2. Metadata Table(MDT)Metadata Table(MDT):Hudi的元数据信息表,是一个自管理的 Hudi MoR表,位于 Hudi 表的 .hoodie目录,开启后用户无感知 。同样的 Hudi 很早就支持 MDT,经过不断迭代 0.12版本 MDT 已经成熟,当前 MDT 表已经具备如下能力
Column_stats/Bloomfilter上文我们介绍了数据布局优化,接下来说说 Hudi 提供的 FileSkipping能力 。当前 Hudi 支持对指定列收集包括min-max value,null count,total count 在内的统计信息,并且 Hudi 保证这些信息收集是原子性,利用这些统计信息结合查询引擎可以很好的完成 FileSkipping大幅度减少IO 。BloomFilter是 Hudi 提供的另一种能力,当前只支持对主键构建 BloomFilter 。BloomFilter判断不存在就一定不存在的特性,可以很方便进行 FileSkipping,我们可以将查询条件直接作用到每个文件的 BloomFilter 上,进而过滤点无效的文件,注意 BloomFilter 只适合等值过滤条件例如where a = 10,对于 a > 10这种就无能为力 。
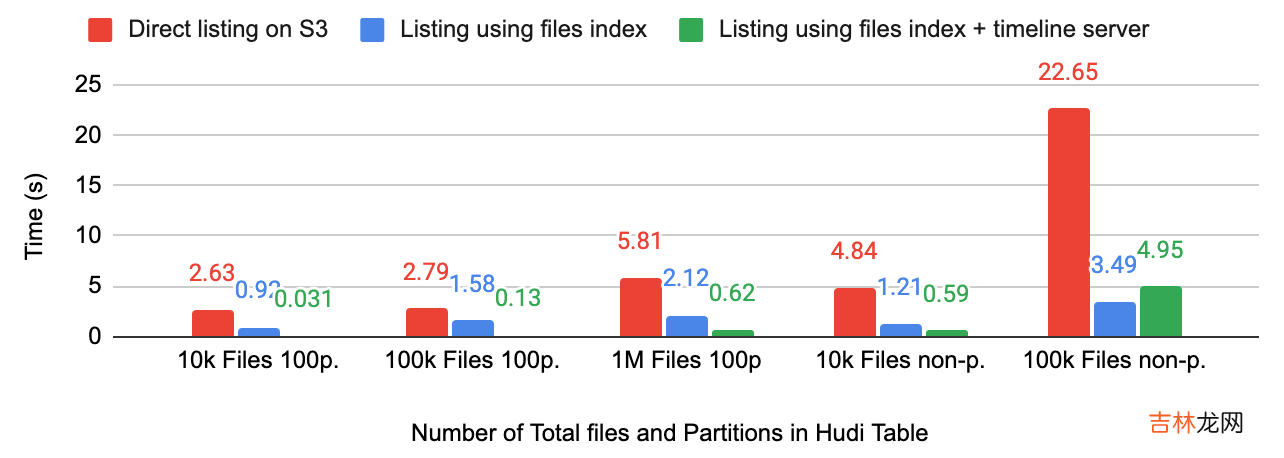
高性能FileList在查询超大规模数据集时,FileList是不可避免的操作,在 HDFS 上该操作耗时还可以接受,一旦涉及到对象存储,大规模 FileList 效率极其低下,Hudi 引入 MDT 将文件信息直接保存在下来,从而避免了大规模FileList 。
文章插图
Presto 与 Hudi的集成HetuEngine(Presto)作为数据湖对外出口引擎,其查询 Hudi 能力至关重要 。对接这块我们主要针对点查和复杂查询做了不同的优化,下文着重介绍点查场景 。在和 Hudi 集成之前首先要解决如下问题
- 如何集成 Hudi,在 Hive Connector 直接魔改,还是使用独立的 Hudi Connector?
- 支持哪些索引做 DataSkipping?
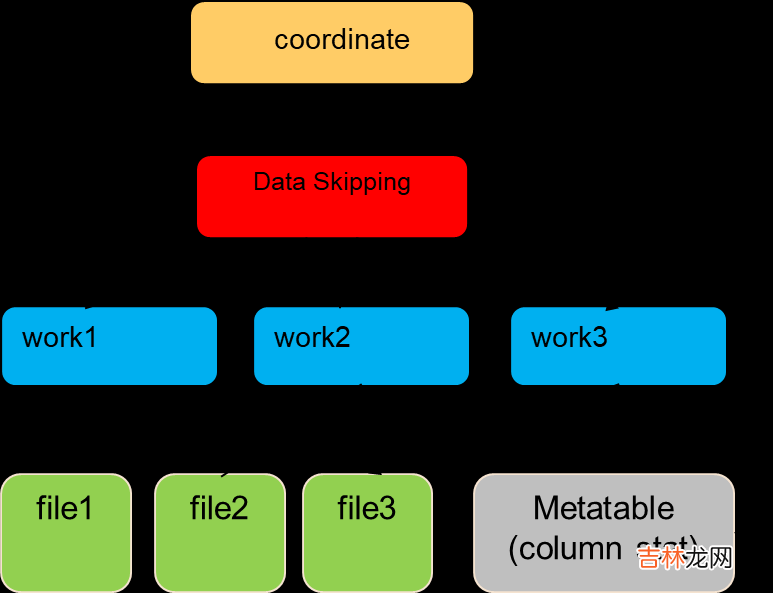
- DataSkipping 在 Coordinator 侧做还是在 Worker 端做?
