以 A 股的股票为例:A 股市场十年的分钟 K 线历史行情,5000/2 股票 240 分钟 250 天 10 年 8 字节*20 列=240GB,整体 10 年的数据量大约是 240G 。
如果使用更细力度的数据,数据量就会更大,一般来说原始数据不会超过 100TB 的范围 。在大数据时代这算不上是特别大的数据量,但是当大量的计算任务去同时去访问这些数据,这种场景就对数据存储的有一些要求 。
另外,量化投研过程中伴随着大量的突发任务,研究团队希望能将这些任务的结果存储起来,因此会产生大量 archive 数据,但这些数据的访问频率很低 。
量化研究计算任务特点基于以上特点,如果以传统的机房方式,是很难去满足我们的计算需求,因此把计算搬到云计算平台对我们来讲是一个相对合适的技术选择 。
文章插图
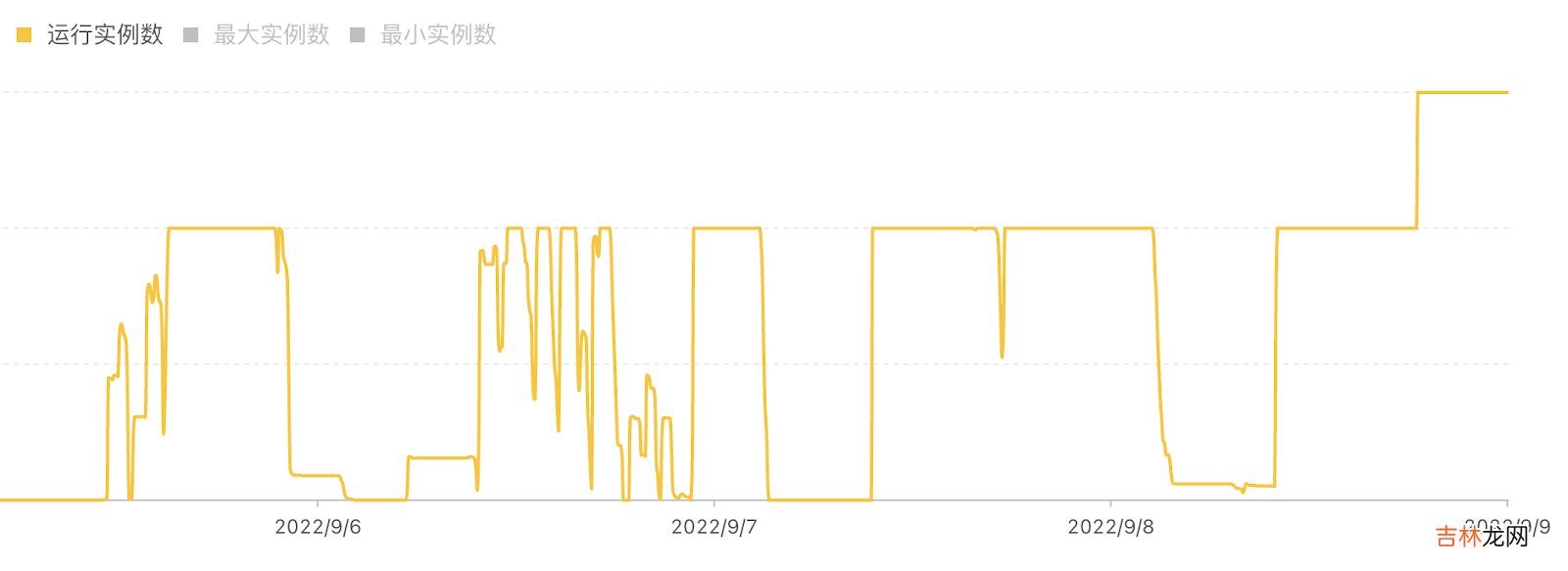
第一,突发任务多,弹性非常大 。上图是我们某个集群近期的运行实例数据 。可以看到在多个时间段里,整个集群实例都是被打满的状态,但是同时整个计算集群的规模也会有 scale 到 0 的时候 。量化机构的计算任务和研究员的研发的进度是有很大关联的,波峰波谷的差距会非常大,这也是离线研究任务的特点 。
第二,“技术爆炸”,很难准确预估何时会产生算力需求 。“技术爆炸”是科幻小说《三体》的概念,对应到我们这就是我们的研究模式和算力的需求会发生飞跃式进步,我们很难准确预估算力需求的变化 。我们在 2020 年年初的时候,研究的实际用量和预估用量都非常小,但是当研究团队提出的一些新的研究方法思路之后,会在某个瞬间突然对算力产生非常大的需求 。而容量规划是在建设传统机房的规划时候非常重要的一件事情 。
第三,现代 AI 生态,几乎是搭载在云原生平台上的 。我们做了很多创新的技术尝试,包括现在非常流行的 MLOps,将整套 pipeline 串联起来,再去做机器学习训练的流水线;现在很多的分布式的训练任务的支持,都是面向云原生去做了很多的开发工作,这也使得我们把整个计算任务放到云上成为一个很自然的选择 。
02 量化平台存储需求根据上面业务和计算的需求,可以比较容易的去推导出来我们对存储平台的需求 。
- 计算与存储不均衡 。上文提到计算任务会有很大的突增,计算量会很容易会达到非常高的水平 。而热数据的增长量并没有那么快,这就意味着我们需要去做存算分离 。
- 为热数据,比如行情的数据,提供高吞吐的访问 。上百个任务同时访问数据,对它吞吐要求非常高 。
- 为冷数据提供低成本存储 。量化研究需要大量 archive 数据,也要为这些数据提供相对低成本的存储 。
- 文件类型/需求多样性即 POSIX 兼容性 。我们有很多不同的计算任务,这些计算任务对文件的类型的需求是非常多样的,例如CSV、Parquet 等,有一些研究场景还有更灵活的定制开发的需求,这就意味着在选型的时候不能够对文件存储方式做严格限制,因此 POSIX 的兼容性对于存储平台选型是一个很关键的考量因素 。
- IP 保护:数据共享与数据隔离 。我们 IP 保护的需求,不仅是计算任务上需要做这样的隔离,在数据上也是需要支持这样的隔离能力;同时对行情数据这类相对公开的数据,还需要支持研究员的获取方式是便捷的 。
- AI 生态,在云的平台上去做各种任务的调度 。这也是较为基础的一个使用需求,因此存储上也是需要对 Kubernetes 做很好的支持 。
- 模块化即中间结果存储/传输 。计算任务模块化的场景,导致我们会对中间结果的存储跟传输也有需求 。举个简单的例子,在特征计算过程中会生成比较大量的特征数据,这些数据会立刻用于被训练的节点上,我们需要一个中间存储介质去做缓存 。
经验总结扩展阅读
- 17 基于SqlSugar的开发框架循序渐进介绍-- 基于CSRedis实现缓存的处理
- 19 基于.NetCore开发博客项目 StarBlog - Markdown渲染方案探索
- Arctic 基于 Hive 的流批一体实践
- 2023年9月26日适合投资吗 2023年9月26日投资好吗
- 三 AIR32F103 Linux环境基于标准外设库的项目模板
- 2023年9月投资黄道吉日 2023年9月哪天适合投资
- 2023年9月27日投资行吗 2023年9月27日投资好不好
- 2023年2月2日投资好不好 2023年2月2日是投资的黄道吉日吗
- 2023年9月28日投资好吗 2023年9月28日投资吉日一览表
- 盘它!基于CANN的辅助驾驶AI实战案例,轻松搞定车辆检测和车距计算!