create、delete、open、close、read以及write文件 。特殊地,GFS 还有**快照 snapshot **和 记录追加 record append 操作 。
- 快照低开销地创建了一个文件或目录树的拷贝 。
- 记录追加允许多个客户端同时向一个文件追加数据,并保证每个单独的客户端追加操作的原子性 。可以用于实现多路结果合并和生产者-消费者队列,它们使很多客户端在不加锁的情况下可以同时进行追加操作 。
文章插图
GFS 文件被划分为固定大小的块,每个块由一个不变的、全局唯一的 64bit 块句柄标识,它是由主节点在创建块时分配的 。块服务器存储这些块并对其进行读写操作,为了提高可靠性,每个块都会在多个块服务器上进行复制 。默认情况下,我们会存储三个副本,用户也可以对不同的命名空间设置不同的复制级别 。
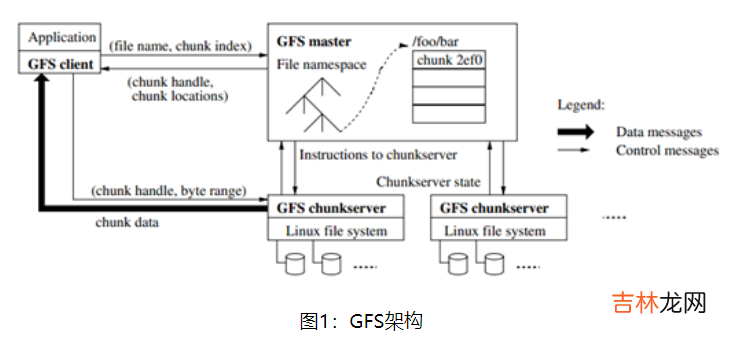
Master 存储了整个文件系统的元数据,包含命名空间、访问控制信息、文件到块的映射,以及块的当前位置等等 。它也控制了一些系统层的行为,如块的租约管理,孤儿块的垃圾回收,以及块服务器之间的块迁移 。Master 周期性地与每个块节点进行通信,通过心跳信息发送指令并收集块服务器状态 。
GFS 客户端代码嵌入到应用中,实现了文件系统 API,代表客户端进行读写数据,与主节点和块服务器进行通信 。客户端与主节点进行元数据的交互操作,而与数据相关的通信则直接与块服务器进行 。
2.4 单一的主节点单一的主节点简化了我们的设计,令主节点能够根据整体信息确定块的位置,以及进行复制决策 。
由于主节点是单一的,我们必须最小化对主节点的读写操作,以保证它不会成为系统性能的瓶颈 。客户端不会通过主节点读写数据,而只会向主节点询问需要与哪些块服务器进行联系 。客户端会将主节点的答复缓存一段时间,并在后续直接和块服务器交互 。
文章插图
简单解释一下上图中的一个读操作交互 。
- 首先,使用固定的块大小,客户端将文件名和应用指定的字节便宜转换为文件块的索引 。
- 然后,它向主节点发送一个包含文件名和块索引的请求,主节点回复相应的块句柄和副本的位置 。客户端使用文件名和块索引作为 Key 缓存这条信息 。
经验总结扩展阅读
- google发送的通知在哪 谷歌发送的通知在哪里找
- JAVA的File对象
- Codeforces 1670 E. Hemose on the Tree
- 二 沁恒CH32V003: Ubuntu20.04 MRS和Makefile开发环境配置
- 驱动开发:内核监控FileObject文件回调
- 伤感英文句子带翻译 英文扎心短句大全
- 齐博X1-栏目的调用2
- Blazor组件自做十一 : File System Access 文件系统访问 组件
- How to get the return value of the setTimeout inner function in js All In One
- System.IO.FileSystemWatcher的坑















