dedup() , 其还支持key参数 , 类似sorted()中的同名参数 , 实现自定义去重规则:
([-1, 0, 0, 0, 1, 2, 3] |pipe.dedup |Pipe(list))([-1, 0, 0, 0, 1, 2, 3] |# 基于每个元素的绝对值进行去重pipe.dedup(key=abs) |Pipe(list))

文章插图
2.1.3 使用filter()进行值过滤我们最开始的例子中使用过它 , 用法就是基于传入的
lambda函数对每个元素进行条件判断 , 并保留结果为True的 , 与javascript中的filter()方法非常相似:([1, 4, 3, 2, 5, 6, 8] |# 保留大于5的元素pipe.filter(lambda x: x > 5) |Pipe(list))
文章插图
2.1.4 使用groupby()进行分组运算这个函数非常实用 , 其功能相当于管道操作版本的
itertools.groupby() , 可以帮助我们基于lambda函数运算结果对原始输入数组进行分组 , 通过groupby()操作后直接得到的结果是分组结果的二元组列表 , 每个元组的第一个元素是分组标签 , 第二个元素是分到该组内的各个元素:
文章插图
基于此 , 我们可以衔接很多其他管道操作函数 , 譬如衔接
select()对分组结果进行自定义运算:
文章插图
2.1.5 使用select()对上一步结果进行自定义遍历运算这个函数是
pipe()中核心的管道操作函数 , 通过前面的若干例子也能弄明白 , 它的功能是基于我们自定义的函数 , 对上一步的运算结果进行遍历运算 。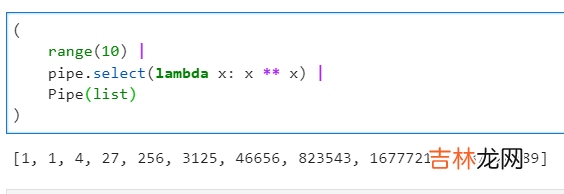
文章插图
2.1.6 使用sort()进行排序相当于内置函数
sorted()的管道操作版本 , 同样支持key、reverse参数: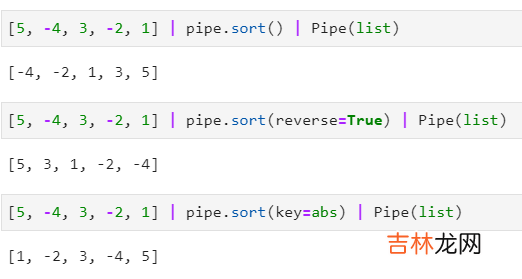
文章插图
上述内容足以支撑大部分日常操作需求 , 你也可以在
https://github.com/JulienPalard/Pipe中查看pipe的更多功能介绍 。以上就是本文的全部内容 , 欢迎在评论区与我进行讨论~
经验总结扩展阅读











- Java学习之路:流程控制
- 不会游泳的人如何自学游泳(一般人如何学习游泳)
- 达梦dba_segments指定表名查询到的大小都包含哪些数据
- Springboot 之 Filter 实现超大响应 JSON 数据压缩
- PHP Phar反序列化学习
- python基础--简单数据类型预览
- python基础-较复杂数据类型预览
- 【软件学习】怎么在Word里面设置MathType分隔符,使公式按照章节自动编号
- SpringBoot 自定义注解 实现多数据源
- CRESDA 陆地观测卫星数据服务订单ftp地址错误—已解决不能下载问题