对于时间线这种集合式的还存在第二类缓存穿透问题,正如我们刚刚提到的 Redis 中通常只存储最近一段时间的 Timeline,当我们读完了 Redis 中的数据之后无法判断数据库中是否还有更旧的数据 。
这两类问题的解决方案是一样的,我们可以在 SortedSet 中放一个 NoMore 的标志,表示数据库中没有更多数据了 。对于 Timeline 本来为空的用户来说,他们的 SortedSet 中只有一个 NoMore 标志:

文章插图
最后一点:拉取操作要注意保持原子性不要将重建了一半的 Timeline 暴露出去:

文章插图
总结一下使用 Redis 做关注时间线的要点:
- 使用 SortedSet 结构存储,Member 为 FeedID,Score 为时间戳
- 给缓存设置自动过期时间,不活跃用户的缓存会自动被清除 。使用「在线推,离线拉」时只给 Timeline 缓存未失效的用户推送即可
- 需要在缓存中放置标志来防止缓存击穿
缓存不足是计算机领域的经典问题了,问问你的 CPU 它就会告诉你答案 —— 一级缓存不够用就做二级缓存,L1、L2、L3 都用光了我才会用内存 。
只要是支持有序结构的 NewSQL 数据库比如 Cassandra、HBase 都可以胜任 Redis 的二级缓存:
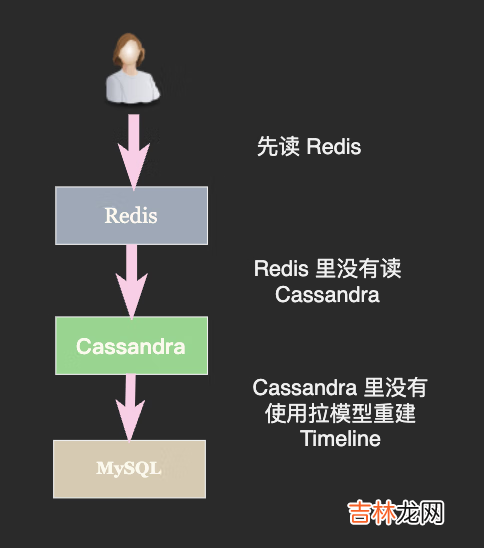
文章插图
附上一条 Cassandra 的表结构描述:
