$m_{k}=\operatorname{concat}\left(h_{k}, z_{k}\right)$
【GACL 谣言检测《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》】接下来,将 $m_{k}$ 输入全连接层和 softmax 层,输出计算为
$\hat{y}_{k}=\operatorname{softmax}\left(W_{k}^{F} m_{k}+b_{k}^{F}\right)$
其中,$\hat{y} \in \mathbb{R}^{1 \times C}$ 为预测的概率分布 。$W^{F}$ 和 $b^{F}$ 分别为可训练的权重矩阵和偏差 。
2.6 Adversarial Contrastive Learning本文采用的损失函数旨在给定标签信息的条件下最大化正样本之间的一致性同时拉远负样本 。如 Figure 3 ,以 $m_{k}$ 作为锚点,具备与 $m_{k}$ 相同标签的 $m_{p}$ 作为正样本,具备与 $m_{k}$ 不同标签的 $m_{a}$ 作为负样本 。对比损失的目的是让具有相同标签的样本余弦相似度变大,具有不同标签的样本余弦相似度变小 。最终的损失函数为:
$\mathcal{L}=\mathcal{L}_{c e}+\alpha \mathcal{L}_{s u p}$
这两部分损失分别是:
$\mathcal{L}_{c e}=-\frac{1}{N} \sum\limits ^{N} \sum\limits^{M} y_{k, c} \log \left(\hat{y}_{k, c}\right)$
${\large \mathcal{L}_{s u p}=-\sum\limits _{k \in K} \log \left\{\frac{1}{|P(k)|} \sum\limits _{p \in P(k)} \frac{\exp \left(\operatorname{sim}\left(m_{k}, m_{p}\right) \tau\right)}{\sum\limits _{a \in A(k)} \exp \left(\operatorname{sim}\left(m_{k}, m_{a}\right) \tau\right)}\right\}} $
$k$ 代表第几个样本,$c$ 代表类别, $A(k)=\left\{a \in K: y_{a} \neq y_{k}\right\}$ 是负样本索引,$P(k)=\left\{p \in K: y_{p}=y_{k}\right\}$ 是正样本索引, $\operatorname{sim}(\cdot)$ 为余弦相似度,即 $\operatorname{sim}\left(m_{k}, m_{p}\right)=m_{k}^{T} m_{p} /\left\|m_{k}\right\|\left\|m_{p}\right\|$ ,$\tau \in \mathbb{R}^{\dagger}$ 是温度超参数 。
