有时候,为了给前端页面输出内容,有时候我们需要准备和数据库不一样的实体信息,因为数据库可能记录的是一些引用的ID或者特殊字符,那么我们为了避免前端单独的进行转义处理,我们可以在后端进行统一的格式化后再行输出,后端处理可以采用不同的DTO尸体信息,后端对不同的实体进行映射处理即可,也可以采用同一个实体,在SqlSugar实体信息中忽略对应的字段写入实现,本篇随笔介绍后者的处理方式,实现在在工作流列表页面中增加一些转义信息的输出处理 。
1、后端的转义处理大多数页面,我们的前端显示信息DTO和后端的数据库实体信息Entity是一致的,只有部分信息的差异,特别在工作流模块中,由于继承原来历史的数据库设计结构,因此很多引用的字段是int类型的,那么为了避免前端对内容的频繁解析,因此必要的时候在后端对内容进行统一的处理,实现内容的转义 。
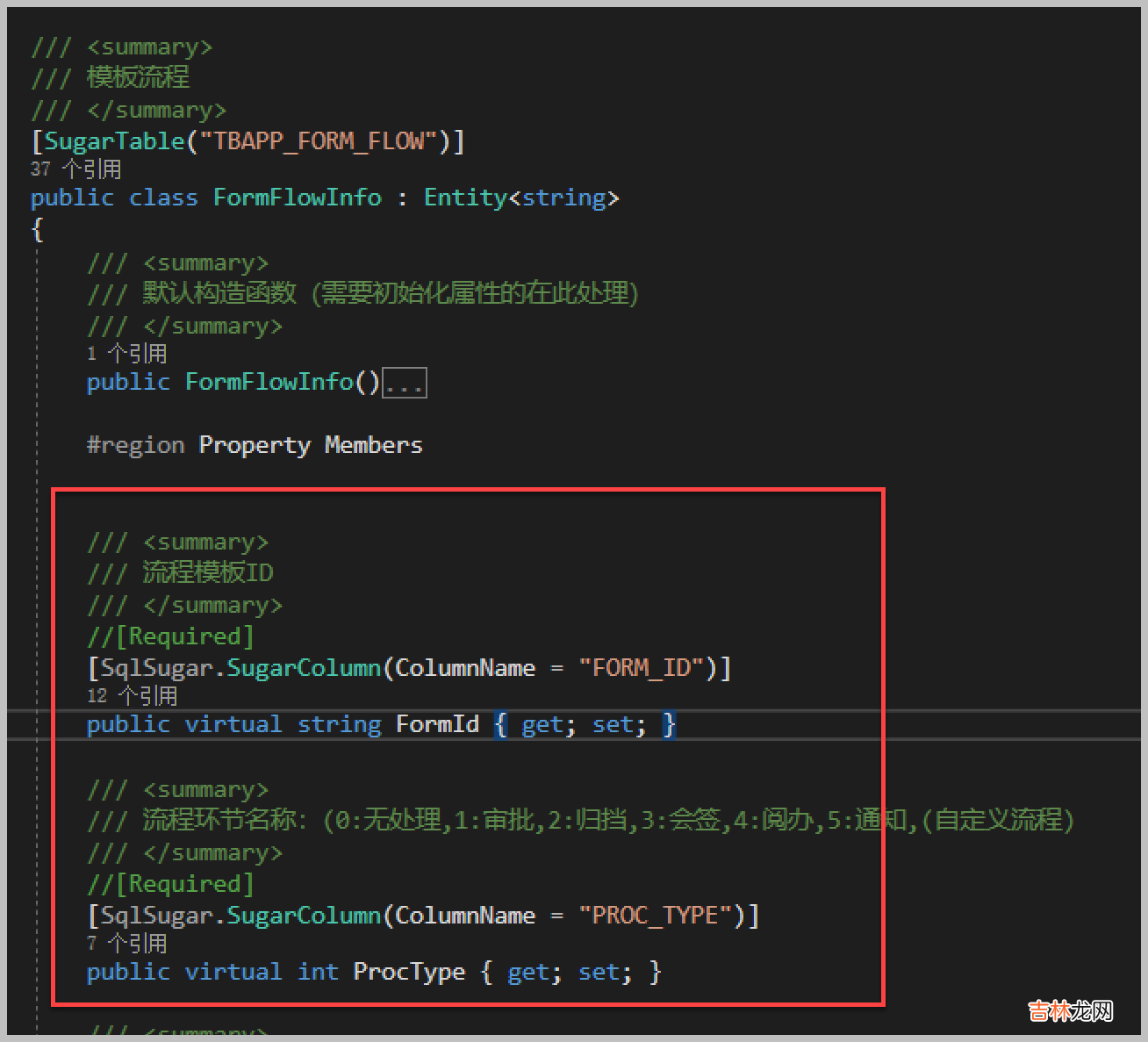
例如我们以其中的模板流程的实体信息定义来看,除了对常规的信息,我们还需要对一些转义信息的处理 。
如实体类对应字段的SqlSugar的标识,只需要增加SqlsugarColumn的标识即可 。
[SqlSugar.SugarColumn(ColumnName = "PROC_TYPE")] public virtual int ProcType { get; set; }如下所示的实体类
文章插图
如果我们需要额外增加一些信息的承载,而在保存或者提取数据库字段信息的时候,进行忽略处理,那么标识为Ignor即可 。
[SqlSugar.SugarColumn(IsIgnore = true)] public virtual string ProcTypeName { get; set; }如下实体类代码所示

文章插图
有了实体信息的定义,我们在SqlSurgar框架的服务层返回列表信息的时候,可以对列表的内容进行统一的转换,而列表返回是在基类定义的统一泛型函数,如下定义所示 。
/// <summary> /// 根据条件获取列表 /// </summary> /// <param name="input">分页查询条件</param> /// <returns></returns> public virtual async Task<PagedResultDto<TEntity>> GetListAsync(TGetListInput input) { var query = CreateFilteredQueryAsync(input); var totalCount = await query.CountAsync(); query = ApplySorting(query, input); query = ApplyPaging(query, input); var list = await query.ToListAsync(); return new PagedResultDto<TEntity>( totalCount, list ); }
经验总结扩展阅读













- 2023年1月24日安装机器吉日一览表 2023年1月24日是安装机器的黄道吉日吗
- 2023年农历正月初三安装窗帘吉日 2023年1月24日是安装窗帘的黄道吉日吗
- 2023年1月24日买车好不好 2023年1月24日是买车的黄道吉日吗
- 2023给朋友的国庆节祝福语
- 2023年1月24日收蚕黄道吉日 2023年1月24日是收蚕的黄道吉日吗
- 2023年1月24日是换门的黄道吉日吗 2023年1月24日是换门吉日吗
- 2023年1月24日安装门框黄道吉日 2023年1月24日是安装门框的黄道吉日吗
- 2023国庆节的祝福语给祖国60句
- 2023年1月24日是做生意的黄道吉日吗 2023年1月24日是做生意吉日吗
- 2023国庆给亲友的温馨祝福语63篇