哪为什么不使用跳表来做索引昵?
跳表是链表结构,一条数据一个结点,如果最底层要存放2kw数据,且每次查询都要能达到二分查找的效果,2kw大概在2的24次方左右,所以,跳表大概高度在24层左右 。最坏情况下,这24层数据会分散在不同的数据页里,也即是查一次数据会经历24次磁盘IO 。
【究极无敌细节版 Mysql索引】

文章插图
4.平衡二叉搜索树二叉搜索树,即左子树小于根,根小于右子树,这种结构在查找的时候可以进行二分,根据根节点的值就可以确定期望的数据在左树还是右树 。

文章插图
但是二叉搜索树在插入,删除节点的时候可能出现树极度不平衡的情况,出现树退化成链表 。
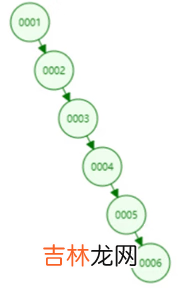
文章插图
这个时候就需要维持树的平衡——AVL:在满足二叉搜索树的条件下,要求任何节点的两个子树高度差不超过1 。平衡二叉树的查找是趋近于O(log(N)),但是需要维护一颗树为AVL需要进行左旋,右旋的操作,更新的时间复杂度也是 O(log(N)) 。
为什么不使用AVL做索引:节点存储的数据内容太少 。因为操作系统和磁盘之间一次数据交换是以页为单位的,一页 = 4K,即每次IO操作系统会将4K数据加载进内存 。但是,在二叉树每个节点的结构只保存一个关键字,一个数据区,两个子节点的引用,并不能够填满4K的内容 。幸幸苦苦做了一次的IO操作,却只加载了一个关键字,在树的高度很高,恰好又搜索的关键字位于叶子节点或者支节点的时候,取一个关键字要做很多次的IO 。
5.B-树,B+树B-树就是B树,英文是B-Tree,所以国内有许多人称之为B-树 。B树和B+树是多路平衡查找树,之所以
多路,是为了契合磁盘的io操作——操作系统和磁盘之间一次数据交换是以页为单位的,多路能让读取一页能获取更多的数据,让树的高度更低 。
文章插图

文章插图
上面两图,我们可以看出B树和B+树的区别
- B+树叶子节点使用双向指针串联起来,这让B+树相比于B树更加适合范围查找
- B+树非叶子节点并不存数据,所以每次查找数据都必须遍历到叶子节点,时间复杂度稳定为O(logN),B-树在运气好的时候可以在根节点直接拿到数据 。但是正是因为非叶子节点不存储数据,可以让一次磁盘读取一页中包含的索引数据更多,每个节点能索引的范围更大更精确,让我们可以更改定位到期望的数据 。由于B+树的叶子节点的数据都是使用链表连接起来的,而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快
三丶InnoDB索引方案1.InnoDB行结构InnoDB存储引擎存储一行数据使用的数据结构称为行结构 。