文章插图
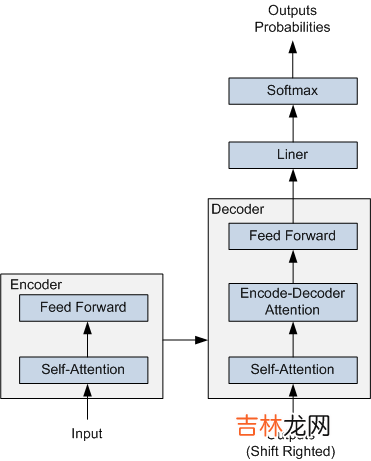
图 1 Transformer 的简要结构图
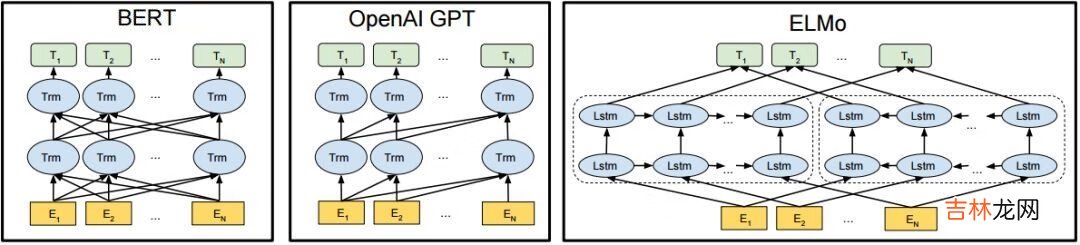
Transformer 在机器翻译任务上面证明了其超过 LSTM/GRU 的卓越表示能力 。从 RNN 到 Transformer,模型的表示能力在不断的增强,语义表示模型的骨架也经历了这样的一个演变过程 。如图2所示,该图为BERT、GPT 与 ELMo的结构示意图,可以看到 ELMo 使用的就是 LSTM 结构,接着 GPT 使用了 Transformer Decoder 。进一步 BERT 采用了双向 Transformer Encoder,从理论上讲其相对于 Decoder 有着更强的语义表示能力,因为Encoder接受双向输入,可同时编码一个词的上下文信息 。最后在NLP任务的实际应用中也证明了Encoder的有效性,因此ERNIE也采用了Transformer Encoder架构 。
文章插图
图2 BERT、GPT 与 ELMo
2.2 ERNIE介绍了 ERNIE 的骨架结构后,下面再来介绍了 ERNIE 的原理 。
ERNIE 分为 1.0 版和 2.0 版,其中ERNIE 1.0是通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识 。相较于BERT学习原始语言信号,ERNIE 1.0 可以直接对先验语义知识单元进行建模,增强了模型语义表示能力 。例如对于下面的例句:“哈尔滨是黑龙江的省会,国际冰雪文化名城”
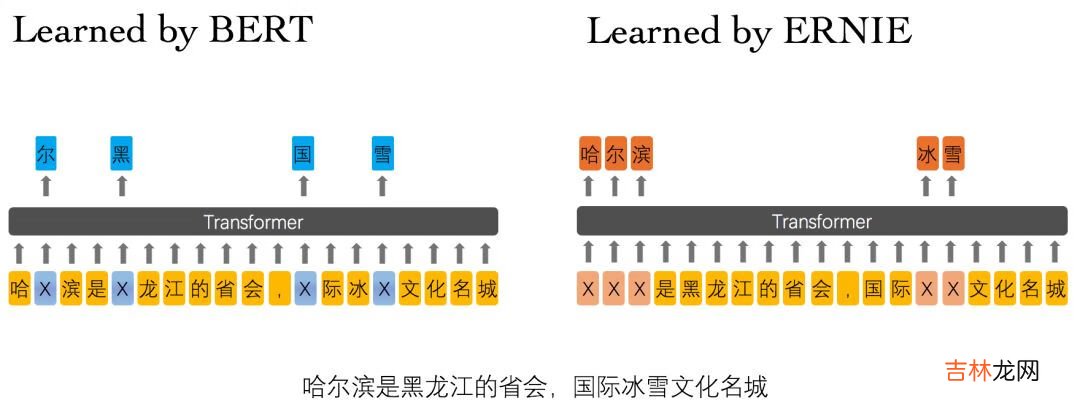
文章插图
图3 ERNIE 1.0 与 BERT 词屏蔽方式的比较
BERT在预训练过程中使用的数据仅是对单个字符进行屏蔽,例如图3所示,训练Bert通过“哈”与“滨”的局部共现判断出“尔”字,但是模型其实并没有学习到与“哈尔滨”相关的知识,即只是学习到“哈尔滨”这个词,但是并不知道“哈尔滨”所代表的含义;而ERNIE在预训练时使用的数据是对整个词进行屏蔽,从而学习词与实体的表达,例如屏蔽“哈尔滨”与“冰雪”这样的词,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市这样的含义 。训练数据方面,除百科类、资讯类中文语料外,ERNIE 1.0 还引入了论坛对话类数据,利用对话语言模式(DLM, Dialogue Language Model)建模Query-Response对话结构,将对话Pair对作为输入,引入Dialogue Embedding标识对话的角色,利用对话响应丢失(DRS, Dialogue Response Loss)学习对话的隐式关系,进一步提升模型的语义表示能力 。
因为 ERNIE 1.0 对实体级知识的学习,使得它在语言推断任务上的效果更胜一筹 。ERNIE 1.0 在中文任务上全面超过了 BERT 中文模型,包括分类、语义相似度、命名实体识别、问答匹配等任务,平均带来 1~2 个百分点的提升 。
我们可以发现 ERNIE 1.0 与 BERT 相比只是学习任务 MLM 作了一些改进就可以取得不错的效果,那么如果使用更多较好的学习任务来训练模型,那是不是会取得更好的效果呢?因此 ERNIE 2.0 应运而生 。ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务 。如图4所示,在ERNIE 2.0中,大量的自然语言处理的语料可以被设计成各种类型的自然语言处理任务(Task),这些新构建的预训练类型任务(Pre-training Task)可以无缝的加入图中右侧的训练框架,从而持续让ERNIE 2.0模型进行语义理解学习,不断的提升模型效果 。

文章插图
图4 ERNIE 2.0框架
ERNIE 2.0 的预训练包括了三大类学习任务,分别是:
- 词法层任务:学会对句子中的词汇进行预测 。
- 语法层任务:学会将多个句子结构重建,重新排序 。
经验总结扩展阅读
- 酸奶冷冻会变成冰淇淋吗
- 一寸照片的尺寸是多少像素
- 滇红茶属于什么茶
- 2024年五月十九出生余姓女孩名字叫什么生辰八字五行查询
- 金骏眉是红茶吗
- 送大学生什么礼物好实用
- 男生一般喜欢什么礼物
- 坐地铁需要身份证吗
- 土豆刚冒出一点小芽的能吃吗
- 一斤面粉放多少酵母