实现def mixup(input_x, input_y, label_size, alpha): # get mixup lambda batch_size = tf.shape(input_x)[0] input_y = tf.one_hot(input_y, depth=label_size) mix = tf.distributions.Beta(alpha, alpha).sample(1) mix = tf.maximum(mix, 1 - mix) # get random shuffle sample index = tf.random_shuffle(tf.range(batch_size)) random_x = tf.gather(input_x, index) random_y = tf.gather(input_y, index) # get mixed input xmix = input_x * mix + random_x * (1 - mix) ymix = tf.cast(input_y, tf.float32) * mix + tf.cast(random_y, tf.float32) * (1 - mix) return xmix, ymixPytorch的实现如下
class Mixup(nn.Module): def __init__(self, label_size, alpha): super(Mixup, self).__init__() self.label_size = label_size self.alpha = alpha def forward(self, input_x, input_y): if not self.training: return input_x, input_y batch_size = input_x.size()[0] input_y = F.one_hot(input_y, num_classes=self.label_size) # get mix ratio mix = np.random.beta(self.alpha, self.alpha) mix = np.max([mix, 1 - mix]) # get random shuffle sample index = torch.randperm(batch_size) random_x = input_x[index, :] random_y = input_y[index, :] xmix = input_x * mix + random_x * (1 - mix) ymix = input_y * mix + random_y * (1 - mix) return xmix, ymix迁移到NLP场景
mixup的方案是在CV中提出,那如何迁移到NLP呢?其实还是在哪一层进行差值的问题,在NLP中一般可以在两个位置进行融合,在过Encoder之前对词向量融合,过Encoder之后对句向量进行融合 。
- paper: Augmenting Data with mixup for Sentence Classification: An Empirical Study
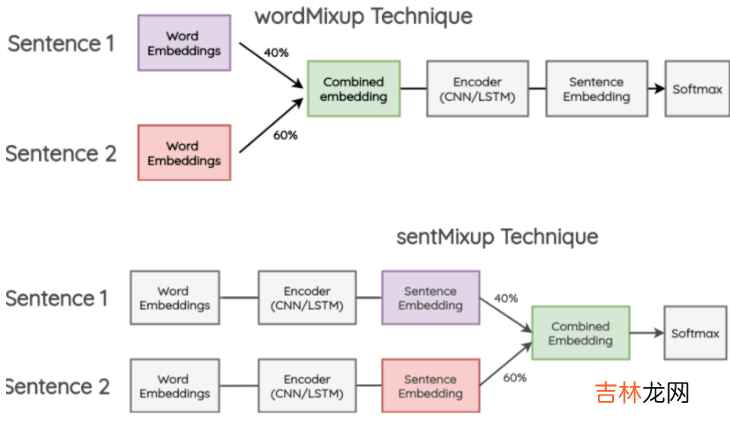
文章插图
作者在文本分类任务上对比了二者的效果,并尝试了随机词vs预训练词向量 * 允许微调vs冻结词向量,总共4种不同的情况 。整体上不论是wordmixup还是sentmixup都对效果有一定提升,不过二者的差异并不如以上的CV实验中显著 。

文章插图
在[应用类别识别挑战赛](https://challenge.xfyun.cn/topic/info?type=scene-division)中,我分别尝试了FGM,Temporal半监督,文本增强,和mixup来提升文本分类模型的效果 。在我使用的词+字向量的TextCNN模型结构中,mixup的表现最好,单模型在初赛排到13名 。之后等Top3解决方案出来后,我们再来总结这个比赛~
经验总结扩展阅读













- 小区业主是指户主吗
- 2022支付宝小鸡今日答题答案
- 支付宝庄园小课堂9月9日正确答案
- 家里有小虫子怎么消除
- 家里烂水果有小飞虫怎么消灭
- 简单易学的街边小吃
- 马桶堵了怎么办小窍门
- 2023年哪天是小暑节气
- 小声说话的标志
- 2023年几号是小暑节气