问题2: 内部 HetuEngine 其实已经支持 Bitmap 和二级索引,本次重点集成了 MDT 的 Column statistics和 BloomFilter 能力,利用 Presto下推的 Filter 直接裁剪文件 。
问题3: 关于这个问题我们做了测试,对于 column 统计信息来说,总体数据量并不大,1w 个文件统计信息大约几M,加载到 Coordinator 内存完全没有问题,因此选择在 Coordinator 侧直接做过滤 。
文章插图
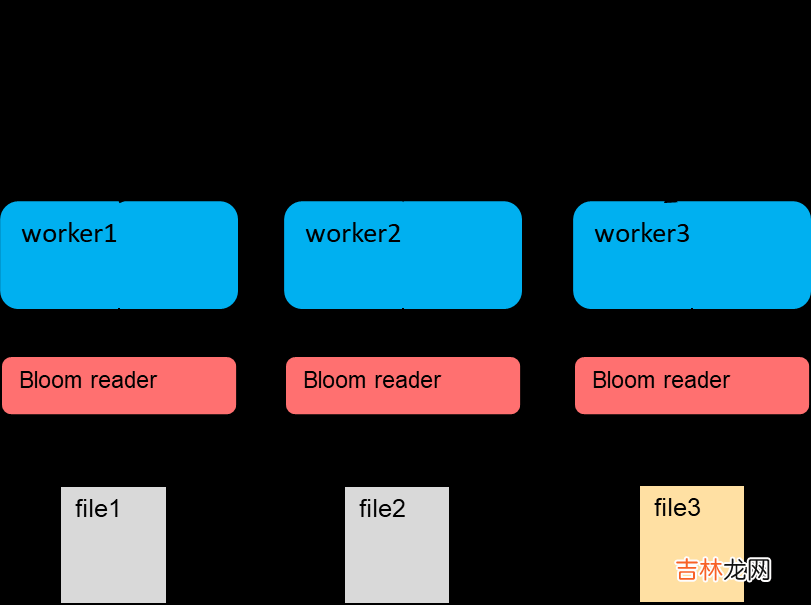
对于 BloomFilter、Bitmap 就完全不一样了,测试结果表明 1.4T 数据产生了 1G 多的 BloomFilter 索引,把这些索引加载到 Coordinator 显然不现实 。我们知道 Hudi MDT 的 BloomFilter 实际是存在 HFile里,HFile点查十分高效,因此我们将 DataSkipping 下压到 Worker 端,每个 Task 点查 HFile 查出自己的 BloomFilter 信息做过滤 。
文章插图
点查场景测试测试数据我们采用和 ClickHouse 一样的SSB数据集进行测试,数据规模1.5T,120亿条数据 。
$ ./dbgen -s 2000 -T c$ ./dbgen -s 2000 -T l$ ./dbgen -s 2000 -T p$ ./dbgen -s 2000 -T s测试环境1CN+3WN Container 170GB,136GB JVM heap, 95GB Max Query Memory,40vcore数据处理利用 Hudi 自带的 Hilbert 算法直接预处理数据后写入目标表,这里 Hilbert 算法指定 S_CITY,C_CITY,P_BRAND, LO_DISCOUNT作为排序列 。
SpaceCurveSortingHelper.orderDataFrameBySamplingValues(df.withColumn("year", expr("year((LO_ORDERDATE))")), LayoutOptimizationStrategy.HILBERT, Seq("S_CITY", "C_CITY", "P_BRAND","LO_DISCOUNT"), 9000).registerTempTable("hilbert")spark.sql("insert into lineorder_flat_parquet_hilbert select * from hilbert")
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 栖云异梦金属星球怎么摆放顺序
- 华为matex2参数_华为matex2参数配置详情
- 云原生之旅 - 8)云原生时代的网关 Ingress Nginx
- 华为开发者大会HDC2022:HMS Core 持续创新,与开发者共创美好数智生活
- 云原生之旅 - 7)部署Terrform基础设施代码的自动化利器 Atlantis
- 华为mate40pro和苹果13pro对比_哪款更值得入手
- 鸿蒙2.0.0.136是什么版本_鸿蒙2.0.0.136更新内容
- 飞云防盗门质量怎么样?
- 华为p50严重缺点_华为p50值得入手吗
- 华为mateviewgt评测_华为mateviewgt显示器评测