#output aabbccddaNaNNaNNaNNaNb4.05.06.07.0c8.09.010.011.0d12.013.014.015.0print (df.dropna(axis=1,how="all"))#0行1列#output 并没有发生变化,因为过滤的是列,要求一列全都是NaN值#outputaabbccddaNaNNaNNaNNaNb4.05.06.07.0c8.09.010.011.0d12.013.014.015.0df.dropna(axis=0,how="all")#0行1列#outputaabbccddb4.05.06.07.0c8.09.010.011.0d12.013.014.015.0(3)填充缺失值因为数据处理的要求,可能并不需要将所有的数据进行过滤,此时需要对数据进行必要的填充(比如0.0);还可以用线性插值进行必要的填充,而在这个数据处理中需要用到的方式如下所示:
df=pd.DataFrame(np.arange(16).reshape((4,4)),columns=["aa","bb","cc","dd"],index = ["a","b","c","d"])dfdf.loc[:1,:] = np.nanprint (df)#output aabbccddaNaNNaNNaNNaNb4.05.06.07.0c8.09.010.011.0d12.013.014.015.0print (df.fillna(0.0)) #fillna 默认会返回新的对象#output aabbccdda0.00.00.00.0b4.05.06.07.0c8.09.010.011.0d12.013.014.015.0#也可以像dropna 操作一样进行必要的限定而不是所有的值都进行填充#print df.fillna({1:0.5,2:5.5)#测试失败#当需要在旧的对象上进行更改,而不是经过过滤返回一个新的对象时df.fillna(0.5,inplace = True)df#outputaabbccdda0.50.50.50.5b4.05.06.07.0c8.09.010.011.0d12.013.014.015.0#也可以选择一些线性插值进行填充df.loc[:1,:] = np.nandf.fillna(method ="bfill")#后向寻值填充#outputaabbccdda4.05.06.07.0b4.05.06.07.0c8.09.010.011.0d12.013.014.015.0df.fillna(df.mean())#使用平均值进行填充#outputaabbccdda8.09.010.011.0b4.05.06.07.0c8.09.010.011.0d12.013.014.015.0另外,在处理缺失值时除了以上介绍的简单操作之外,更多的时候需要根据数据挖掘需要或者程序运行方面灵活地进行缺失值处理,程序是人为设定的规则,但针对这些规则进行优化组合,将会带来新的效果
3.数据库的使用关于数据库的使用,虽然各大厂商都在追捧NOSQL,但是目前使用最多的还是关系型数据库(MySQL、SQLServer、PostgreSql等) 。总体而言,数据库的选择取决于其性能、数据完整性及应用程序的需求等 。在这里我们使用python内置的sqlite3驱动器,操作过程如下所示:
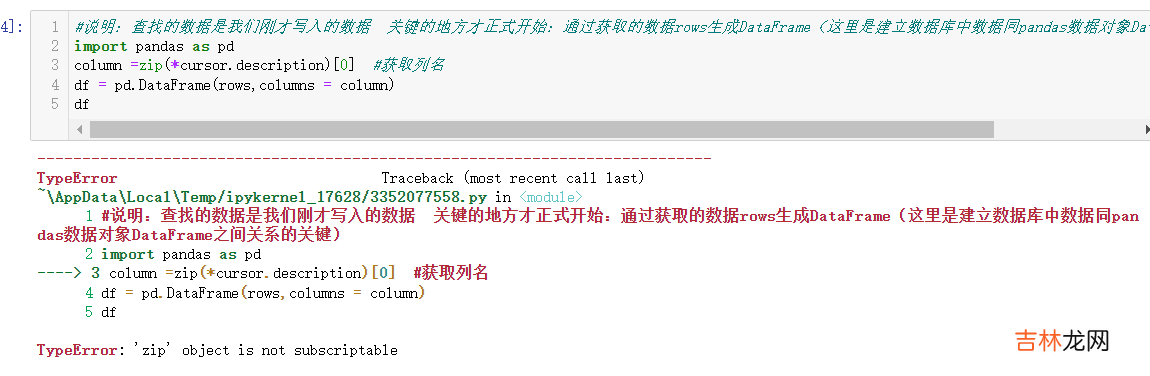
#sql MySqlimport sqlite3 as sql#首先我们需要导入sqlite3包#现在我们使用的是python内置的数据库#创建数据库表(table)query = "create table test(a varchar(20),b varchar(20),c real,d integer);"con = sql.connect(":memory:")#可以看出它是内置数据库而且此处又使用memory#因此它的处理是放在内存进行处理的内置操作con.execute(query)con.commit()#对刚才创建的test表写入数据#insert datadata = https://www.huyubaike.com/biancheng/[("UCAS","NSLCAS",0.5,1),("UCAS","NSLCAS",0.5,2),("UCAS","NSLCAS",0.5,3),("UCAS","NSLCAS",0.5,4)]stmt="insert into test values(?,?,?,?)"con.executemany(stmt,data)#多行方式写入,如果单行模式用con.executecon.commit#查找数据#select datasql_str="select*from test"cursor=con.execute(sql_str)rows=cursor.fetchall()rows#output[('UCAS', 'NSLCAS', 0.5, 1), ('UCAS', 'NSLCAS', 0.5, 2), ('UCAS', 'NSLCAS', 0.5, 3), ('UCAS', 'NSLCAS', 0.5, 4)]#说明:查找的数据是我们刚才写入的数据关键的地方才正式开始:通过获取的数据rows生成DataFrame(这里是建立数据库中数据同pandas数据对象DataFrame之间关系的关键)import pandas as pdcolumn =list(zip(*cursor.description))[0]#获取列名df = pd.DataFrame(rows,columns = column)df#书本上写的是:column = zip(*cursor.description)[0]
文章插图
#错误:'zip' object is not subscriptable#解决办法:使用list包装zip对象#代码:column =list(zip(*cursor.description))[0]#注意[0]是在list的括号()外
#outputabcd0UCASNSLCAS0.511UCASNSLCAS0.522UCASNSLCAS0.533UCASNSLCAS0.54优化:之前的操作看似简单流畅,但是针对具体应用来看不是很理想,原因在于我们需要对数据库的每次操作进行代码的重写,这样既耗时又耗力,庆幸的是pandas提供了一组方法帮我们解决类似难题 。
经验总结扩展阅读









- 哪些国家开展了黄粉虫的研究利用
- 羊肉有味了怎么处理
- 脸上长痘痘怎么处理
- 粘鼠板粘住老鼠怎么处理
- 荣耀v50搭载什么处理器_荣耀v50处理器性能介绍
- 骁龙480相当于麒麟多少_高通骁龙480相当于什么处理器
- 公司重组员工如何处理
- 家里进水了怎么快速处理
- 关于动物的伤口怎么处理
- 净水机制水慢咋样处理