4. HashMap容量大小为什么要设置成2的倍数?int index = hash(key) & (n-1);为了更快的计算key所在的数组下标位置 。
当数组长度(n)是2的倍数的时候,就可以直接通过逻辑与运算(&)计算下标位置,比取模速度更快 。
5. HashMap为什么是线程不安全?原因就是HashMap的所有修改方法都没有加锁,导致在多线程情况下,无法保证数据一致性和安全性 。
比如:一个线程删除了一个key,由于没有加锁,其他线程无法及时感知到,还继续能查到这个key,无法保证数据的一致性 。
比如:一个线程添加完一个元素,由于没有加锁,其他线程无法及时感知到,另一个线程正在扩容,扩容后就把上一个线程添加的元素弄丢了,无法保证数据的安全性 。
6. 解决哈希冲突方法有哪些?常见有链地址法、线性探测法、再哈希法等 。
- 链地址法
就是把发生哈希冲突的值组成一个链表,HashMap就是采用的这种 。
- 线性探测法
发生哈希冲突后,就继续向下遍历,直到找到空闲的位置,ThreadLocal就是采用的这种,以后再详细讲 。
- 再哈希法
使用一种哈希算法发生了冲突,就换一种哈希算法,直到不冲突为止(就是这么聪明) 。
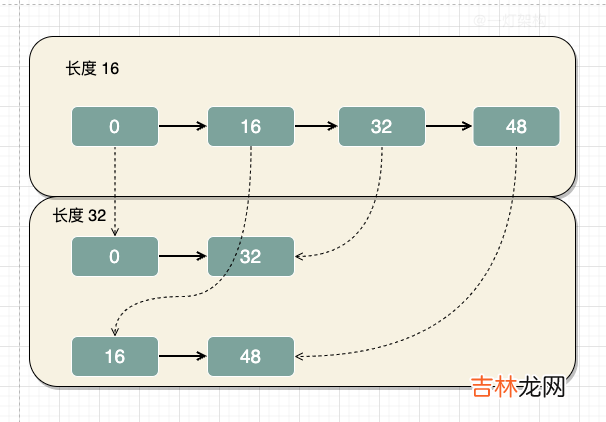
在JDK1.8扩容的时候,会遍历原数组,然后统计出两组数据,一组是新数组的下标位置不变,另一组是新数组的下标位置等于原数组的下标位置加上原数组的长度 。
比如:数组长度由16扩容到32,哈希值是0和32的元素,在新旧数组中下标位置不变,都是下标为0的位置 。而哈希值是16和48的元素,在新数组的位置=原数组的下标+原数组的长度,也就是下标为16的位置 。
文章插图

文章插图
经验总结扩展阅读








- C++和Java多维数组声明和初始化时的区别与常见问题
- 放置江湖最佳初始属性
- NIKKE胜利女神初始角色选什么
- NIKKE胜利女神怎么刷初始
- 原神怎么刷初始号
- HashMap底层原理及jdk1.8源码解读
- C++自学笔记 初始化列表 Initializer list
- 行李箱密码怎么重置
- 张家辉哪部电影说耶稣也救不了你我说的?
- 删了让我说是什么意思?