3.3、号段模式这种模式也是现在生成分布式ID的一种方法,实现思路是会从数据库获取一个号段范围,比如[1,1000],生成1到1000的自增ID加载到内存中,建表结构如:
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '当前最大id',step int(20) NOT NULL COMMENT '号段的布长',biz_type int(20) NOT NULL COMMENT '业务类型',version int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`))
- biz_type :不同业务类型
- max_id :当前最大的id
- step :代表号段的步长
- version :版本号,就像MVCC一样,可以理解为乐观锁
【分布式ID生成方案总结整理】
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX- 优点:有比较成熟的方案,像百度Uidgenerator,美团Leaf
- 缺点:依赖于数据库实现
INCR 和 INCRBY 这样的自增原子命令,由于Redis单线程的特点,可以保证ID的唯一性和有序性这种实现方式,如果并发请求量上来后,就需要集群,不过集群后,又要和传统数据库一样,设置分段和步长
优缺点:
- 优点:Redis性能相对比较好,又可以保证唯一性和有序性
- 缺点:需要依赖Redis来实现,系统需要引进Redis组件
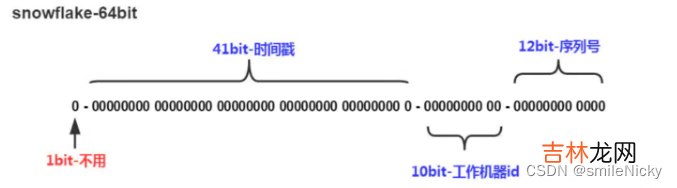
文章插图
- 第一部分:第一位占用1bit,始终是0,是一个符号位,不使用
- 第二部分:第2位开始的41位是时间戳 。41-bit位可表示241个数,每个数代表毫秒,那么雪花算法可用的时间年限是(241)/(1000
经验总结扩展阅读
- 【多服务场景化解决方案】AR虚拟技术助力智能家装
- three.js webgl3D光伏,3D太阳能能源,3D智慧光伏、光伏发电、清洁能源三维可视化解决方案——第十六课
- React动画实现方案之 Framer Motion,让你的页面“自己”动起来
- 19 基于.NetCore开发博客项目 StarBlog - Markdown渲染方案探索
- LabVantage仪器数据采集方案
- 从0搭建vue3组件库:自动化发布、管理版本号、生成 changelog、tag
- 最佳的兔年女宝宝取名方案 2023属兔宝宝名字揭秘
- docker swarm快速部署redis分布式集群
- 2022年24号台风什么时候生成 2022年24号台风山猫胚胎最新消息
- Paxos分布式系统共识算法?我愿称其为点歌算法…

















