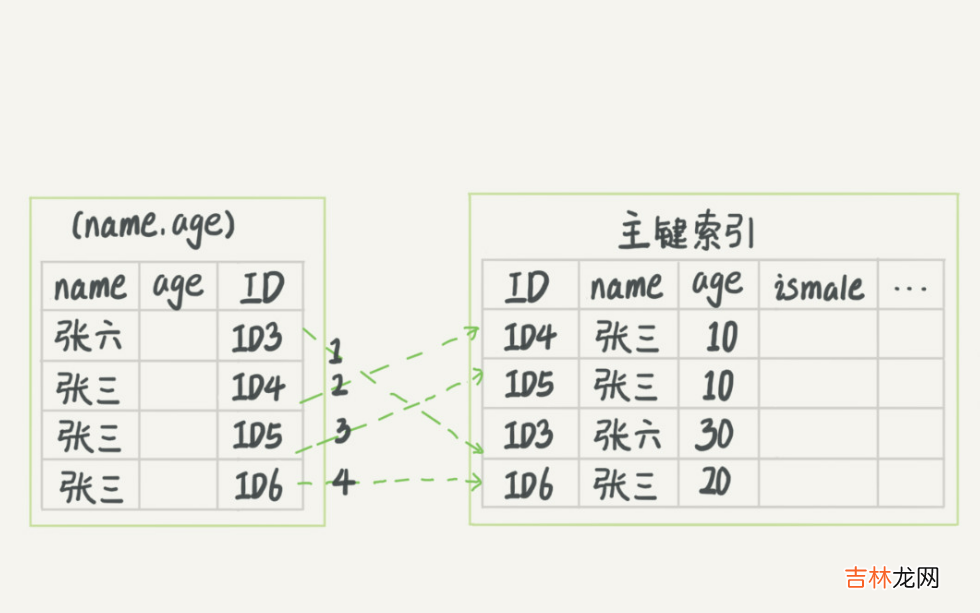
select * from table where age=1这时候先走age索引(如果数据量较大,数据量少直接全表扫描了)那么会找到对应的主键id,继续到主键id索引中找到目标数据,这个操作叫做回表 。
这就是为什么根据主键查找快于根据其他索引列查找,因为如果其他索引列没有包含我们select语句中需要的列(如果是select id from table where age<10,那么age索引是可以覆盖到需要的数据的(叶子节点存储了id),那么也不会回表),那么会走主键索引拿到需要的数据,多了一步回表操作 。
这里我们也可以看到为什么建议使用select * ,这意味着查找所有列,如果配合上普通索引,那么大概率这个普通索引不会覆盖到索引列,导致需要回表查询 。并且select*这种"我全都要"大概率会查询到我们不需要的列,造成不必要的网络资源消耗,增加不必要的io,增加不必要的内存消耗 。
五丶联合索引

文章插图

文章插图
联合索引是指对表上的多个列建立索引,如上图表存在四个字段
id,address,name,age,我们在name和age上建立索引,上图我们粗略的展示了联合索引的B+树结构 。我们可以观察到在叶子节点中name是有序的,但是age无序,联合索引是按照索引定义的顺序排序的,这就导致select xxx from table where name='b'是可以根据上面定义的联合索引查找数据的,但是``select xxx from table where age=12是无法走上面定义的联合索引的 。这就是常说的最左前缀匹配原则`的原理 。- 联合索引可以减少回表
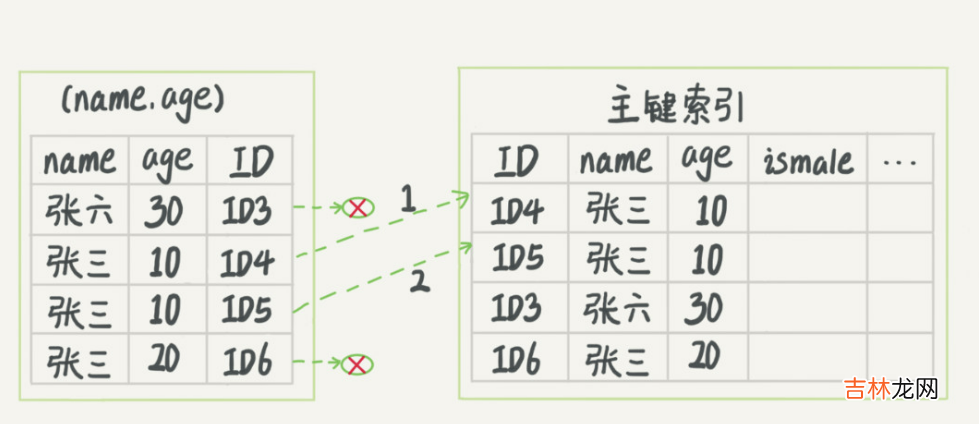
如果我们执行select age,id from table where name='a' and age=10,这个时候由于我们定义的聚集索引一级包含了需要的数据就不需要进行回表操作了(这其实也被称为覆盖索引,即非聚集索引中可以查询到全部需要的列,那么就不需要走聚集索引回表查询数据)
- 联合索引可以优化排序
上图中的联合索引,我们可以看到,名称相同的节点,其年龄是有序的
也就是说select * from table where name='a' order by age这个语句将避免多一次的排序操作(select* from table where id=1 order by age会走主键索引拿到所有符合数据进行排序,这里说的避免一次排序操作指拿到的数据本身就是有序的 所有不需要再次排序)
- 索引下推ICP
全称Index Condition PushDown,mysql 5.6后支持的一种根据索引进行查询优化的操作 。mysql数据库会在取出所有数据的同时判断是否进行where条件的过滤,将where的部分过滤放在存储引擎层 。
文章插图
mysql5.6之前如果执行select * from table where name like '张%' and age=10这时候会先从name age的联合索引中拿到name满足张开头的数据,然后回表,mysql支持ICP后,效果图如下
文章插图
mysql会根据联合索引中记录的age对数据进行过滤,这时候age不等于10的数据将不会回表,将回表次数从4优化到了2,这就是索引下推 。
- 如何安排联合索引的顺序
第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的,比如业务中存在两个高频查询,根据name,以及根据name查询后根据age排序,这个时候我们应该建立经验总结扩展阅读
- 十二星座喜欢通过什么小细节秀恩爱
- 新房装修验收注意哪些细节
- 用golang开发系统软件的一些细节
- 记一次批量更新整型类型的列 → 探究 UPDATE 的使用细节
- 火影忍者究极风暴怎么调整画质
- 发朋友圈的七种步骤(发朋友圈的细节和技巧)
- 库克首次回应iPhone13的细节_iphone13官方最新消息
- 上官婉儿怎么免伤害连招(上官婉儿怎么玩连招细节)
- 电视剧忠者无敌演员表介绍?
- 丑女无敌结局是什么?