跳跃表 ( skiplist ) 是一种有序数据结构,自动去重的集合数据类型,ZSet数据结构底层实现为字典(dict) + 跳表(skiplist) 。它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的 。支持平均O ( logN ) 、最坏 O(N) 复杂度的节点查找,还可以通过顺序性操作来批量处理节点 。
数据比较少时,用ziplist编码结构存储,包含的元素数量比较多,又或者有序集合中元素的成员(member) 是比较长的字符串时,Redis 就会使用跳跃表来作为有序集合键的底层实现 。
元素个数超过128,将用skiplist编码zset-max-ziplist-entries 128
单个元素大小超过64 byte,将用skiplist编码zset-max-ziplist-value 64
5.1 跳跃表zset结构如下:
typedef struct zset {// 字典,存储数据元素dict *dict;// 跳跃表,实现范围查找zskiplist *zsl;} zset;robj *createZsetObject(void) {// 分配空间zset *zs = zmalloc(sizeof(*zs));robj *o;// dict用来查询数据到分数的对应关系,zscore可以直接根据元素拿到分值zs->dict = dictCreate(&zsetDictType,NULL);// 创建skiplistzs->zsl = zslCreate();o = createObject(OBJ_ZSET,zs);o->encoding = OBJ_ENCODING_SKIPLIST;return o;}zskiplist
typedef struct zskiplist {// 头、尾节点;头节点不存储元素,拥有最高层高struct zskiplistNode *header, *tail;unsigned long length;// 层级,所有节点中的最高层高int level;} zskiplist;typedef struct zskiplistNode {// 元素member值sds ele;// 分值double score;// 后退指针struct zskiplistNode *backward;// 节点中用 L1、L2、L3 等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推 。struct zskiplistLevel {// 指向本层下一个节点,尾节点指向nullstruct zskiplistNode *forward;// *forward指向的节点与本节点之间的元素个数,span值越大,跳过的节点个数越多unsigned long span;} level[];} zskiplistNode;结构图如下:
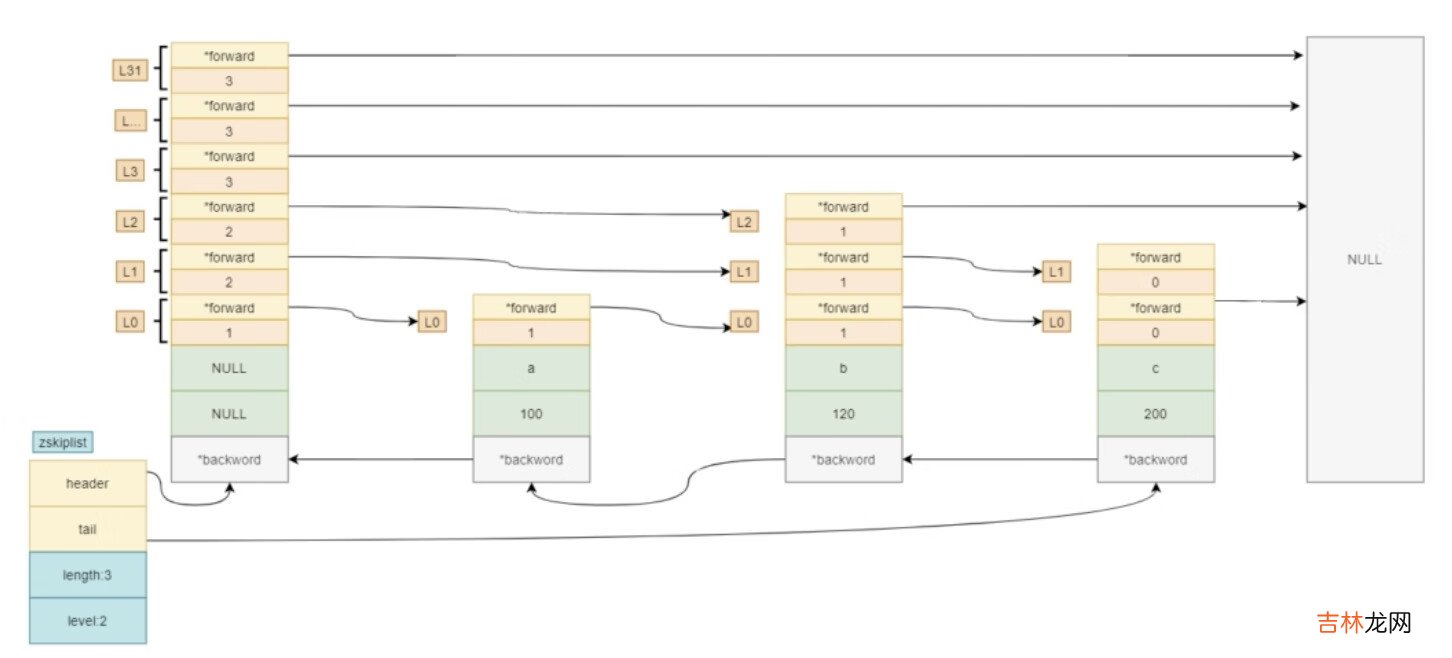
文章插图
5.2 创建节点及插入流程SkipList初始化,创建一个有最高层级的空节点:
zskiplist *zslCreate(void) {int j;zskiplist *zsl;// 分配空间zsl = zmalloc(sizeof(*zsl));// 设置起始层次zsl->level = 1;// 元素个数zsl->length = 0;// 初始化表头,表头不存储元素,拥有最高的层级zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);// 