文章插图
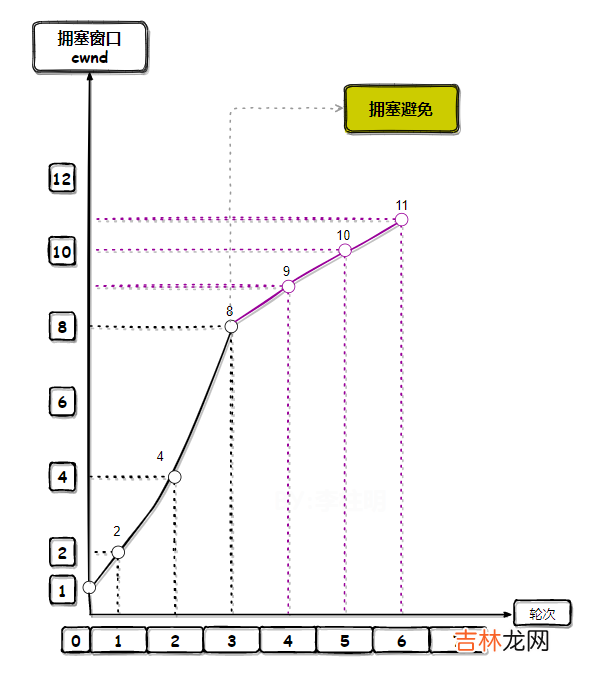
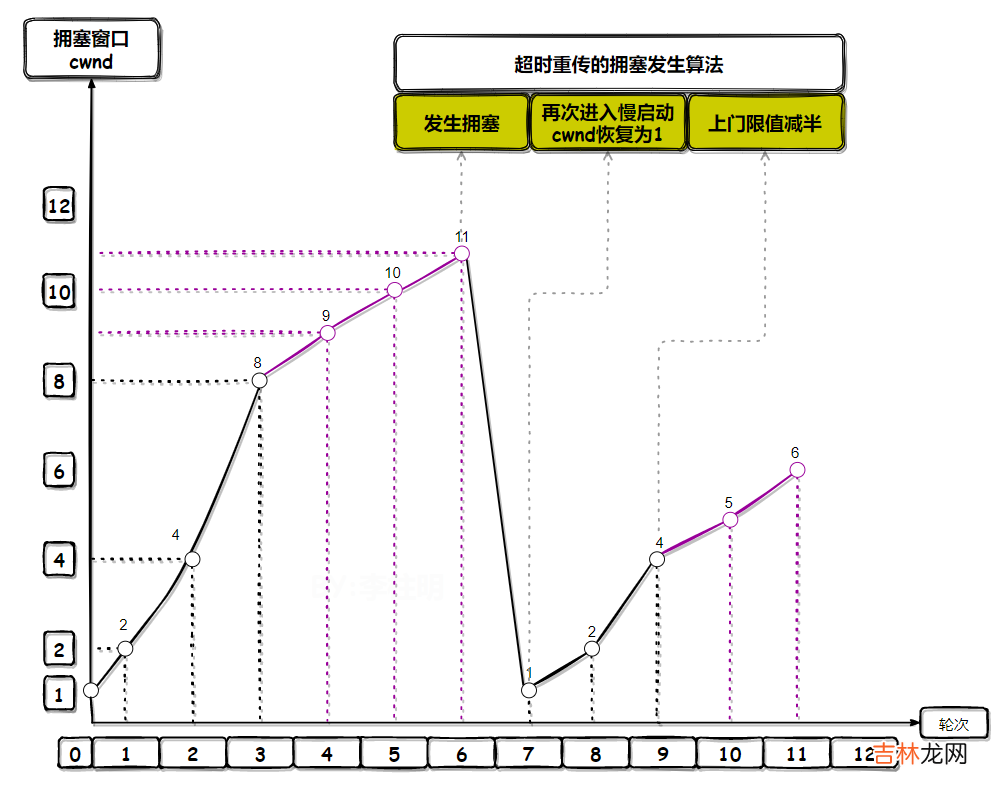
12.8.4 拥塞发生当网络出现拥塞,也就是会发生数据包重传,而重传机制主要有两种:
- 超时重传 。
- 快速重传 。
- 拥塞窗口
cwnd重置为1 。 - 慢开始上门限值
ssthresh减半 。
文章插图
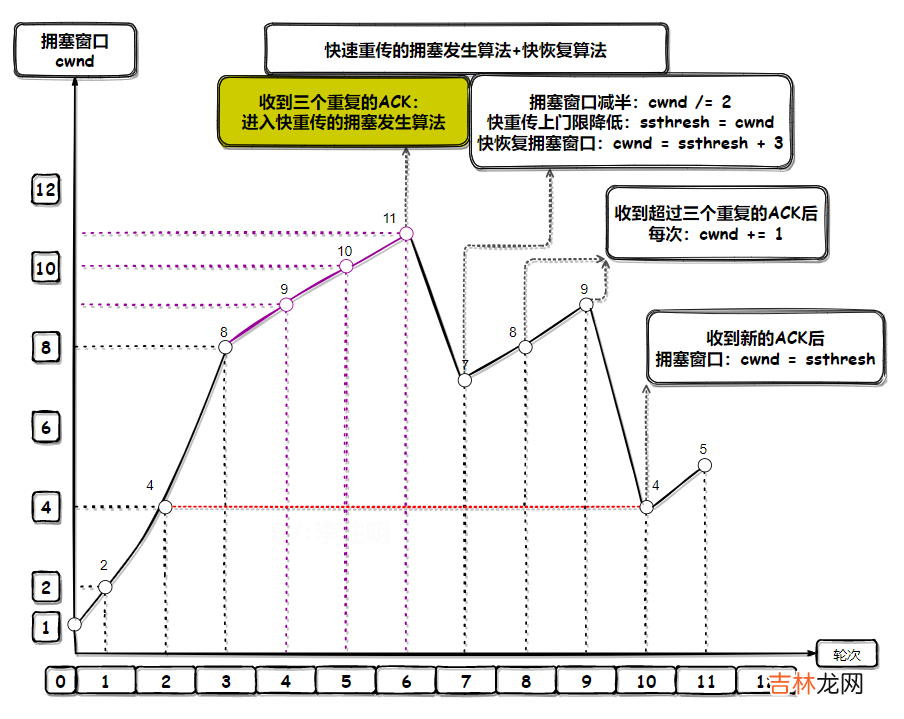
12.8.4.2 快速重传超时重传的拥塞发生算法过于激进的做法,这适合与真的发生拥塞时,但是有时候网络正常丢包,这不不是超时引起的重传,而是网络丢包引起的重传 。
当收到对端连续三次ACK同一个SEQ时,我们就能判断为发送了网络丢包,这时就不用等待超时,不用执行超时重传的拥塞算法了,而是执行快速重传的拥塞发生算法:
- 拥塞窗口
cwnd设为原来的一半:cwnd /= 2; - 慢开始上门限值
ssthresh = cwnd;(cwnd为减半后的拥塞窗口) - 进入快恢复算法 。
因为快恢复算法认为,能收到三个ACK,说明网络还不是很差,没必要像RTO一样搞得那么僵 。
快恢复算法:
- 收到第3个重复ACK时,先执行快速重传算法,然后拥塞窗口
cwnd = ssthresh + 3(3:每收到1个ACK,可以认为对端收到1次TCP包,网络上就少了1个TCP包,一个包最大为1个报文段,所以快恢复的拥塞窗口就追加3个报文段) 。 - 收到超过3个重复的ACK时,每次都会增大拥塞窗口:
cwnd += 1。 - 当收到新的ACK后:
cwnd = ssthresh。然后进入拥塞避免算法 。