一部分研究表明BERT驱动的句子表示容易造成坍塌现象,这是由于句子的语义信息由高频词主导 。在谣言检测中,高频词经常被谣言制造者利用来逃避检测 。因此采用对比学习的方式能够 平滑化句子的语义信息,并且理论上能够增加低频但重要的词的权重 。本文通过最小化 $\mathcal{L}$ 来更新模型的参数,但不包括 AFT 的参数 。
AFT 基于对抗学习单独训练 。模型中 AFT 的参数记作$\theta_{a}$,其他参数记作$\theta_{s}$。在每一个 epoch 中,我们最小化$\mathcal{L}$来更新$\theta_{s}$,最大化\mathcal{L}来更新\theta_{a}。我们利用对抗学习来最小化对抗样本与相同标签样本的一致性,最大化对抗样本与不同标签样本的一致性 。整个算法如下:

文章插图
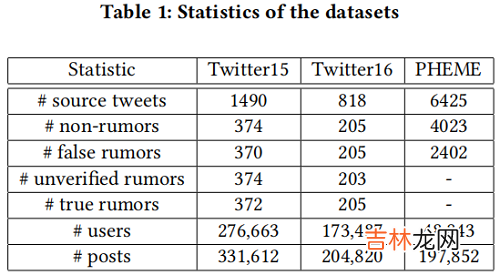
3 ExperimentDatasets
文章插图
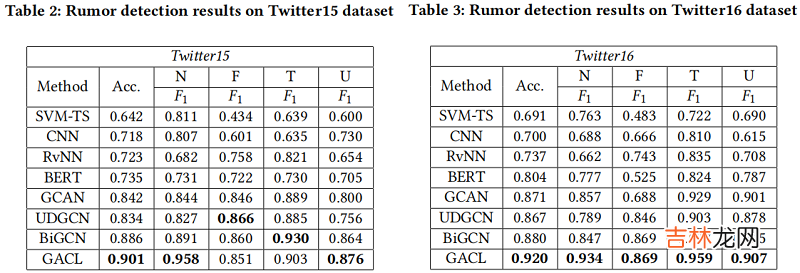
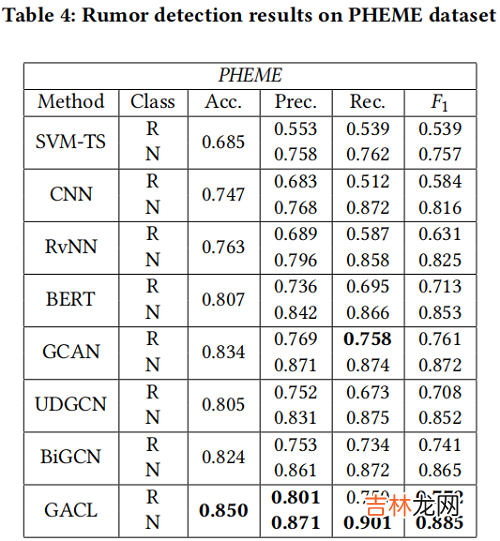
Results
文章插图
文章插图
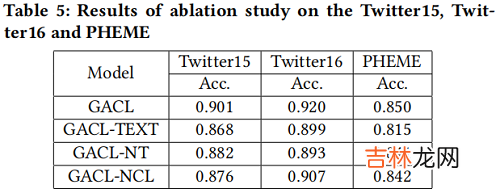
Ablation study
文章插图
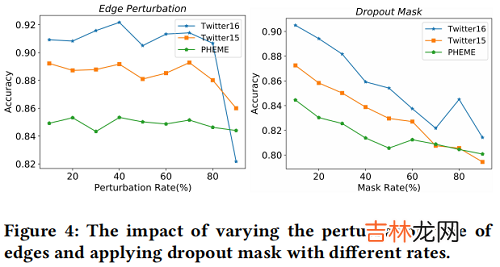
文章插图
Early Rumor Detection
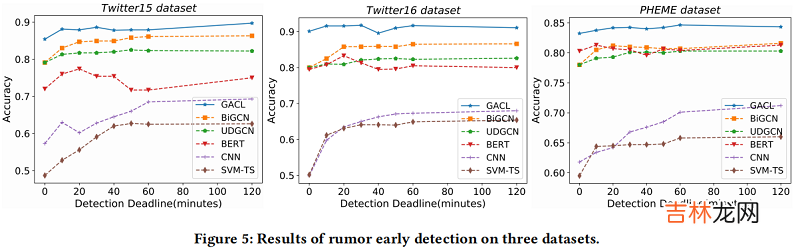
文章插图
4 Conclusion本文提出了一种新的谣言检测模型,即GACL 。首先,采用训练前模型BERT获得GACL中每个帖子的表示,然后使用GCN对谣言传播的结构信息进行编码 。其次,引入对比学习,通过捕获同一类实例之间的共性和不同类实例之间的差异来提高表示的质量 。最后,将AFT模块加载到模型中,采用对抗性学习策略进行训练,以生成对抗性特征 。这些对抗性特征在对比学习中作为硬负样本,并在训练阶段作为输入向量的一部分输入到softmax模块中,有利于捕获事件不变特征 。实验结果表明,我们的GACL方法对三个公共真实数据集的谣言检测具有良好的有效性和鲁棒性,并且在早期谣言检测任务中显著优于其他最先进的模型 。
经验总结扩展阅读
















- 非典为什么只感染华人?
- 吃鸡怎么举报100让对方被检测?
- 水质检测到哪里
- 安检门能检测什么东西
- 口罩如何检测是否合格
- 标致308电脑检测口在哪里?
- 比亚迪s6检测不到钥匙怎么办?
- 胶金体检测是什么意思
- 核酸检测阴性是指什么
- 胶体金检测什么意思