辛普森悖论告诉我们,数据不是绝对客观的 。想象一下,你和你的小伙伴正在努力寻找一个完美的餐厅,以便愉快的享用晚餐 。我们清楚这个过程可能会花费数小时去争论,你会找到现代生活的便利之处:在线评论 。通过在线评论,你找到了自己的选择,推荐 Carlo’s 餐厅的男女用户的比例都高于你的小伙伴选择的 Sophia’s 餐厅 。然而 , 正当你准备宣布胜利时,你的小伙伴使用相同的数据得到,由于所有用户中推荐选择 Sophia 的百分比较高,因此很明显要选择它 。
到底是怎么回事?谁在说谎?是审计网站的计算错误吗?事实上,你和你的小伙伴都是对的 , 你在不知不觉中进入了辛普森悖论的世界 。在辛普森悖论里,餐馆可以同时比竞争对手更好和更差,运动可以降低并增加疾病的风险,同样的数据集可以用来证明两个相反的论点 。也许你和你的伴侣应该在晚上讨论这个引人入胜的统计学现象,而不是出去吃饭 。
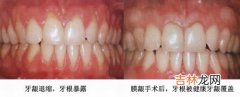
当原本分离的数据被组合起来,之前出现的统计现象会发生逆转,这时辛普森悖论就发生了 。在餐厅推荐示例中,就男女的高推荐率确实可以推荐 Carlo’s 而不是 Sophia’s , 且同时所有评价者对 Carlo’s 的推荐率较低 。在你说这不可能之前,请看看下表的证明 。
Carlo’s 在男女双方都获胜,但总体上输了!
数据清楚地表明:当数据分离时,Carlo’s 是首?。坏弊楹鲜莺?,Sophia’s 是首?。?
这怎么可能?这里的问题是,仅查看单独数据中的百分比会忽略样本大?。唇獯鹞侍獾氖芊谜呤?。每个分数都表示受访者中推荐餐厅的用户数量占比 。Carlo’s 餐厅的男性评论者远远多于女性,而 Sophia’s 则反过来 。由于男性推荐餐馆的比例较低,当组合数据时,这导致 Carlo’s 的平均评级较低,因此存在悖论 。
要解答我们应该去哪家餐馆的问题,我们需要决定数据是组合还是分离查看 。我们是否应该组合数据取决于生成数据的过程,即数据的因果模型 。在我们看完另一个例子后,我们将解释这是什么意思以及如何解决辛普森悖论 。
相关性逆转
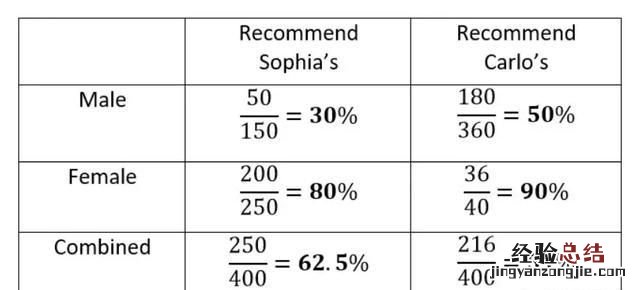
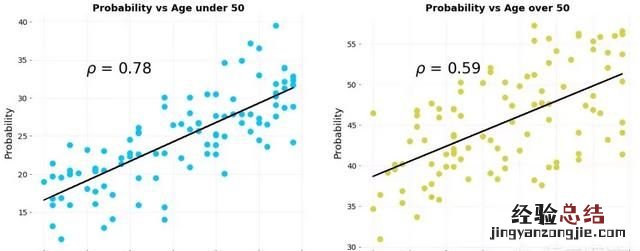
分组的数据点各自表现出某一个方向的相关性,在聚集时却表现出相反方向的相关性,这是辛普森悖论的另一个版本 。我们来看一个简化的例子 。假设我们有关于每周运动小时数与两组患者(50 岁以下和 50 岁以上患者)患病风险的数据 。以下是显示运动时间与患病概率之间关系的分离概率图 。
根据年龄分组的患病概率与每周运动小时数的关系图 。
我们清楚地看到负相关关系 , 表明每周运动水平的增加与两组患者发生疾病的风险降低相关 。现在,我们将数据组合在一起:
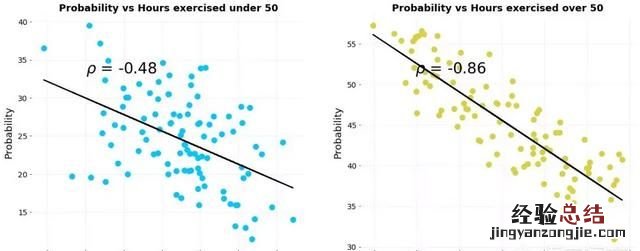
患病概率与运动概率的组合图 。
相关性完全逆转!如果只看这个数字,我们会得出结论,运动增加了患病的风险,这与我们从分离概率图中所看到的相反 。运动如何做到即减少又增加患病的风险?答案是它没有,而且要弄清楚如何解决悖论,我们需要透过数据看本质:什么造成了这个结果 。
解决悖论
为了避免辛普森悖论导致我们得出两个相反的结论,我们需要选择将数据分组或将它们聚合在一起 。这似乎很简单,但我们如何决定做哪个?答案是学会思考因果关系:数据如何生成 , 基于此,哪些因素会影响我们未展示的结果?
