2 Method2.1 Definition本文将谣言检测定义为一种分类任务,其目的是从一组带标签的训练事件中学习一个分类器,然后用它来预测测试事件的标签 。使用 $C=\left\{c_{1}, c_{2}, \cdots, c_{n}\right\}$ ,$c_{i}$ 是第 $i$ 个事件, $n$ 是事件的数量 。每个事件 $c=(y, G)$ 包含 ground-truth 标签 $y \in\{R, N\}$ (也就是 Rumor 和 Non-rumor) 和其传播结构树 $G=(V, E)$ ,$V$ 和 $E$ 分别是节点和边的集合 。有时谣言检测被定义为一个四类的分类任务,相应的 $y \in\{N, F, T, U\}$ ( Non-rumor、False Rumor、True Rumor、Unverified Rumor) 。在模型训练阶段,$\hat{G}$ 由数据增强生成,目的是与原图 $G$ 一起学习一个分类器 $f(\cdot)$ 。在测试阶段,只有原图 $G$ 会被用来预测给定事件 $c_{i}$ 的标签 。
2.2 Framework
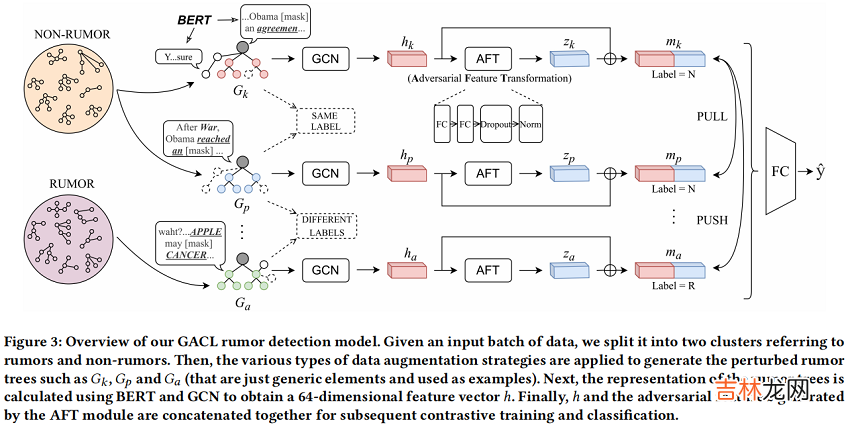
文章插图
2.3 Graph Data AugmentationGACL采用 Edge perturbation 策略进行数据增强 。对于一个图 $G=(V, E) $ ,其邻接矩阵为 $A$ ,特征矩阵为 $X$ ,Edge perturbation 在训练时将会根据一定的概率 $r$ 来随机丢弃、 添加或者误置一些边,以此来干扰 $G$ 的连接 。假设新生成的增强图为 $\hat{G}^{\prime}$,$A_{\text {perturbation }}$ 为一 个从原来的边集合中随机采样的矩阵,则 $\hat{G}$ 的邻接矩阵 $A^{\prime}$ 可以计算为对谣言制造者设计的伪装结构 。
此外,对于谣言检测任务,上图中由 $post$ 组成的图节点的文本信息也是正确分类谣言的关键线索之一,还需要对其进行增强以提供一些噪声 。本文采用 Dropout mask 来对这些文本进行增强,也就是随机 mask 每个 post 中的一些词,如上图所示 。
2.4 Graph Representation本文使用 BERT 来获取事件的原文和评论的句子表示,以构建新的 $X$。为了强调 source post 的重要性,以 [CLS] Source [SEP] Comment [SEP] 的形式来将原文和评论连接起来,以 [CLS] 这个 token 的最终表示作为节点的表示 。
本文使用一个两层$\mathrm{GCN}$作为encoder。当前图记为$G_{k} $ ,其增强图为$\hat{G}_{k}$,经过两层$\mathrm{GCN}$后学习到的节点表示矩阵为$H_{k}^{(2)}$,最后使用一个 mean-pooling 来获得图的表示:
$h_{k}=M E A N\left(H_{k}^{(2)}\right)$
2.5 AFT Component即使 AFT module 不存在,由 GCN 生成的图表示 $h$ 也可以直接输入最终的 $softmax$ 层进行谣言分类 。然而,由于该模型在训练阶段只暴露于包含随机噪声的数据增强生成的输入样本中,因此它缺乏对对抗性样本(特别是一些被人类仔细干扰的数据)的鲁棒性,如 Figure1(c). 所示为了逃避模型检测,谣言产生者可能会使用图伪装策略,使会话线程更接近非谣言实例,从而混淆了图检测模型 。他们也可以利用谣言机器人来发布大量的评论,其中包含许多高频和指示性的词,以掩盖事实 。这些案例的最终目标是使谣言特征向量更接近于潜在空间中的非谣言特征向量 。提出的基于对抗学习的 AFTmodule 试图在高维空间中模拟这些行为,并生成对抗向量,用于挖掘训练阶段的事件不变特征 。如 Figure 3 所示,AFT 由 $L = 2$ fully connected layers、Dropout 和 Normalization (DN) 组成 。经过 AFT module 后,$h_k$ 转换为 $z_k$,公式为
$z_{k}=D N\left(\max \left(0, h_{k} W_{1}^{A F T}+b_{1}\right) W_{2}^{A F T}+b_{2}\right)$
将得到的 $z_k$ 向量作为对比学习中的硬负样本 。
现在,对于 batch 中的每一个 post,我们得到了 GCN 编码的相应图表示 $h_{k}$,以及 AFT 生成的对抗表示 $z_{k}$ 。然后,我们将它们连接起来,以将信息合并为
经验总结扩展阅读











- 非典为什么只感染华人?
- 吃鸡怎么举报100让对方被检测?
- 水质检测到哪里
- 安检门能检测什么东西
- 口罩如何检测是否合格
- 标致308电脑检测口在哪里?
- 比亚迪s6检测不到钥匙怎么办?
- 胶金体检测是什么意思
- 核酸检测阴性是指什么
- 胶体金检测什么意思