-- Cassandra 是一个 Map<PartionKey, SortedMap<ClusteringKey, OtherColumns>> 结构-- 必须指定一个 PartionKey,顺序也只能按照 ClusteringKey 的顺序排列-- 这里 PartionKey 是 uid, ClusteringKey 是 publish_time + article_id-- publish_time 必须写在 ClusteringKey 第一列才能按照它进行排序-- article_id 也写进 ClusteringKey 是为了防止 publish_time 出现重复CREATE TABLE taojin.following_timelins (uid bigint,publish_time timestamp,article_id bigin,PRIMARY KEY (uid, publish_time, article_id)) WITH default_time_to_live = 60 * 24 * 60 * 60;这里还是要提醒一下,每多一层缓存便要多考虑一层一致性问题,到底要不要做多级缓存需要仔细权衡 。还有一些细节要优化分页器Feed 流是一个动态的列表,列表内容会随着时间不断变化 。传统的 limit + offset 分页器会有一些问题:
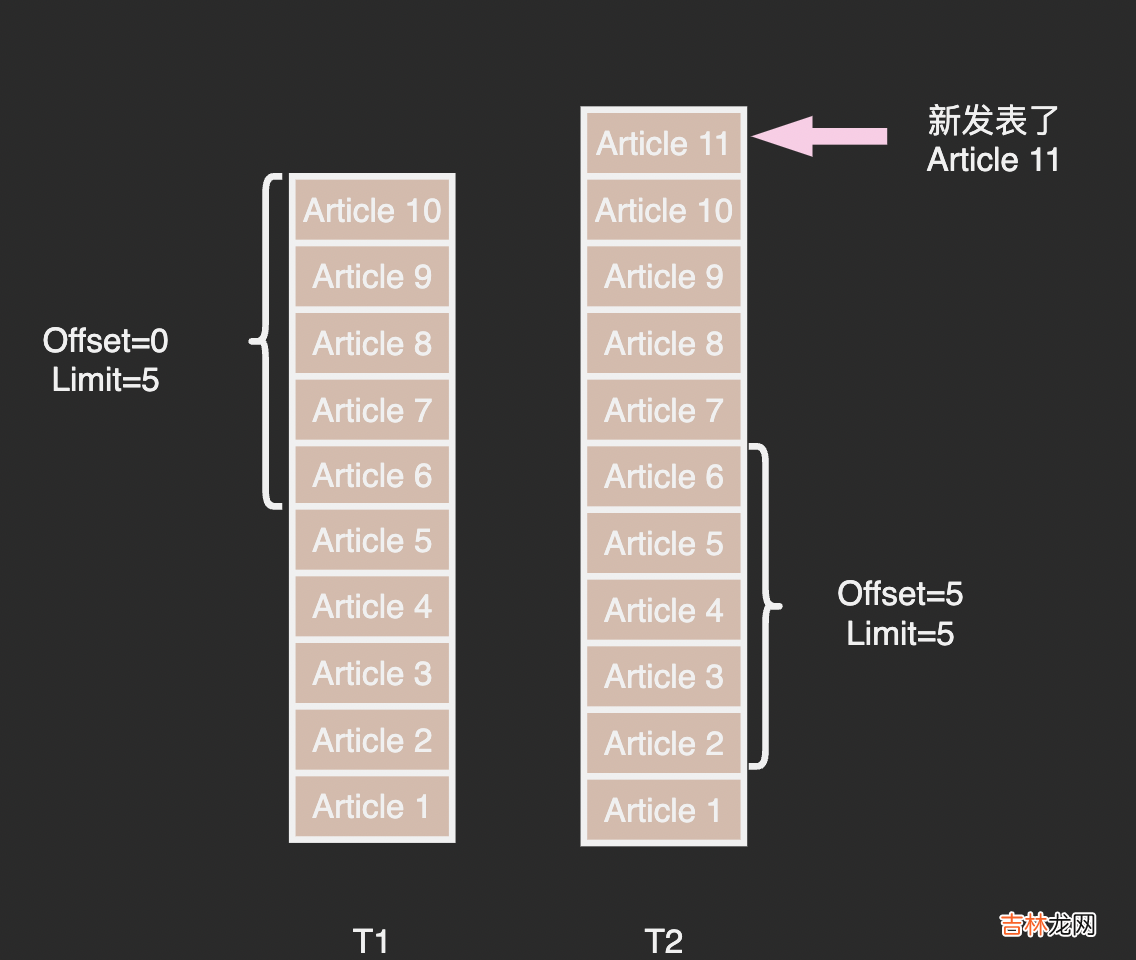
文章插图
在 T1 时刻读取了第一页,T2时刻有人新发表了 article 11,如果这时来拉取第二页,会导致 article 6 在第一页和第二页都被返回了 。
解决这个问题的方法是根据上一页最后一条 Feed 的 ID 来拉取下一页:

