此外推送可以慢慢进行,但是用户很难容忍打开页面时需要等待很长时间才能看到内容(很长:指等一秒钟就觉得卡) 。因此拉模型读取效率低下的缺点使得它的应用受到了极大限制 。
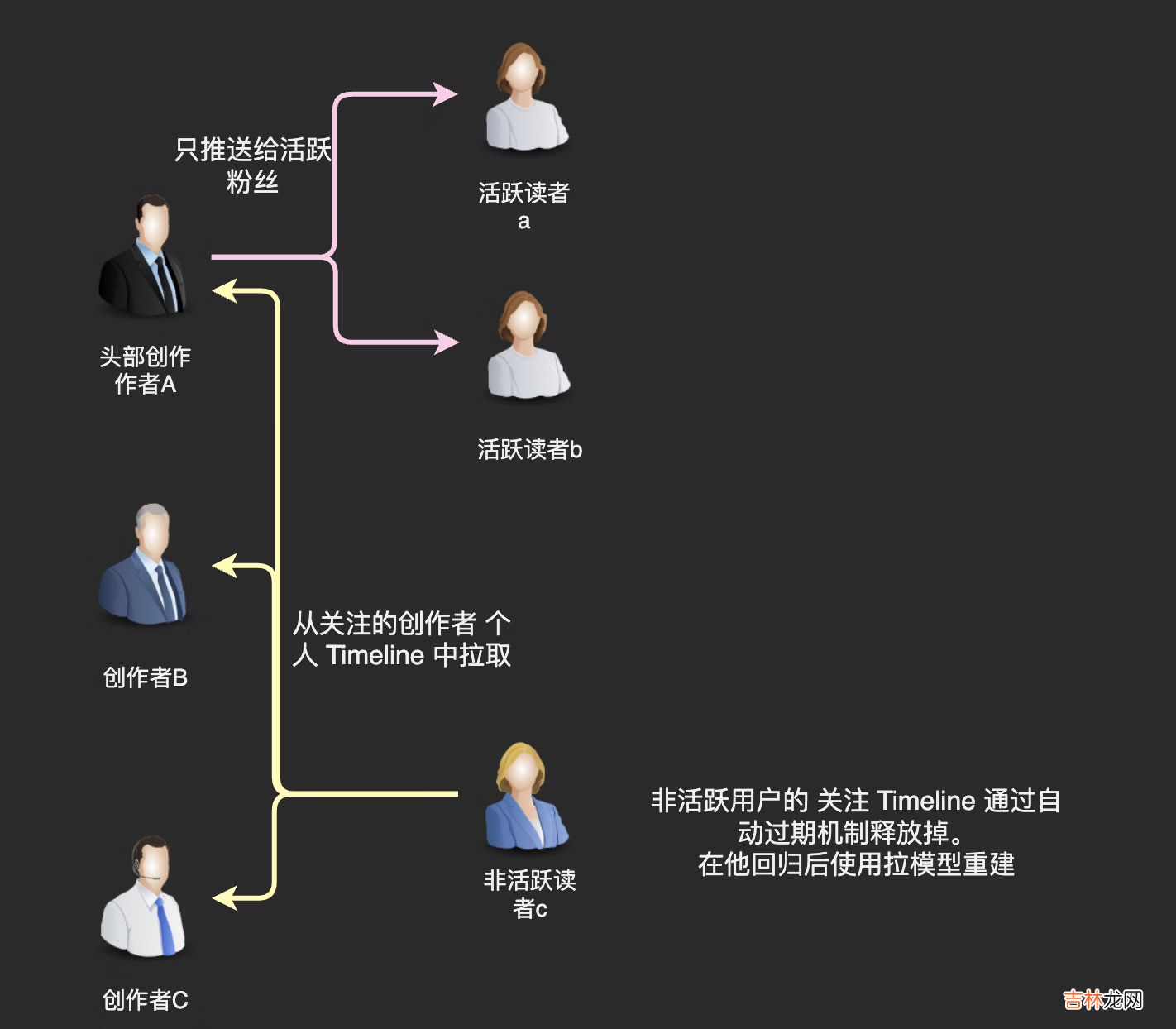
我们回过头来看困扰推模型的这个问题「粉丝数多的时候会是灾难」,我们真的需要将文章推送给作者的每一位粉丝吗?
