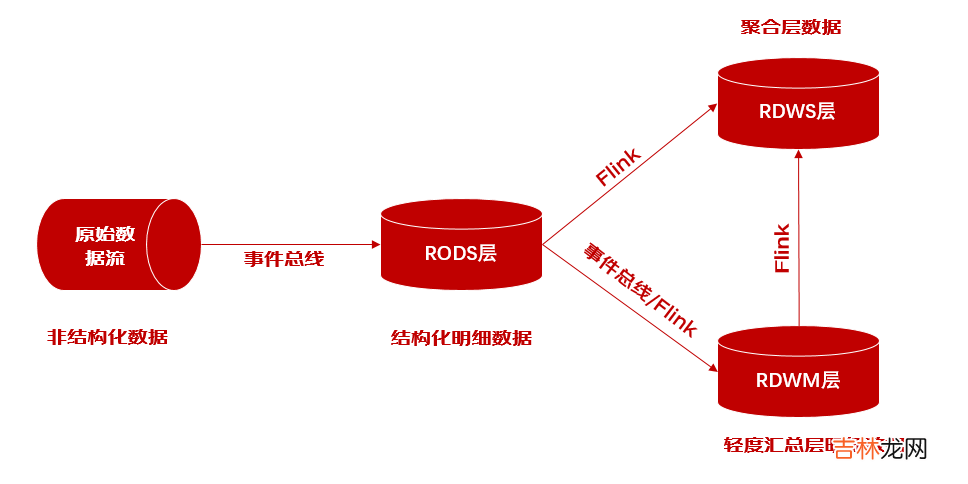
层级缩短: 首先, 风险数据模型采用短链路架构设计,从RODS层可直接通过Flink构建RDWM层与RDWS层,重视层级缩短, 降低数据延迟; clickhouse作为分层数据载体, 可根据业务需求提供不同层级的数据查询服务, 当然基于性能的考虑推荐业务尽量使用第二层或第三层数据.
文章插图
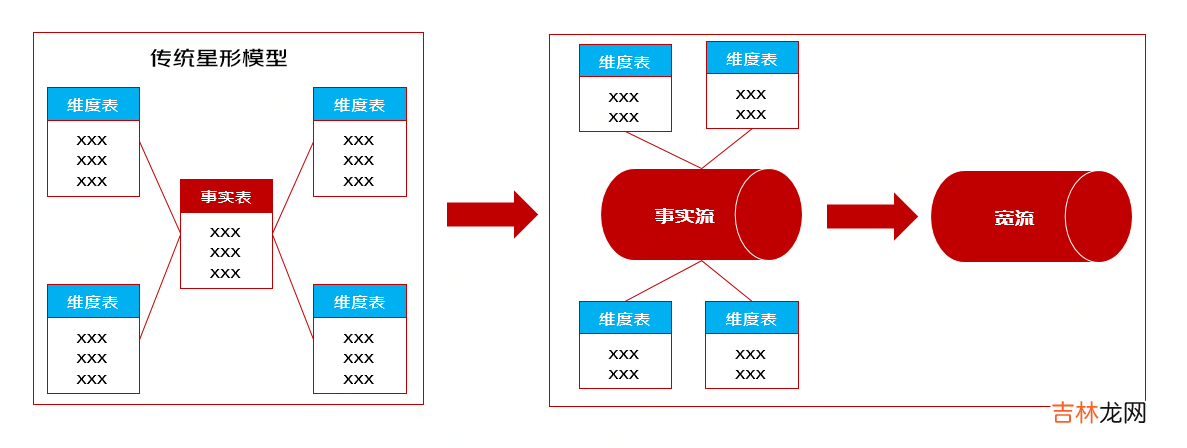
维度退化: 传统数仓中查询会涉及事实表与维度表之间的关联, 该操作会带来复杂的性能调优问题. 为了发挥clickhouse单表计算优势, 尽量多的将常用维度字段退化到事实表中,形成宽表供业务方来使用. 减少联查带来的性能效率问题.
文章插图
Flink预聚合: 结合Flink实时计算引擎实现海量数据风险指标秒级或分钟级周期预聚合计算, 降低下游计算成本, 尤其在大促环境时期, 通过预聚合手段能够显著提高clickhouse计算能力
四、风险洞察-clickhouse的实践应用介绍完clickhouse参与的架构设计理念, 接下来结合具体实践场景来介绍下clickhouse在使用中遇到的问题与优化方案.
营销反欺诈场景大促实践背景: 营销反欺诈作为风控体系中的重要场景, 其原始数据流具备两大特点: 1. 消息体庞大且复杂, 包含多种数据结构, 但MQ消息体大小达17kb; 2. 消息流量大, 营销数据日常流量在1w/s左右, 在2021双11大促时期峰值更是达到60w/s, 为日常流量的60倍. 因数据需要支撑实时看板监控与预警, 所以如何保证数据写入的吞吐量与数据查询的及时性是极具挑战的问题.