文章插图
【4 从小白到架构师: Feed 流系统实战】使用 Feed ID 来分页需要先根据 ID 查找 Feed,然后再根据 Feed 的发布时间读取下一页,流程比较麻烦 。若作为分页游标的 Feed 被删除了,就更麻烦了 。
笔者更倾向于使用时间戳来作为游标:
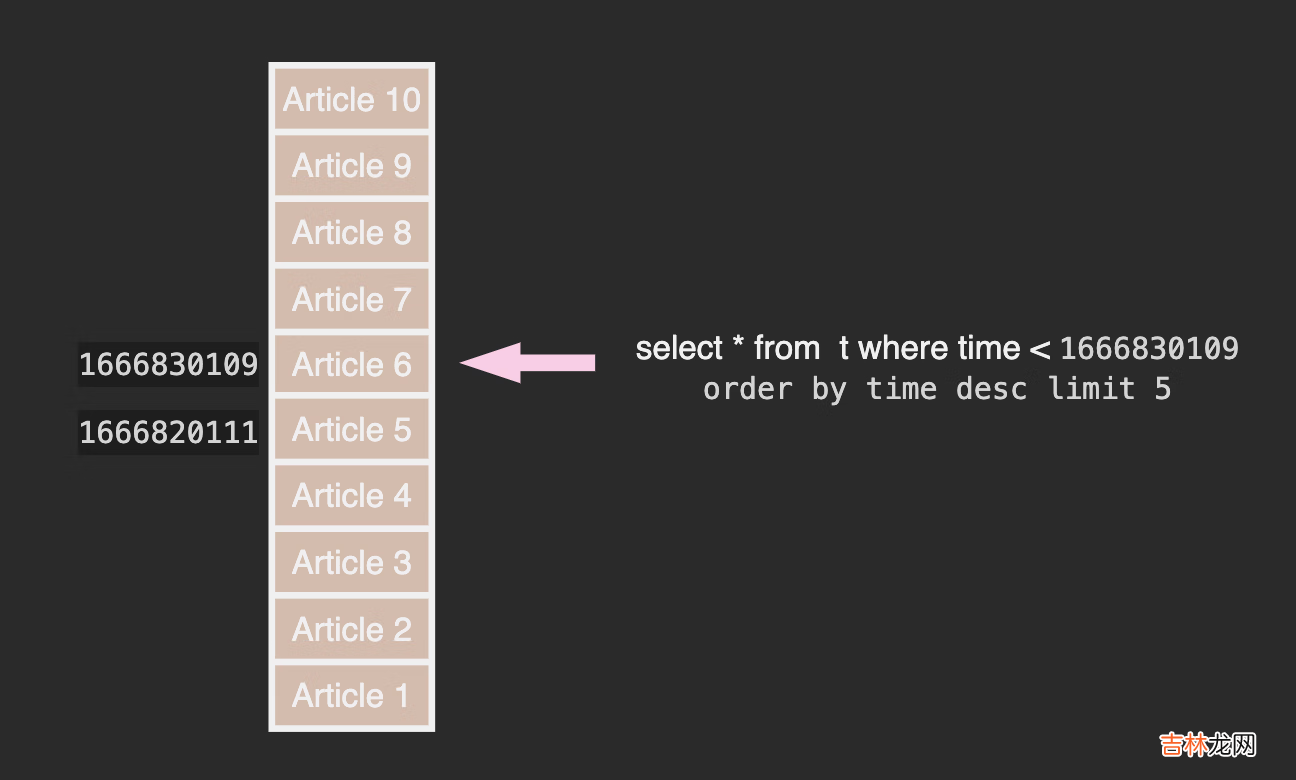
文章插图
使用时间戳不可避免的会出现两条 Feed 时间戳相同的问题, 这会让我们的分页器不知所措 。

文章插图
这里有个小技巧是将 Feed id 作为 score 的小数部分,比如 article 11 在 2022-10-27 13:55:11 发布(时间戳 1666850112),那么它的 score 为 1666850112.11 小数部分既不影响按时间排序又避免了重复 。
经验总结扩展阅读
















- 2023年1月27日训狗黄道吉日 2023年1月27日训狗好吗
- 2023年农历正月初六训马吉日 2023年1月27日训马黄道吉日
- 2023年1月27日剪指甲好吗 2023年1月27日剪指甲好不好
- 2023年1月27日剃头行吗 2023年农历正月初六剃头吉日
- 2023年1月27日遇见贵人好吗 2023年1月27日是遇见贵人的黄道吉日吗
- 2023年1月27日适合堵蚁穴吗 2023年农历正月初六宜堵蚁穴吗
- 2023年1月27日是清扫房屋吉日吗 2023年1月27日清扫房屋好吗
- 2023年1月27日上学吉日一览表 2023年1月27日上学好不好
- 2023年农历正月初六宜开学吗 2023年1月27日开学吉日一览表
- 2023年农历正月初六开学典礼吉日 2023年1月27日开学典礼吉日一览表