1.概念从若学习算法出发,反复学恶习得到一系列弱分类器(又称基本分类器),然后组合这些弱分类器构成一个强分类器 。简单说就是假如有一堆数据data,不管是采用逻辑回归还是SVM算法对当前数据集通过分类器data进行分类,假如一些数据经过第一个分类器之后发现是对的,而另一堆数据经过第一个分类器之后发现数据分类错了,在进行下一轮之前就可以对这些数据进行修改权值的操作,就是对上一轮分类对的数据的权值减小,上一轮分类错的数据的权值增大 。最后经过n个分类器分类之后就可以得到一个结果集
注意:adaboost算法主要用于二分类问题,对于多分类问题,adaboost算法效率在大多数情况下就不如随机森林和决策树
要解决的问题:如何将弱分类器(如上描述每次分类经过的每个分类器都是一个弱分类器)组合成一个强分类器:加大分类误差小的瑞分类权值减小分类误差大的弱分类器权值

文章插图
1.1举例分析

文章插图

文章插图

文章插图

文章插图
2.决策树,随机森林,adaboost算法比较以乳腺癌为例来比较三种算法
2.1 加载数据
#使用train_test_split将数据集拆分from sklearn.model_selection import train_test_split#将乳腺癌的数据导入,return这个参数是指导入的只有乳腺癌的数据#如果没有参数,那么导入的就是一个字典,且里面有每个参数的含义X,y=datasets.load_breast_cancer(return_X_y=True)#测试数据保留整个数据集的20%X_train,X_test,y_train,y_test = train_test_split(X,y,test_size= 0.2)2.2使用决策树score=0for i in range(100):model=DecisionTreeClassifier()#将训练集数据及类别放入模型中model.fit(X_train,y_train)y_ =model.predict(X_test)#预测测试集里的数据类型score+=accuracy_score(y_test,y_)/100print("多次执行,决策树准确率是:",score)运行结果
文章插图
2.3随机森林
score=0for i in range(100):#随机森林的两种随机性:一种是随机抽样,另一种是属性的随机获取 。而决策树只有随机抽样一种随机性model=RandomForestClassifier()#将训练集数据及类别放入模型中model.fit(X_train,y_train)y_ =model.predict(X_test)#预测测试集里的数据类型score+=accuracy_score(y_test,y_)/100print("多次执行,随机森林的准确率为是:",score)
文章插图
2.4adaboost自适应提升算法
score=0for i in range(100):model=AdaBoostClassifier()#将训练集数据及类别放入模型中model.fit(X_train,y_train)y_ =model.predict(X_test)#预测测试集里的数据类型score += accuracy_score(y_test,y_)/100print("多次执行,adaboost准确率是:",score)
文章插图
3.手撕算法
文章插图
adaboost三轮计算结果在代码中的体现就是X[i]的值
import numpy as npfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import treeimport graphvizX=np.arange(10).reshape(-1,1)#二维,机器学习要求数据必须是二维的y=np.array([1,1,1,-1,-1,-1,1,1,1,-1])display(X,y)display(X,y)运行结果如下图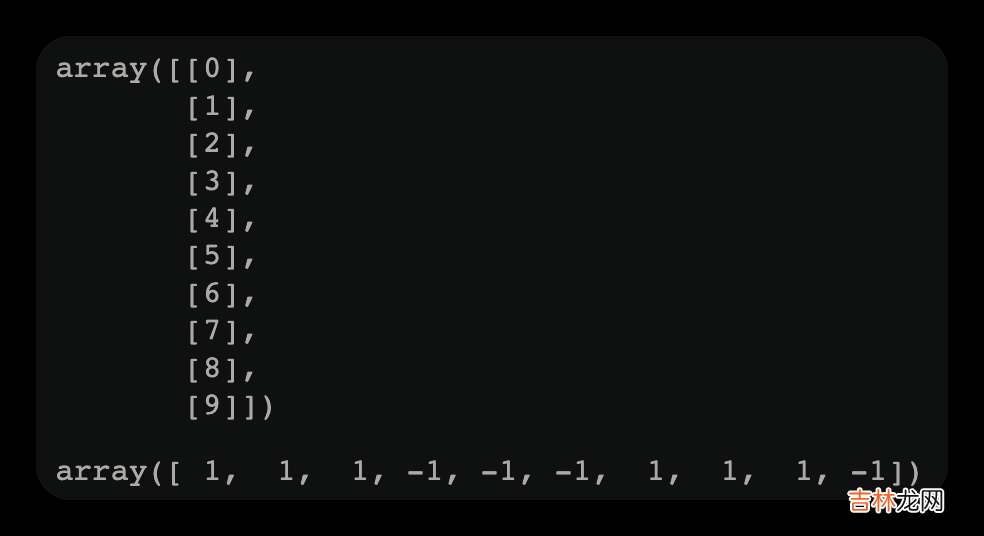
经验总结扩展阅读











- 2023年农历正月十二安机器吉日 2023年2月2日安机器行吗
- 2023年2月2日安装机器黄道吉日 2023年2月2日安装机器行吗
- 2023圣诞节祝福语情侣浪漫话语
- 平安夜暖心的祝福语2023
- 送领导平安夜祝福语2023
- 感恩节的祝福语通用15篇
- 儿童感恩节祝福语2篇
- 感恩节简短独特祝福语优秀
- 感恩节送给长辈祝福语
- 感恩节经典祝福句子优秀