仔细想想这也没有必要,我们知道粉丝群体中活跃用户是有限的,我们完全可以只推送给活跃粉丝,不给那些已经几个月没有启动 App 的用户推送新文章 。
至于不活跃的用户,在他们回归后使用拉模型重新构建一下关注 Timeline 就好了 。因为不活跃用户回归是一个频率很低的事件,我们有充足的计算资源使用拉模型进行计算 。
文章插图
因为活跃用户和不活跃用户常常被叫做「在线用户」和「离线用户」,所以这种通过推拉结合处理头部作者发布内容的方式也被称为「在线推,离线拉」 。
再优化一下存储在前面的讨论中不管是「关注 Timeline」还是关注关系等数据我们都存储在了 MySQL 中 。拉模型可以用 SQL 描述为:
SELECT *FROM articlesWHERE author_uid IN ( SELECT following_uid FROM followings WHERE uid = ?)ORDER BY create_time DESCLIMIT 20;通过查看执行计划我们发现,临时表去重+Filesort、这个查询叠了不少 debuff: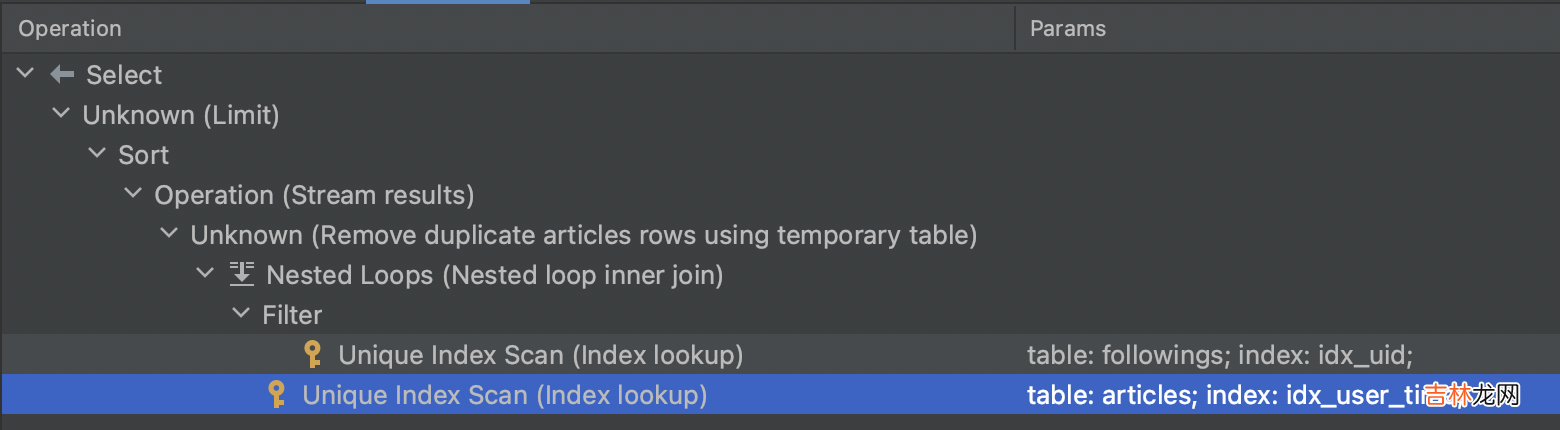
文章插图
至于推模型,关注 Timeline 巨大的数据量和读写负载就不是 MySQL 能扛得住的 。。。
遇事不决上 Redis显然关注 Timeline 的数据是可以通过 articles 和 followings 两张表中数据重建的,其存在只是为了提高读取操作的效率 。这有没有让你想起另外一个东西?
没错!就是缓存,关注 Timeline 实质上就是一个缓存,也就是说关注 Timeline 与缓存一样只需要暂时存储热门数据 。
我们可以给关注 Timeline 存储设置过期时间,若用户一段时间没有打开 App 他的关注 Timeline 存储将被过期释放,在他回归之后通过拉模型重建即可 。
在使用「在线推,离线拉」策略时我们需要判断用户是否在线,在为 Timeline 设置了过期时间后,Timeline 缓存是否存在本身即可以作为用户是否在线的标志 。
就像很少有人翻看三天前的朋友圈一样,用户总是关心关注页中最新的内容,所以关注 Timeline 中也没有必要存储完整的数据只需要存储最近一段时间即可,旧数据等用户翻阅时再构建就行了 。
鲁迅有句话说得好 ——「遇事不决上 Redis」,既然是缓存那么就是 Redis 的用武之地了 。

文章插图
Redis 中有序数据结构有列表 List 和有序集合 SortedSet 两种,对于关注 Timeline 这种需要按时间排列且禁止重复的场景当然闭着眼睛选 SortedSet 。
将 article_id 作为有序集合的 member、发布时间戳作为 score, 关注 Timeline 以及个人 Timeline 都可以缓存起来 。
在推送新 Feed 的时候只需要对目标 Timeline 的 SortedSet 进行 ZAdd 操作 。若缓存中没有某个 Timeline 的数据就使用拉模型进行重建 。
在使用消息队列进行推送时经常出现由于网络延迟等原因导致重复推送的情况,所幸 article_id 是唯一的,即使出现了重复推送 Timeline 中也不会出现重复内容 。
这种重复操作不影响结果的特性有个高大上的名字 ——— 幂等性当 Redis 中没有某个 Timeline 的缓存时我们无法判断是缓存失效了,还是这个用户的 Timeline 本来就是空的 。我们只能通过读取 MySQL 中的数据才能进行判断,这就是经典的缓存穿透问题 。
经验总结扩展阅读









- 2023年1月27日训狗黄道吉日 2023年1月27日训狗好吗
- 2023年农历正月初六训马吉日 2023年1月27日训马黄道吉日
- 2023年1月27日剪指甲好吗 2023年1月27日剪指甲好不好
- 2023年1月27日剃头行吗 2023年农历正月初六剃头吉日
- 2023年1月27日遇见贵人好吗 2023年1月27日是遇见贵人的黄道吉日吗
- 2023年1月27日适合堵蚁穴吗 2023年农历正月初六宜堵蚁穴吗
- 2023年1月27日是清扫房屋吉日吗 2023年1月27日清扫房屋好吗
- 2023年1月27日上学吉日一览表 2023年1月27日上学好不好
- 2023年农历正月初六宜开学吗 2023年1月27日开学吉日一览表
- 2023年农历正月初六开学典礼吉日 2023年1月27日开学典礼吉日一览表