
经验总结扩展阅读
















- 冬至祝福微信
- 电影谜一样的双眼剧情详解?
- 谍影重重4剧情详解?
- 四十六 SpringCloud微服务实战——搭建企业级开发框架:【移动开发】整合uni-app搭建移动端快速开发框架-环境搭建
- 霜降给客户的微信祝福语
- 为什么晒太阳会变黑 稍微晒一下就变黑原因
- 西虹市首富剧情详解?
- 小米手环6nfc版可不带手机吗?能接电话看微信吗?
- 高考的微信祝福文案
- 2022感恩节的微信祝福语