目录
- 1、为什么需要分布式ID?
- 2、业务系统对分布式ID有什么要求?
- 3、分布式ID生成方案
- 3.1 UUID
- 3.2、数据库自增
- 3.3、号段模式
- 3.4、 Redis实现
- 3.4、 雪花算法(SnowFlake)
- 3.5、 百度Uidgenerator
- 3.6、 美团Leaf
- 3.7、 滴滴TinyID

文章插图
2、业务系统对分布式ID有什么要求?
- 全局唯一性:ID是作为唯一的标识,不能出现重复
- 趋势递增:互联网比较喜欢MySQL数据库,而MySQL数据库默认使用InnoDB存储引擎,其使用的是聚集索引,使用有序的主键ID有利于保证写入的效率
- 单调递增:保证下一个ID大于上一个ID,这种情况可以保证事务版本号,排序等特殊需求实现
- 信息安全:前面说了ID要递增,但是最好不要连续,如果ID是连续的,容易被恶意爬取数据,指定一系列连续的,所以ID递增但是不规则是最好的
- UUID
- 数据库自增
- 号段模式
- Redis实现
- 雪花算法(SnowFlake)
- 百度Uidgenerator
- 美团Leaf
- 滴滴TinyID
863e254b-ae34-4371-87da-204b71d46a7b 。UUID理论上的总数为1632=2128,约等于3.4 x 10^38 。- 优点
- 性能非常高,本地生成的,不依赖于网络
- 缺点
- 不易存储,16 字节128位,36位长度的字符串
- 信息不安全,基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置
- uuid的无序性可能会引起数据位置频繁变动,影响性能
auto_increment_increment和 auto_increment_offset 即可,在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等 。比如有两台机器 。设置步长step为2,Server1的初始值为1(1,3,5,7,9,11…)、Server2的初始值为2(2,4,6,8,10…) 。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )假设有N台机器,step就要设置为N,如图进行设置:
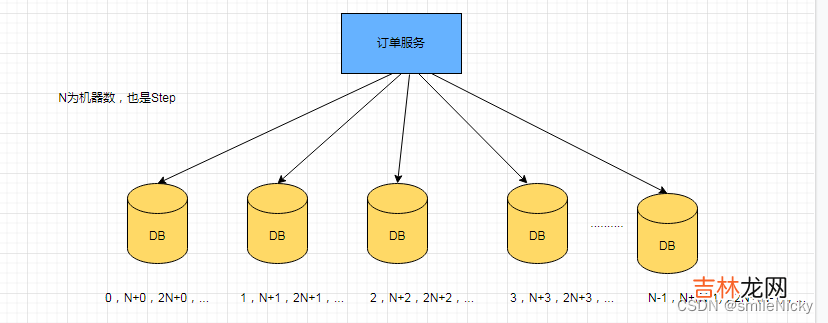
文章插图
这种方案看起来是可行的,但是如果要扩容,步长step等要重新设置,假如只有一台机器,步长就是1,比如这种实现的缺陷:1,2,3,4,5,6,这时候如果要进行扩容,就要重新设置,机器2可以挑一个偶数的数字,这个数字在扩容时间内,数据库自增要达不到这个数的,然后步长就是2,机器1要重新设置step为2,然后还是以一个奇数开始进行自增 。这个过程看起来不是很杂,但是,如果机器很多的话,那就要花很多时间去维护重新设置
- ID没有了单调递增的特性,只能趋势递增,有些业务场景可能不符合
- 数据库压力还是比较大,每次获取ID都需要读取数据库,只能通过多台机器提高稳定性和性能
经验总结扩展阅读
- 【多服务场景化解决方案】AR虚拟技术助力智能家装
- three.js webgl3D光伏,3D太阳能能源,3D智慧光伏、光伏发电、清洁能源三维可视化解决方案——第十六课
- React动画实现方案之 Framer Motion,让你的页面“自己”动起来
- 19 基于.NetCore开发博客项目 StarBlog - Markdown渲染方案探索
- LabVantage仪器数据采集方案
- 从0搭建vue3组件库:自动化发布、管理版本号、生成 changelog、tag
- 最佳的兔年女宝宝取名方案 2023属兔宝宝名字揭秘
- docker swarm快速部署redis分布式集群
- 2022年24号台风什么时候生成 2022年24号台风山猫胚胎最新消息
- Paxos分布式系统共识算法?我愿称其为点歌算法…