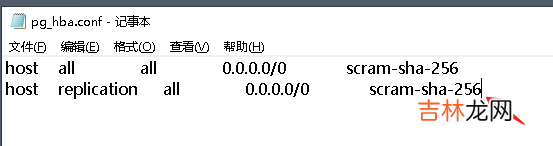
然后还需要调整主实例的 pg_hba.conf,添加 replication 模式的连接白名单配置 。hostreplicationall0.0.0.0/0scram-sha-256
文章插图
调整配置文件之后记得重启主数据库实例 。
主实例重启之后,我们还需要连接到主实例创建复制槽,默认情况下WAL归档文件是循环滚动清理,这就会导致一个问题如果我们的从实例挂机之后离线的时间较长,就有可能因为主实例的WAL文件已经循环滚动删除了,这种情况下,就算从实例修复好之后重新上线,因为主实例的部分WAL归档文件已经清理了,也无法再追赶上我们主实例的数据进度,这种情况下从实例会直接报错 。因为有这种场景的存在所以 PostgreSQL 里面出现了一个复制槽的概念,主实例可以创建多个复制槽,一个复制槽绑定给一个从实例使用,复制槽的好处在于会确保从实例获取到WAL文件之后才会进行清理,不会有前面说的滚动循环自动清理的问题 。
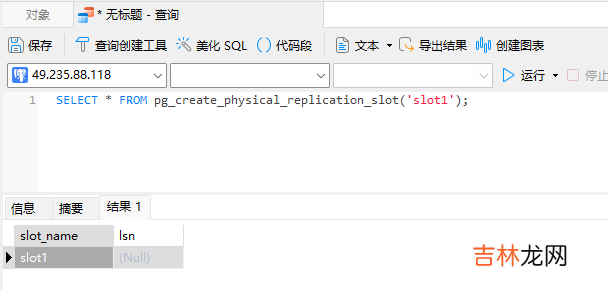
复制槽的维护都在主实例进行:创建,查询,删除的语句如下创建复制槽SELECT * FROM pg_create_physical_replication_slot('slot1');
文章插图
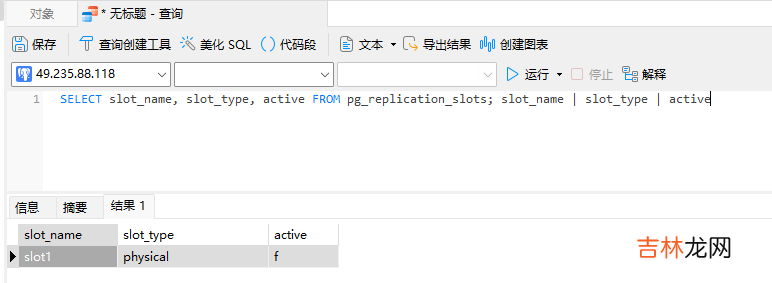
查询全部的复制槽SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active
文章插图
删除复制槽SELECT * FROM pg_drop_replication_slot('slot1')
至此主实例的配置就都完成了,接下来就是准备我们的从实例,因为物理复制不同于逻辑复制,是针对整个实例复制的,所以我们需要准备一个和主实例,版本相同的从实例,如果主实例已经有数据库在上面了,推荐直接把停止主实例的运行然后把PostgreSQL文件夹和Data整体打包压缩复制一份到新的服务器上启动起来作为从实例 。我这里选择直接把云服务器上的 PostgreSQL 打包压缩然后复制到本地解压,作为从实例
文章插图

文章插图
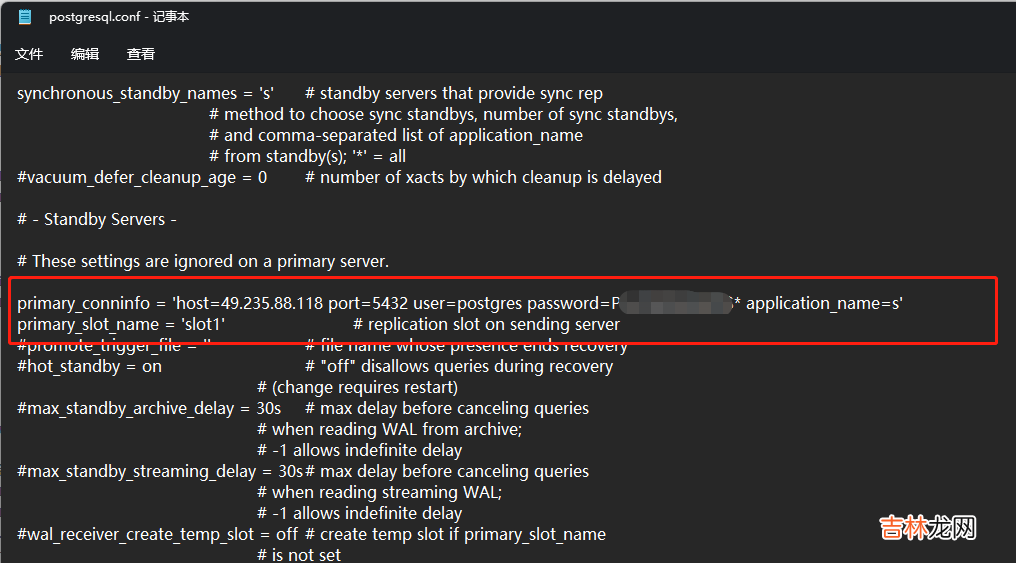
在本地解压之后,做为 从实例 需要做如下的调整,postgresql.confprimary_conninfo = 'host=49.235.88.118 port=5432 user=postgres password=xxxxxx application_name=s'primary_slot_name = 'slot1'
文章插图
primary_conninfo 主要内容就是我们主实例的连接字符串信息然后加一个 application_name,application_name 和我们前面在主实例上配置的 synchronous_standby_names 想关联,前面我们配置了主实例的所有事务操作都需要同步等待 名字为 s 的备库执行完成primary_slot_name 则是复制槽的名称我们前面创建了一个 slot1 的复制槽,给我们的这个从实例使用 。
这里需要注意一点,在配置的时候如果有多个从实例,则一个从实例对应一个复制槽,绑定一个 application_name 。然后在 data 目录下新建一个空文件standby.signal

文章插图
这个文件的其实一个信号标记,标识我们当前的实例时一个只读实例,不可以用于数据插入 。然后启动备库就可以了,正常情况会看到如下界面

文章插图
这时候我们可以尝试去主实例创建一个数据库做一些操作,然后连接从实例,就会发现两边都是互相同步的 。

文章插图

经验总结扩展阅读










- Linux下MMDetection环境配置
- 二、.Net Core搭建Ocelot
- MongoDB数据库新手入门
- 一台虚拟机,基于docker搭建大数据HDP集群
- 二 沁恒CH32V003: Ubuntu20.04 MRS和Makefile开发环境配置
- pytorch、paddlepaddle等环境搭建 深度学习环境搭建常用网址、conda/pip命令行整理
- Win环境安装Protobuf 2.0 版本
- 【保姆教程】RuoYi-Radius搭建实现portal认证
- Windows下自动云备份思源笔记到Gitee
- windows启动不了开不了机怎么办(笔记本无法启动windows)