在运动与患病的例子中,我们直观地知道运动不是影响患病概率的唯一因素 。还有其他因素,如饮食、环境、遗传等 。但是,在上面的图中,我们只看到患病概率与运动时间的关系 。在我们的虚构例子中,我们假设疾病是由运动和年龄引起的 。这在以下的患病概率的因果模型中得以表现 。
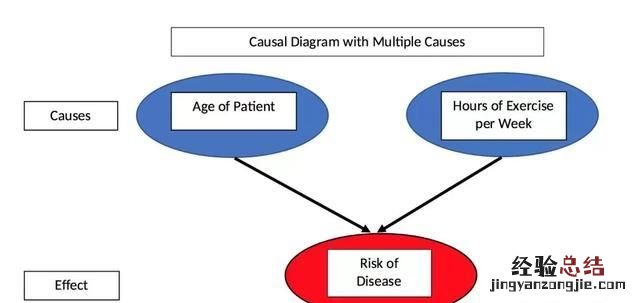
有两个诱因的患病概率的因果模型 。
在数据中,有两种不同的患病原因 , 但通过组合数据并仅查看患病概率与运动时间 , 我们完全忽略了第二个原因即年龄 。如果我们继续绘制患病概率与年龄的关系,我们可以看到患者的年龄与患病概率有强正相关 。
按年龄分组的患病概率与年龄的关系图 。
随着患者年龄的增加,她/他患病的风险增加 , 这意味着即使运动量一样,老年患者也比年轻患者更容易患病 。因此,为了公正地评估运动对疾病的影响,我们希望保持年龄不变仅改变每周运动量 。
将数据分组是实现这一目标的方式之一,通过这样做,我们可以看到:对于特定年龄组 , 运动可以降低患病的风险 。也就是说,保持患者年龄不变,运动会降低患病风险 。考虑到数据生成过程并应用因果模型,我们通过保持数据分组,控制变量来解决辛普森悖论 。
思考我们想要解答什么问题也可以帮助我们解决悖论 。在餐厅的例子中,我们想知道哪家餐厅最有可能满足我们和我们的小伙伴 。即使可能有其他因素影响评论而不仅仅是餐厅的质量 , 如果没有访问这些数据,我们希望将评论结合在一起并关注整体平均值 。在这种情况下 , 组合数据最有意义 。
在运动与患病风险实例中提出的相关问题是,我们应该参与更多运动 , 以减少我们个体患病的风险吗?由于我们是 50 多岁或不满 50 岁的人(对不起那些正好 50 岁的人),我们需要找出正确的群体,无论我们在哪个群体 , 我们都认为应该锻炼的更多 。
考虑数据生成过程和我们想要解答的问题不仅仅需要关注数据 。这说明了从辛普森悖论中学到的关键教训:仅有数据还不够 。数据绝不是纯粹客观的,特别是当我们只看到最终的图表时,我们必须考虑是否明白整个事件 。
我们可以尝试通过询问生成数据的原因以及未能展示的影响数据的因素来获得更完整的理解 。通常,答案表明我们实际上应该得出相反的结论!
现实生活中的辛普森悖论
这种现象并非像某些统计概念那样在理论上可行但在实践中从未发生作用 。事实上,在现实世界中有许多着名的辛普森悖论的研究案例 。
有一个关于两种肾结石治疗疗法的有效性的案例 。只看独立疗法的数据,疗法 A 对小肾结石和大肾结石的效果更好 , 但组合数据表明疗法 B 对两种病情的总效果更好!下表展示了恢复率:
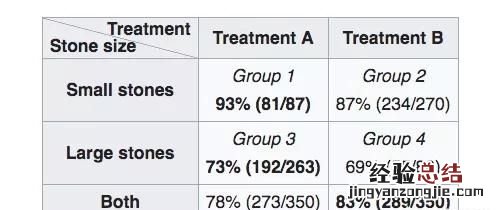
肾结石的疗法恢复率数据 。
怎么会这样?通过考虑由专业知识提供信息的数据生成过程 – 因果模型,可以解决此悖论 。事实证明,小肾结石被认为是不太严重的病例,疗法 A 比疗法 B 更加激进 。因此,对于小肾结石 , 医生更有可能推荐保守疗法 B,因为病情不太严重,患者最有可能首先成功恢复 。对于严重的大肾结石 , 医生往往选择更激进的疗法 A 。即使疗法 A 在这些病例中表现更好,由于它适用于更严重的病例,疗法 A 的总体恢复率低于疗法 B.