初始化层高for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {zsl->header->level[j].forward = NULL;zsl->header->level[j].span = 0;}// 设置表头后退指针为NULLzsl->header->backward = NULL;// 初始表尾为NULLzsl->tail = NULL;return zsl;}新增元素:zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));x = zsl->header;// 遍历所有层高,寻找插入点:高位 -> 低位for (i = zsl->level-1; i >= 0; i--) {// 存储排位,便于更新rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];while (x->level[i].forward &&// 找到第一个比新分值大的节点,前面一个位置即是插入点(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&// 相同分值则按字典顺序排序sdscmp(x->level[i].forward->ele,ele) < 0))){// 累加跨度rank[i] += x->level[i].span;x = x->level[i].forward;}// 每一层的拐点update[i] = x;}// 随机生成层高,以25%的概率决定是否出现下一层,越高的层出现概率越低level = zslRandomLevel();// 随机层高大于当前的最大层高,则初始化新的层高if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}// 创建新的节点x = zslCreateNode(level,score,ele);for (i = 0; i < level; i++) {// 插入新节点,将新节点的当前层前指针更新为被修改节点的前指针x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;// 新节点跨度为后一节点的跨度 - 两个节点之间的跨度x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}// 新节点加入,更新顶层 spanfor (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}// 更新后退指针和尾指针x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;zsl->length++;return x}
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 2023年2月2日是灌溉吉日吗 2023年农历正月十二灌溉吉日
- 2023年农历正月十二池塘放水吉日 2023年2月2日池塘放水吉日一览表
- 2023年农历正月十二种树吉日 2023年2月2日是种树的黄道吉日吗
- 2023年2月2日种花草行吗 2023年农历正月十二种花草吉日
- 2023年农历正月十二打农药吉日 2023年2月2日打农药好吗
- 王姓女孩名字两个字 姓王的女孩名字唯美二个字
- 2023年农历正月十二宜立牌匾吗 2023年农历正月十二立牌匾吉日
- 2023年农历正月十二宜买猫吗 2023年2月2日适合买猫吗
- 独一无二美甲店名字 美甲店起名大全免费取名
- 2023年农历正月十二买鱼吉日 2023年2月2日买鱼好吗
















