一、架构设计
文章插图
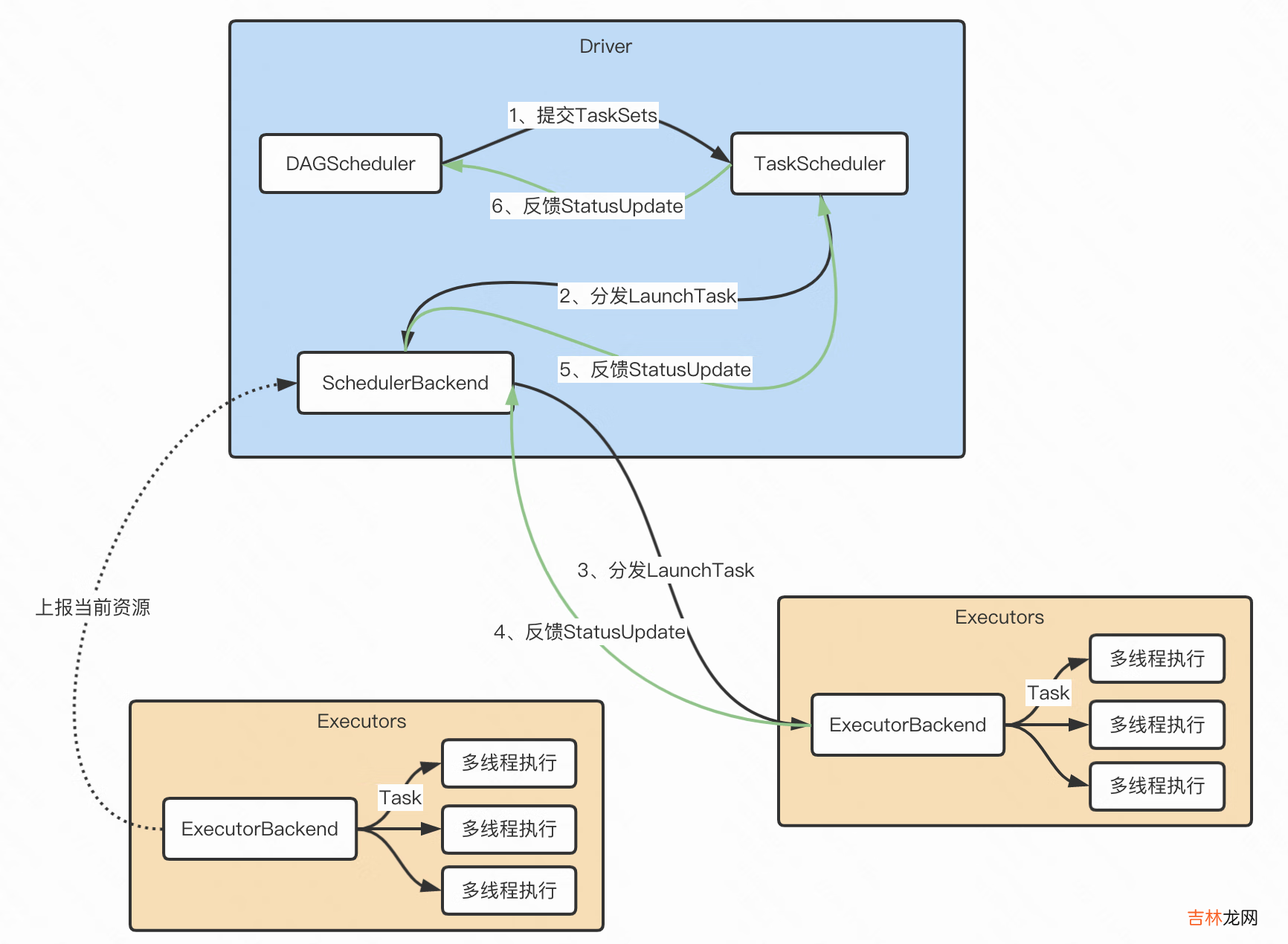
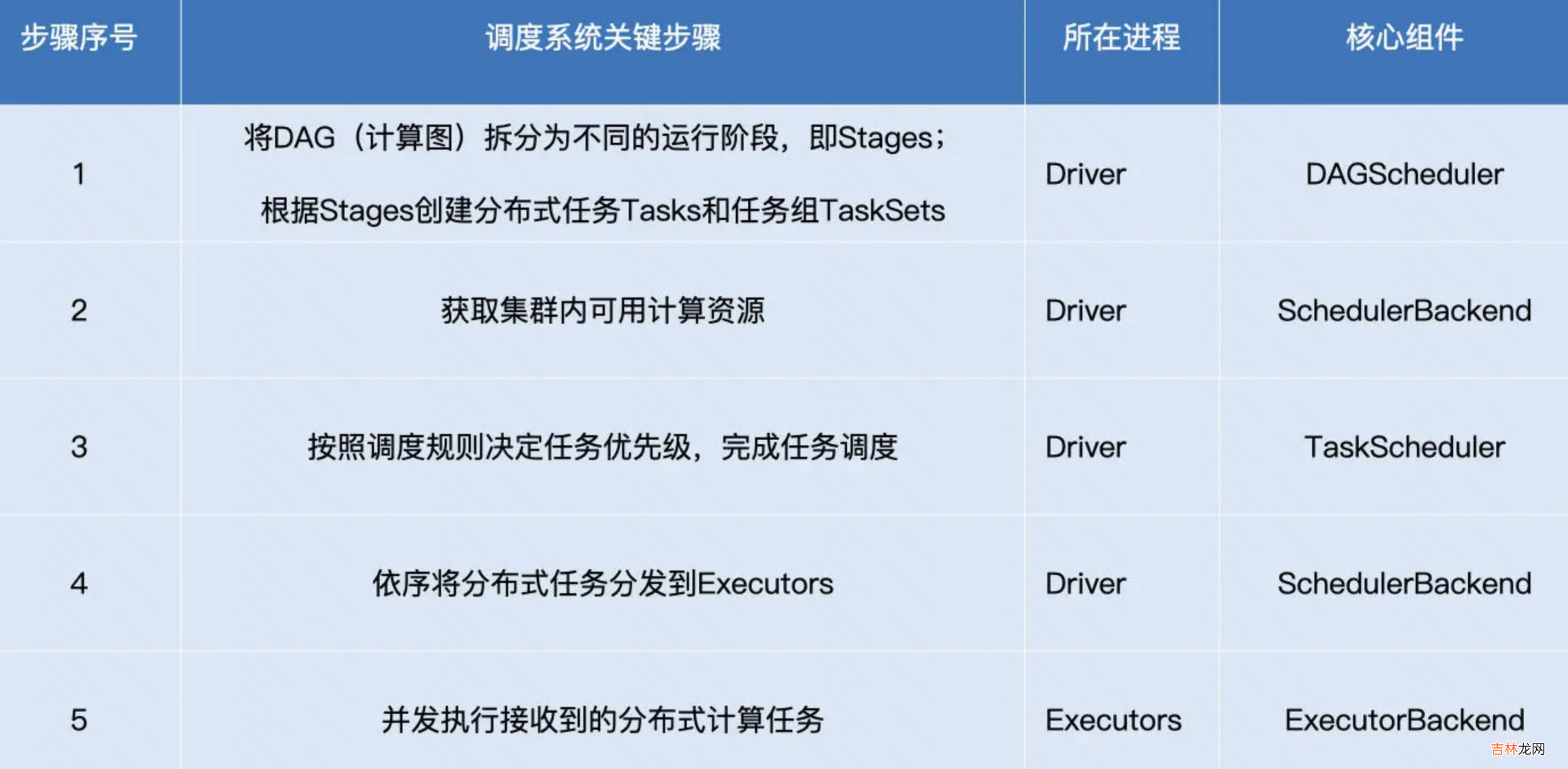
- Driver根据用户代码构建计算流图,拆解出分布式任务并分发到 Executors 中去;每个Executors收到任务,然后处理这个 RDD 的一个数据分片子集
- DAGScheduler根据用户代码构建 DAG;以 Shuffle 为边界切割 Stages;基于 Stages 创建 TaskSets,并将 TaskSets 提交给 TaskScheduler 请求调度
- TaskScheduler 在初始化的过程中,会创建任务调度队列,任务调度队列用于缓存 DAGScheduler 提交的 TaskSets 。TaskScheduler 结合 SchedulerBackend 提供的 WorkerOffer,按照预先设置的调度策略依次对队列中的任务进行调度,也就是把任务分发给SchedulerBackend
- SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态 。会与集群内所有 Executors 中的 ExecutorBackend 保持周期性通信 。SchedulerBackend收到TaskScheduler过来的任务,会把任务分发给ExecutorBackend去具体执行
- ExecutorBackend收到任务后多线程执行(一个线程处理一个Task) 。处理完毕后反馈StatusUpdate给SchedulerBackend,再返回给TaskScheduler,最终给DAGScheduler
文章插图
二、常用算子2.1、RDD概念Spark 主要以一个 弹性分布式数据集_(RDD)的概念为中心,它是一个容错且可以执行并行操作的元素的集合 。有两种方法可以创建 RDD:在你的 driver program(驱动程序)中 _parallelizing 一个已存在的集合,或者在外部存储系统中引用一个数据集,例如,一个共享文件系统,HDFS,HBase,或者提供 Hadoop InputFormat 的任何数据源 。
从内存创建RDD