文章插图
12.8.6 Nagle算法如果一个TCP报文每次只发送1个字节,这就产生了一些41字节长的分组:20字节的IP首部、20字节的TCP首部和1个字节的数据,利用率太低 。(IPV4)
解决方法就是RFC 896 [Nagle1984]中所建议的Nagle算法 。
nagle算法是提高传输效率,降低拥塞出现的可能 。
nagle算法: 尽可能组合更多数据合到同一个报文段中 。满足以下条件之一,nagle算法都不会生效:
- 用户设置了
TF_NODELAY标志 。(该标志表示关闭nagle算法) - 没有飞行中的数据,可以立即发送 。
- 报文段中还有FIN标记,可立即发送 。
- 未发送的报文段长度大于或大于一个MSS,也满足立即发送条件 。
- 发生超时,立即发送 。
所以就有了延迟确认这个算法 。
如果开启了延迟确认,在接收到TCP包后,等待一小段时间(Linux 上默认是 40ms、LWIP默认250ms),如果在这段时间内收到新的TCP包,则只需要在时间到达后确认一次即可 。
当然,遇到特殊情况可以不用等待时间到达,可以立即响应ACK:
- 收到乱序包 。
- 收到窗口外的TCP包 。
- 需要调整窗口 。
- 收到RST 。
- 发送的报文段中含有FIN 。
经验总结扩展阅读













- 哪个星座是是天蝎座的情劫
- 水表最后一位红色是1吨还是0.1吨
- 龙舌兰酒为什么不能直接喝
- 长虫是什么动物
- 烈火军校董小姐扮演者是谁?
- 牛仔裤38码是多少尺?
- 小丑女的电影是哪一个?
- 唐艺昕演的穿越剧叫什么名字?
- 霉茶叶有什么用途
- bollycon是哪个国家的美瞳品牌?