在这个现实世界的例子中,肾结石的大?。ú±难现匦裕┍怀莆旌媳淞? ,因为它影响自变量(疗法)和因变量(恢复时间) 。混合变量也是我们在数据表中看不到的东西,但它们可以通过绘制因果图来确定:
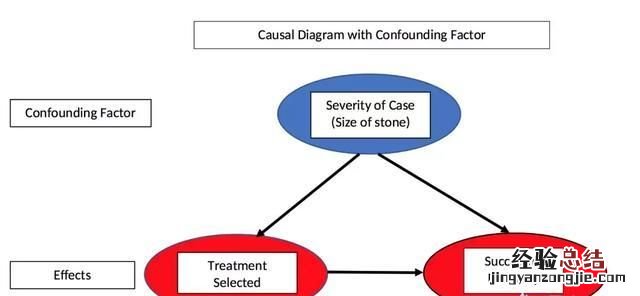
混合因素的因果图 。
问题中的效果即恢复,是由疗法和结石的大?。ú±难现匦裕┮鸬?。此外 , 取决于结石尺寸选择疗法使得尺寸成为一个混合变量 。为了确定哪种治疗方法确实更好 , 我们需要通过对两组数据进行分离并比较组内的恢复率而不是按组聚合来控制混合变量 。这样我们就得出结论 , 疗法 A 更好 。
这里有另一种思考问题的方式:如果你有一块小结石,你首选疗法 A;如果你有一块大结石,你也首选疗法 A 。既然你必然有一块结石 , 无论大?。?你总是首选疗法 A,悖论就解决了 。
证明一个论点及其反面
第二个现实生活中的例子展示了辛普森悖论如何被用来证明两个相反的政治观点 。下表显示,在杰拉尔德·福特担任总统期间 , 他不仅降低了每个群体收入的税收,同时从 1974 年到 1978 年在全国范围内提高税收 。看看数据:
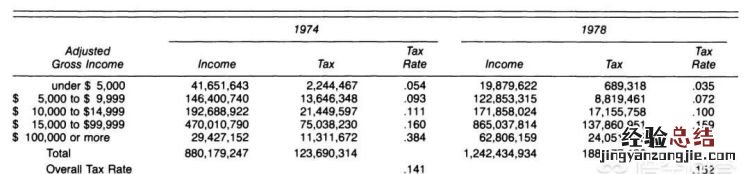
所有群体的个人税率均下降,但整体税率上升 。
我们可以清楚地看到 , 每个税级的税率从 1974 年至 1978 年有所下降,但整体税率在同一时期内有所增加 。我们现在知道如何解决悖论:寻找影响整体税率的其他因素 。总体税率受各个支柱税率以及每个税级中的应纳税收入的影响 。由于通货膨胀(或工资增长),高收入人群的总体收入增加且税率较高,低收入人群的总体收入减少且税率较低 。因此,整体税率上升 。
除了数据生成过程之外 , 我们是否应该组合数据取决于我们想要解答的问题(以及我们正在尝试塑造的政治论点) 。在个人层面上,我们只是独立的人,所以我们只关心自己的税率 。为了确定我们的税收在 1974 年到 1978 年是否上升,我们必须确定税级范围内的税率变化,以及我们是否转向了不同的税级 。有两个原因可以解释个人所得税 , 但在这一部分数据中只获取了一个原因 。
为什么辛普森悖论很重要
辛普森悖论很重要,因为它提醒我们,我们展示的数据并不是所有数据 。我们不能只满足于数字或图表,我们必须考虑数据生成过程 – 因果模型,对数据负责 。一旦我们理解了数据生成的机制,我们就可以寻找影响结果的其他因素,而图表不会告诉你这些 。学会思考因果关系并不是大多数数据科学家所教授的技能 , 但是对于防止我们从数字中得出错误的结论至关重要 。除了数据之外,我们还可以利用我们的经验和领域知识(或者该领域的专家)来做出更好的决策 。
而且,虽然我们的直觉通常很准确,但在没有立即获得所有信息的情况下 , 它们可能会出错 。我们倾向于关注我们面前的事物(所看即所得),而不是深入挖掘并使用我们理性、缓慢的思维模式 。特别是当有人要销售产品或实施议程时,我们必须对这些数字持怀疑态度 。数据是一种强大的武器,但是想要帮助我们的人和邪恶的骗子都可以使用它 。
【辛普森悖论如何用同一数据】
辛普森悖论是一个有趣的统计现象,但它也证明了对数据操控的最佳防卫是理性思考和质疑的能力 。