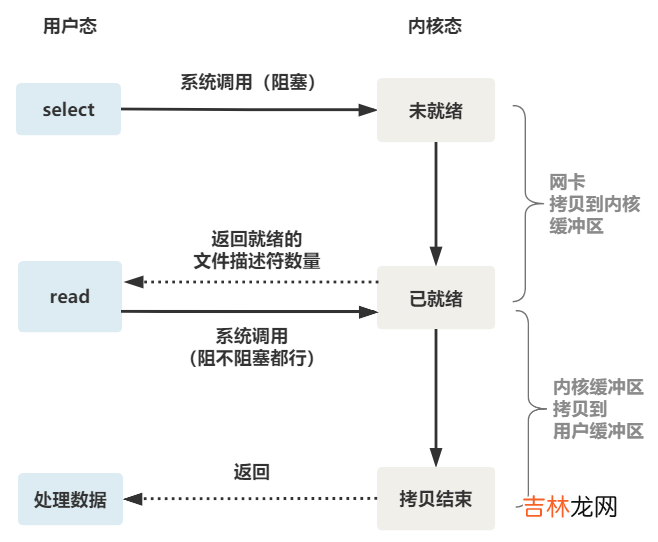
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的 。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销 。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历 。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
文章插图
可以看到,这种方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + n 次就绪状态的文件描述符的 read 系统调用) 。
epollepoll 是最终的大 boss,它解决了 select 和 poll 的一些问题 。
还记得上面说的 select 的三个细节么?epoll 主要就是针对这三点进行了改进 。
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可 。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒 。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合 。

文章插图
总结一下 。一切的开始,都起源于这个 read 函数是操作系统提供的,而且是阻塞的,我们叫它 阻塞 IO 。
为了破这个局,程序员在用户态通过多线程来防止主线程卡死 。
后来操作系统发现这个需求比较大,于是在操作系统层面提供了非阻塞的 read 函数,这样程序员就可以在一个线程内完成多个文件描述符的读取,这就是 非阻塞 IO 。
但多个文件描述符的读取就需要遍历,当高并发场景越来越多时,用户态遍历的文件描述符也越来越多,相当于在 while 循环里进行了越来越多的系统调用 。
后来操作系统又发现这个场景需求量较大,于是又在操作系统层面提供了这样的遍历文件描述符的机制,这就是 IO 多路复用 。
多路复用有三个函数,最开始是 select,然后又发明了 poll 解决了 select 文件描述符的限制,然后又发明了 epoll 解决 select 的三个不足 。
所以,IO 模型的演进,其实就是时代的变化,倒逼着操作系统将更多的功能加到自己的内核而已 。
如果你建立了这样的思维,很容易发现网上的一些错误 。
比如好多文章说,多路复用之所以效率高,是因为用一个线程就可以监控多个文件描述符 。
这显然是知其然而不知其所以然,多路复用产生的效果,完全可以由用户态去遍历文件描述符并调用其非阻塞的 read 函数实现 。而多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,变成了一次系统调用 + 内核层遍历这些文件描述符 。
就好比我们平时写业务代码,把原来 while 循环里调 http 接口进行批量,改成了让对方提供一个批量添加的 http 接口,然后我们一次 rpc 请求就完成了批量添加 。
经验总结扩展阅读











- iPhone8怎么刷机(苹果x强制恢复出厂)
- soul怎么找回之前聊天的人 soul恢复聊天列表方法
- 超人怎么死的(超人怎么复活)
- 廉租房一般几室一厅 廉租房享用的国家政策有哪些
- 一般蛋糕店用的是什么奶油
- 记一次多个Java Agent同时使用的类增强冲突问题及分析
- 光遇啵啵先祖裤子怎么搭配
- fastposter v2.10.0 简单易用的海报生成器
- 螺蛳粉要泡多久
- 羊毛衫缩水了有什么办法可以恢复