测试结果使用冷启动方式,降低 Presto 缓存对性能的影响 。
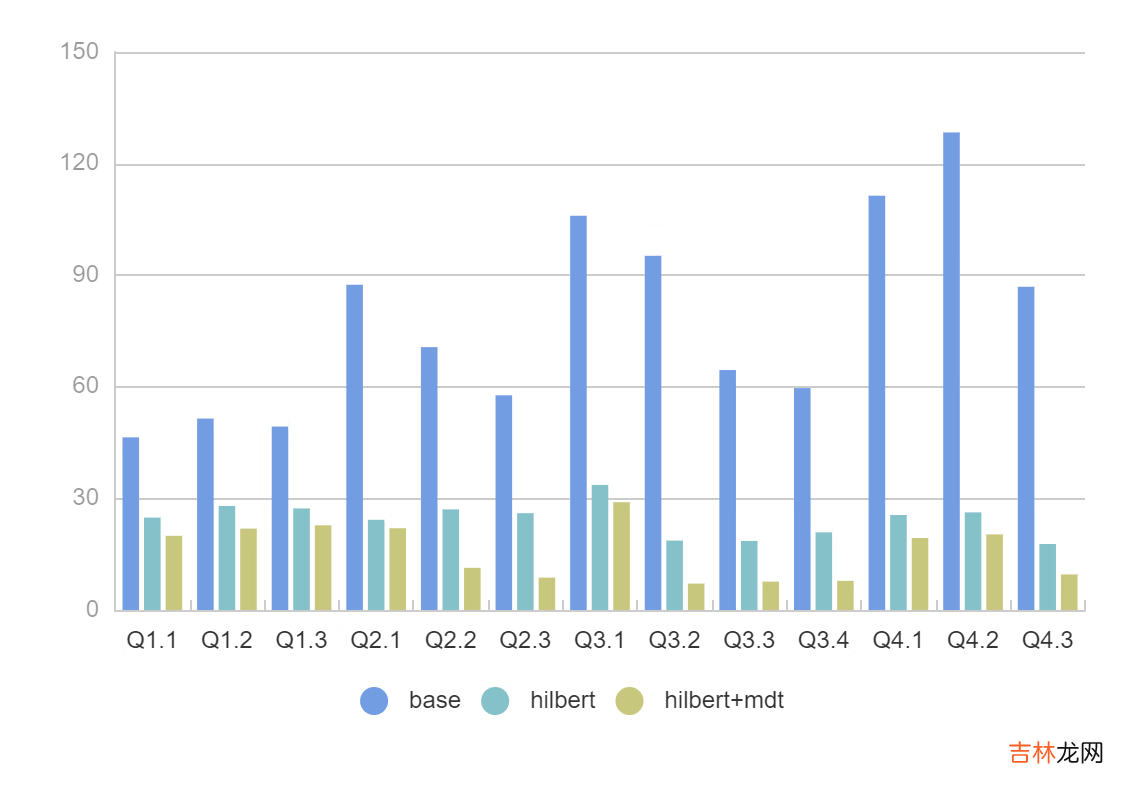
SSB Query
文章插图
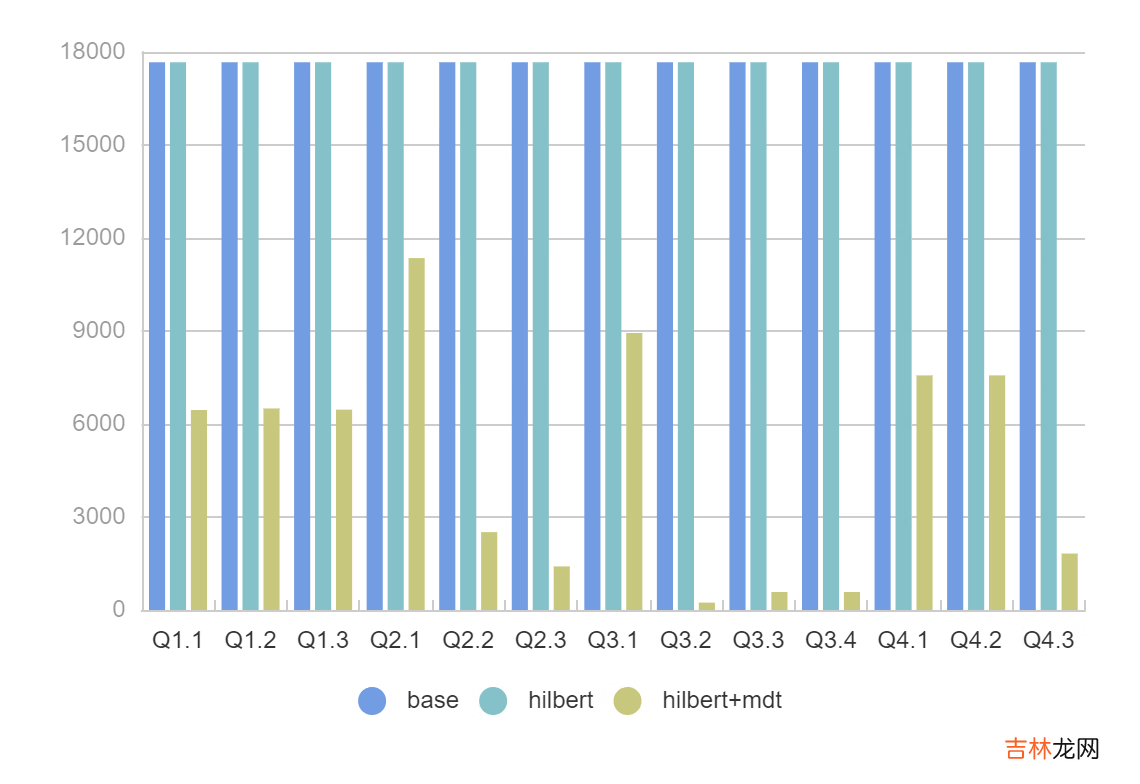
【华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践】文件读取量
文章插图
- 对于所有 SQL 我们可以看到 2x - 11x 的性能提升,FileSkipping 效果更加明显过滤掉的文件有 2x - 200x 的提升 。
- 即使没有 MDT,Presto 强大的 Rowgroup 级别过滤,配合 Hilbert 数据布局优化也可以很好的提升查询性能 。
- SSB模型扫描的列数据都比较少,实际场景中如果扫描多个列
Presto + MDT+ Hilbert的性能可以达到 30x 以上 。 - 测试中同样发现了MDT的不足,120亿数据产生的MDT表有接近50M,加载到内存里面需要一定耗时,后续考虑给MDT配置缓存盘加快读取效率 。
1000w 数据集做测试spark.sql("""|create table prestoc(|c1 int,|c11 int,|c12 int,|c2 string,|c3 decimal(38, 10),|c4 timestamp,|c5 int,|c6 date,|c7 binary,|c8 int|) using hudi|tblproperties (|primaryKey = 'c1',|preCombineField = 'c11',|hoodie.upsert.shuffle.parallelism = 8,|hoodie.table.keygenerator.class = 'org.apache.hudi.keygen.SimpleKeyGenerator',|hoodie.metadata.enable = "true",|hoodie.metadata.index.column.stats.enable = "true",|hoodie.metadata.index.column.stats.file.group.count = "2",|hoodie.metadata.index.column.stats.column.list = 'c1,c2',|hoodie.metadata.index.bloom.filter.enable = "true",|hoodie.metadata.index.bloom.filter.column.list = 'c1',|hoodie.enable.data.skipping = "true",|hoodie.cleaner.policy.failed.writes = "LAZY",|hoodie.clean.automatic = "false",|hoodie.metadata.compact.max.delta.commits = "1"|)||""".stripMargin)最终一共产生了8个文件,结合 BloomFilter Skipping掉了7 个,效果非常明显 。后续工作后续关于点查这块工作会重点关注 Bitmap 以及二级索引 。最后总结一下 DataSkipping 中各种优化技术手段的选择方式 。
- Clustering中各种排序方式需要结合 Column statistics 才能达到更好的效果 。
- BloomFilter 适合等值条件点查,不需要数据做排序,但是要选择高基字段,低基字段 BloomFIlter 用处不大;另外超高基也不要选 BloomFilter,产出的 BloomFilter 结果太大 。
经验总结扩展阅读












- 栖云异梦金属星球怎么摆放顺序
- 华为matex2参数_华为matex2参数配置详情
- 云原生之旅 - 8)云原生时代的网关 Ingress Nginx
- 华为开发者大会HDC2022:HMS Core 持续创新,与开发者共创美好数智生活
- 云原生之旅 - 7)部署Terrform基础设施代码的自动化利器 Atlantis
- 华为mate40pro和苹果13pro对比_哪款更值得入手
- 鸿蒙2.0.0.136是什么版本_鸿蒙2.0.0.136更新内容
- 飞云防盗门质量怎么样?
- 华为p50严重缺点_华为p50值得入手吗
- 华为mateviewgt评测_华为mateviewgt显示器评测