初始设计: 通过消费原始消息流, 通过事件总线写入clickhouse.
问题发现:
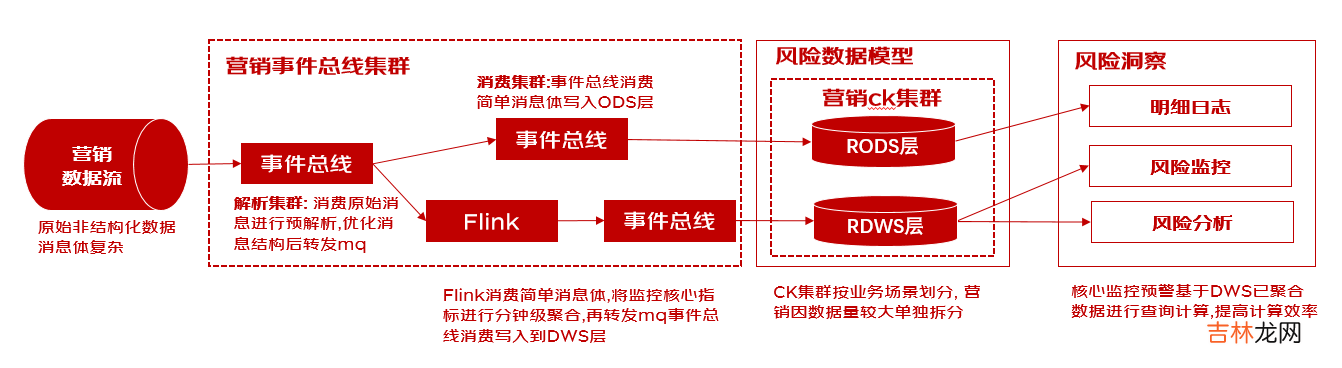
1.消费能力不足: 营销的消息体较为复杂, mq消息序列化反序列化操作耗费大量cpu, 吞吐量瓶颈在于消息解析2.clickhouse写入异常: 在海量数据场景下会造成多频少批的写入, 导致ck服务端生成大量小文件, 文件merge时消耗服务端大量cpu与io, 不足以支持写入频次导致抛出异常3.clickhouse查询异常: 大促时期数据查询与写入场景增多, 导致超过ck集群最大并发数限制, 抛出异常.4.clickhouse计算效率下降: 大促时期海量数据背景下, 基于海量明细数据的监控指标范围内数据量激增, 影响一定的计算效率架构改造:
文章插图
改造点1: 分而治之, 集群拆分解耦
1.消费集群拆分, 事件总线按照业务维度, 职责维度进行深度拆分, 将有远高于其他场景的营销流量单独拆分解耦, 再根据解析, 入库职责进一步拆分集群, 实现解析集群机器cpu利用最大化, 并降低下游如Flink计算, 事件总线入库的cpu压力.提高消费效率2.clickhouse集群拆分, clickhouse按照业务维度进行单独拆分, 总共拆分出4大ck集群: 交易集群、营销集群、信用集群、混合集群. 营销场景承担着更大的存储与更高频次的写入, 与其他业务解耦可以更好的提高ck集群的并发量与计算效率改造点2: 因势利导, 动态的写入策略
1.clickhouse集群数据写入规则在消费端进行封装优化, 支持按批量条数,批量大小,定时间隔的策略进行批量写入,对不同场景不同流量的数据进行写入规则调节适配,发挥ck大批量写入的同时也保证数据的实时性.改造点3: 化繁为简, 预聚合
1.原始消息经过解析集群规整富化后, 消息体大小缩减10倍, 再由Flink集群基于核心指标进行分钟级聚合,最终写入到RDWS层,规模相较于RODS层减少95%, 大幅提高ck查询效率用户行为路径查询实践背景: 行为路径分析能够帮助分析师洞察出某一类用户在各个主题事件间的路径分布特性 。可依次通过人群筛选与路径筛选来得到目标人群与目标路径,再将筛选结果及相应的数据通过桑基图或排行榜的方式来呈现. 所以用户行为路径面临着海量数据如何高效查询、指标计算等问题
经验总结扩展阅读













- 爱上一个人 不在意别人眼光的星座
- 2023年1月23日适合进货吗 2023年1月23日进货好不好
- 2023年1月23号财神在哪方 每日财神方位查询
- 属牛和属狗的合不合财运 属狗和属牛的在一起财运好吗
- 小米电视黑屏故障如何解决 小米电视故障率
- 2022光遇天空王国在什么地方
- iphone12录屏在哪里_iphone12录屏功能在哪儿
- 义乌服装库存尾货市场在哪里
- 现在什么快消品行业最好做
- 2023年1月23日是打官司吉日吗 2023年1月23日是打官司的黄道吉日吗