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// 从内存创建RDDobject MakeRDDFromMemory {def main(args: Array[String]): Unit = {// 准备环境val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")// 并行度,如果不设置则默认当前运行环境的最大可用核数sparkConf.set("spark.default.parallelism", "2")val sc = new SparkContext(sparkConf)// 从内存中创建RDD,将内存中集合的数据作为处理的数据源val seq = Seq[Int](1, 2, 3, 4, 5, 6)val rdd: RDD[Int] = sc.makeRDD(seq)rdd.collect().foreach(println)// numSlices表示分区的数量,不传默认spark.default.parallelismval rdd2: RDD[Int] = sc.makeRDD(seq, 3)// 将处理的数据保存成分区文件rdd2.saveAsTextFile("output")sc.stop()}}从文件中创建RDDimport org.apache.spark.{SparkConf, SparkContext}// 从文件中创建RDD(本地文件、HDFS文件)object MakeRDDFromTextFile {def main(args: Array[String]): Unit = {// 准备环境val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)// 从文件中创建RDD,将文件中的数据作为处理的数据源// path路径默认以当前环境的根路径为基准 。可以写绝对路径,也可以写相对路径//val rdd: RDD[String] = sc.textFile("datas/1.txt")// path路径可以是文件的具体路径,也可以目录名称//val rdd = sc.textFile("datas")// path路径还可以使用通配符 *//val rdd = sc.textFile("datas/1*.txt")// path还可以是分布式存储系统路径:HDFSval rdd = sc.textFile("hdfs://localhost:8020/test.txt")rdd.collect().foreach(println)sc.stop()}}2.2、常用算子map算子:数据转换import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}// map算子object map {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")val sc = new SparkContext(sparkConf)val rdd = sc.makeRDD(List(1, 2, 3, 4))// 转换函数def mapFunction(num: Int): Int = {num * 2}// 多种方式如下//val mapRDD: RDD[Int] = rdd.map(mapFunction)//val mapRDD: RDD[Int] = rdd.map((num: Int) => {//num * 2//})//val mapRDD: RDD[Int] = rdd.map((num: Int) => num * 2)//val mapRDD: RDD[Int] = rdd.map((num) => num * 2)//val mapRDD: RDD[Int] = rdd.map(num => num * 2)val mapRDD: RDD[Int] = rdd.map(_ * 2)mapRDD.collect().foreach(println)sc.stop()}}
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 惊艳我的朋友圈个性签名 句句高品位的ins风签名
- 祝我的男孩儿子 文案 很潮又短的生日祝福
- 生日文案给儿子 愿我的大男孩生日快乐的句子
- 我的汤姆猫里的2048怎么玩(能玩2048的汤姆猫)
- JVM学习笔记——垃圾回收篇
- 我的世界怎么去月球无模组无指令(我的世界新版怎么去月球)
- 我的世界怎么去月球,我的世界手机版月球传送门怎么做
- 我的世界怎么去月球模组免费(mc月球模组)
- 我的世界虚无3月球怎么去(我的世界虚无世界怎么找传送门)
- 我的世界怎么去月球(我的世界惊变100天)