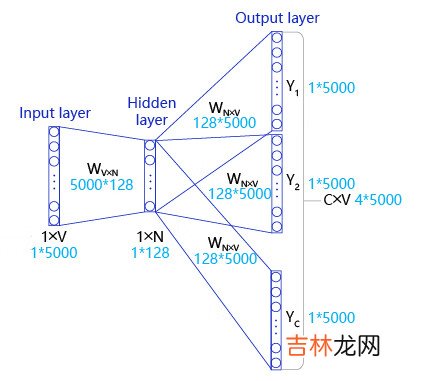
如 图6 所示,Skip-gram是一个具有3层结构的神经网络,分别是:
文章插图
- Input Layer(输入层):接收一个one-hot张量 $V \in R^{1 \times \text{vocab_size}}$ 作为网络的输入,里面存储着当前句子中心词的one-hot表示 。
- Hidden Layer(隐藏层):将张量$V$乘以一个word embedding张量$W_1 \in R^{\text{vocab_size} \times \text{embed_size}}$,并把结果作为隐藏层的输出,得到一个形状为$R^{1 \times \text{embed_size}}$的张量,里面存储着当前句子中心词的词向量 。
- Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量$W_2 \in R^{\text{embed_size} \times \text{vocab_size}}$,得到一个形状为$R^{1 \times \text{vocab_size}}$的张量 。这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果 。根据这个softmax的结果,我们就可以去训练词向量模型 。
2.1.1 Skip-gram的理想实现使用神经网络实现Skip-gram中,模型接收的输入应该有2个不同的tensor:
- 代表中心词的tensor:假设我们称之为center_words $V$,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每个中心词的ID,对应位置为1,其余为0 。
- 代表目标词的tensor:目标词是指需要推理出来的上下文词,假设我们称之为target_words $T$,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID 。
- 声明一个形状为[vocab_size, embedding_size]的张量,作为需要学习的词向量,记为$W_0$ 。对于给定的输入$V$,使用向量乘法,将$V$乘以$W_0$,这样就得到了一个形状为[batch_size, embedding_size]的张量,记为$H=V×W_0$ 。这个张量$H$就可以看成是经过词向量查表后的结果 。
- 声明另外一个需要学习的参数$W_1$,这个参数的形状为[embedding_size, vocab_size] 。将上一步得到的$H$去乘以$W_1$,得到一个新的tensor $O=H×W_1$,此时的$O$是一个形状为[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每个中心词预测出的目标词的概率 。
- 使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建 。
经验总结扩展阅读







- 米游社上传图片水印怎么关
- 苹果se3参数与图片_苹果se3参数详细配置
- 双叶h-单叶双曲面与双叶双曲面的图像区别
- 许褚怎么牺牲的(三国名将许褚之死)
- 红警尤里怎么玩(红警2共和国之辉尤里怎么玩)
- 怎么玩比较合适(休假去哪玩比较合适)
- 斗地主怎么玩(斗地主怎么记牌最轻松)
- 会玩怎么玩(会玩app低价买金币)
- CSS处理器-Less/Scss
- JUC学习笔记——进程与线程