摘要:T+0查询是指实时数据查询,数据查询统计时将涉及到最新产生的数据 。本文分享自华为云社区《大数据解决方案:解决T+0问题》,作者: 小虚竹。
T+0问题T+0查询是指实时数据查询,数据查询统计时将涉及到最新产生的数据 。在数据量不大时,T+0很容易完成,直接基于生产数据库查询就可以了 。但是,当数据量积累到一定程度时,在生产库中进行大数据量的查询会消耗过多的数据库资源,严重时会影响交易业务,这就不能接受了,毕竟生产交易是更关键的任务 。所以,我们常常会把大量用于查询分析的历史数据从生产库中分离出去,使用单独的数据库存储和查询,以保证查询统计不会影响生产业务,这就是常说的冷热数据分离 。
数据分离后就会产生T+0问题 。数据拆分到两个数据库中,要查询全量数据就涉及跨库查询 。而且,我们知道,用于交易的生产库大多使用能够保证事务一致性的RDB,而分离出来的冷数据(量大且不再修改)则会更多使用专门的分析型数据库或数据平台存储,即使是关系数据库也很可能与原来的生产库类型不同,这就不仅涉及跨库,还需要跨异构库(源)查询 。遗憾的是,当前实现跨库查询的技术都存在这样那样的问题 。
数据库自身的跨库查询功能(如Oracle的DBLink、MySQL的FEDERATED、MSSQL的Linked Server等)通常是将远程数据库的数据拉到本地,再在本地完成包括过滤在内的大部分计算,整个过程十分低效 。不仅如此,这种方式还存在数据传输不稳定、不支持大对象操作、可扩展性低等很多不足 。
除了数据库自身的跨库查询能力,使用高级语言硬编码也可以完成跨库查询,毕竟没有什么问题不是硬编码解决不了的 。这种方式虽然灵活,但使用难度却很大,尤其对于当前大部分应用的开发语言Java来说,缺少足够的结构化数据计算类库使得完成跨库查询后的计算很难完成,通常只能做简单的列表式查询,而涉及到统计汇总类的运算就会异常麻烦 。
事实上,要解决分库后的T+0查询问题也并非难事,只要有具备这样一些能力的计算引擎就可以实现:能够对接多种数据源;拥有不依赖数据库的完善计算能力以完成多库数据归集后的数据计算工作;还可以利用数据库(源)的能力充分发挥数据库的效能;提供简单的数据计算接口;性能相对理想等 。
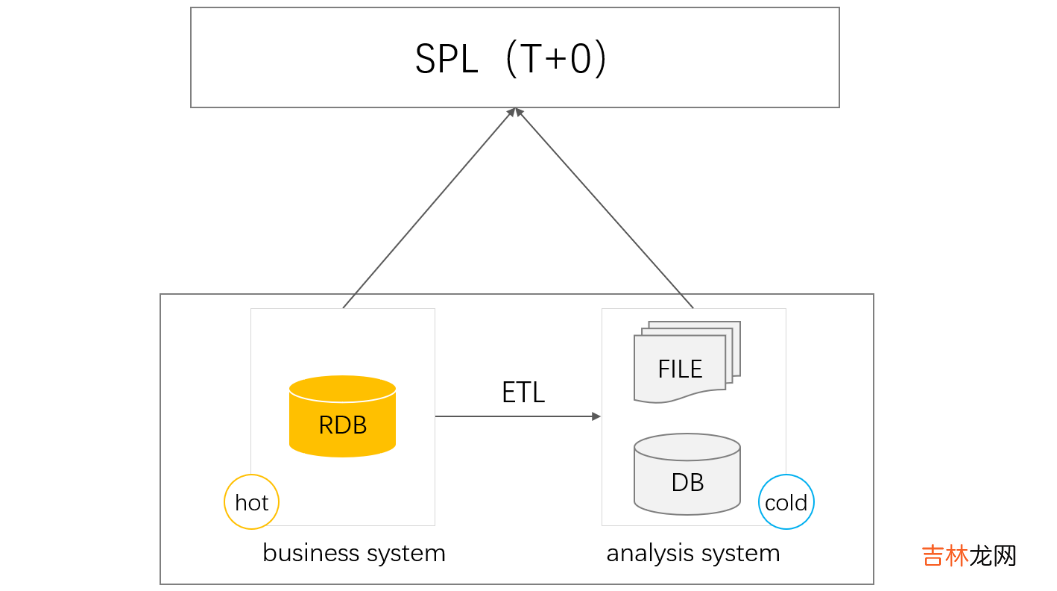
引入SPL可以借助开源SPL可以实现这些目标 。SPL是一款开源数据计算引擎,提供了大量结构化数据计算函数并拥有完备计算能力,支持多数据源混合计算,可以同时连接存储热数据的业务库和存储冷数据的历史库完成全量数据T+0查询 。
文章插图
由于具备独立且完善的计算能力,SPL可以分别从不同的数据库取数计算,因此可以很好适应异构数据库的情况,还可以根据数据库的资源状况决定计算是在数据库还是SPL中实施,非常灵活 。在计算实现上,SPL的敏捷语法与过程计算可以大大简化T+0查询中的复杂计算,提升开发效率,SPL解释执行支持热部署 。更进一步,依托SPL的强计算能力还可以完成冷热数据分离时的ETL任务 。
SPL还提供了自有的高性能二进制文件存储,对性能要求较高时可以将历史冷数据使用文件存储,再借助SPL的高性能算法与并行计算来提升查询效率 。此外,SPL封装了标准应用接口(JDBC/ODBC/RESTful)供应用集成调用,也可以将SPL嵌入应用中使用,这样应用就轻松具备了T+0查询与复杂数据处理能力,将计算和存储分离也更符合当代应用架构的需要 。
经验总结扩展阅读











- 姐夫的姐夫如何称呼
- 深空之眼流萤岚雾休刻印如何搭配比较合适
- ipad如何分屏工作(ipad微信分屏怎么取消)
- ipad如何左右分屏(ipadcanvas上下分屏)
- ipad如何打开分屏模式(ipad如何关联分屏模式)
- TCP 序列号和确认号是如何变化的?
- 如何通过 C#/VB.NET 重命名 Excel 表格并设置选项卡颜色
- 2023年摩羯座财运1月运程详解如何提高
- 81年属鸡今年多大了2023 81年属鸡2023年运势发如何
- 2023年属鼠逢兔年运势如何