数据节点会有不同的阶段,可能是一个存储热数据的节点,也可能是一个存储温数据、冷数据,甚至极冷数据的节点 。需要根据节点的功能去给他分配不同的角色,同时会给不同的角色的节点配置不同的硬件 。
比如,对于热数据节点需要配置高性能的 CPU 或者磁盘,对于温冷数据的节点,基本上认为这些数据被查询的频率较低,这个时候其实对于某些计算资源的硬件要求就没有那么高了 。
【JuiceFS 在 Elasticsearch/ClickHouse 温冷数据存储中的实践】节点角色是根据生命周期的不同阶段来定义的,需要注意的一点是,每一个 ES 节点,可以有多种角色,这些角色并不是一一对应的关系 。下面有个示例,在 ES 的 YAML 文件里面配置的时候,node.roles 就是节点角色的配置,可以针对这个节点应该有的角色给它配置多种角色 。
node.roles: ["data_hot", "data_content"]生命周期策略在了解完 Data Stream 、Index Lifecycle Management、Node Role 这些概念以后,就可以为数据创建一些不同的生命周期策略(Lifecycle Policy) 。
根据生命周期策略中定义的不同维度的索引特征,如索引的大小、索引里的文档的数量、索引创建的时间,ES 可以自动地帮用户把某个生命周期阶段的数据滚动到另一个阶段,在 ES 中的术语是 rollover 。
比如,用户可以制定基于索引大小维度的特征,把热数据滚动到温数据,或者根据一些其它规则,再把温数据滚动到冷数据 。这样,索引在不同生命周期的阶段之间去滚动的时候,相应的它索引的数据也会去做迁移和滚动 。ES 可以自动完成这些工作,但是生命周期策略则需要用户自己来定义 。
下面的截图,是 Kibana 的管理界面,用户可以通过图形化的方式去配置生命周期策略 。可以看到有三个阶段,从上到下分别是热数据、温数据以及冷数据 。
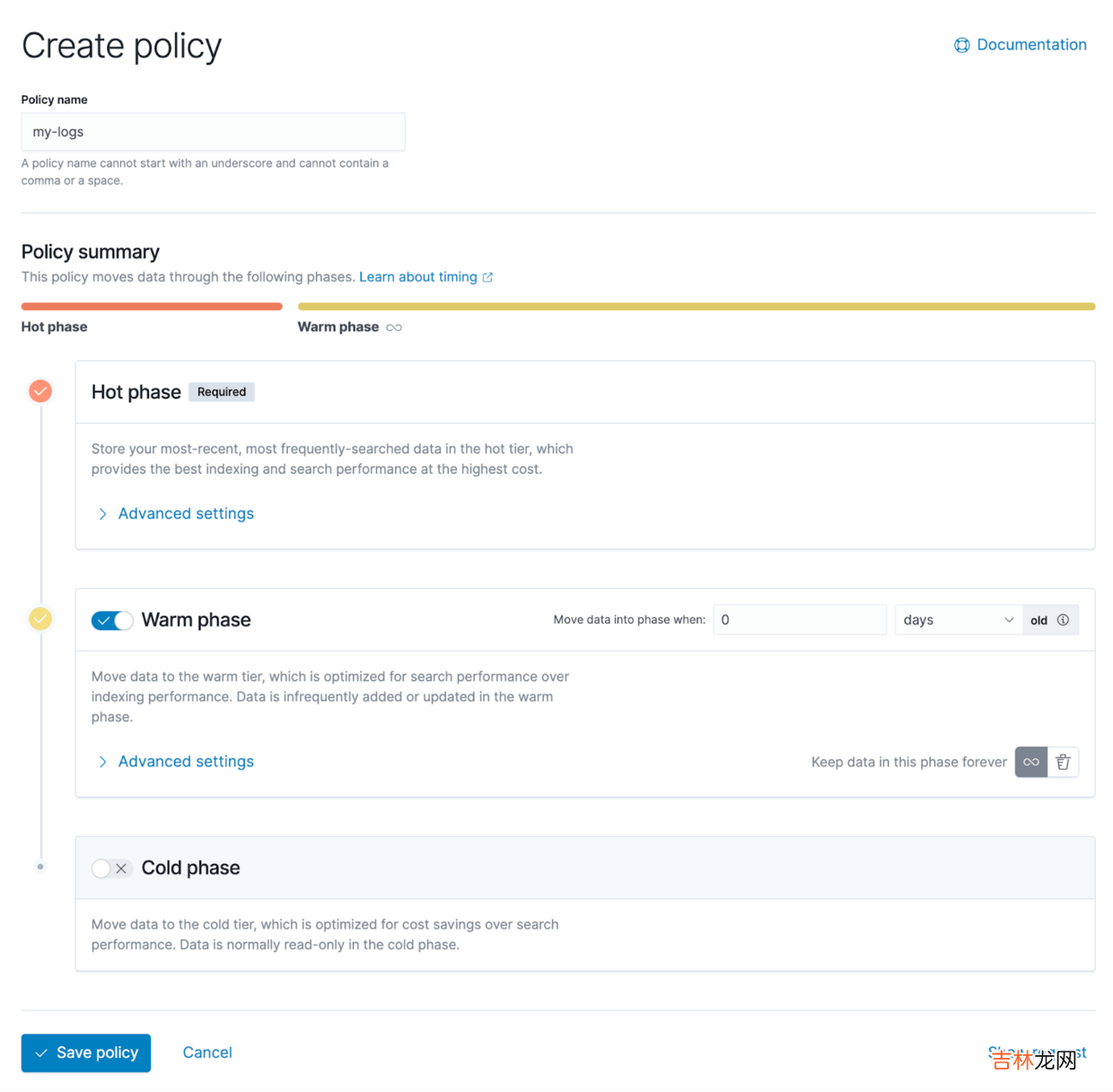
文章插图
展开其中热数据阶段的高级设置,可以看到更详细,上文提到的基于不同维度特征的策略配置,如在下图右边看到的这三个选项 。
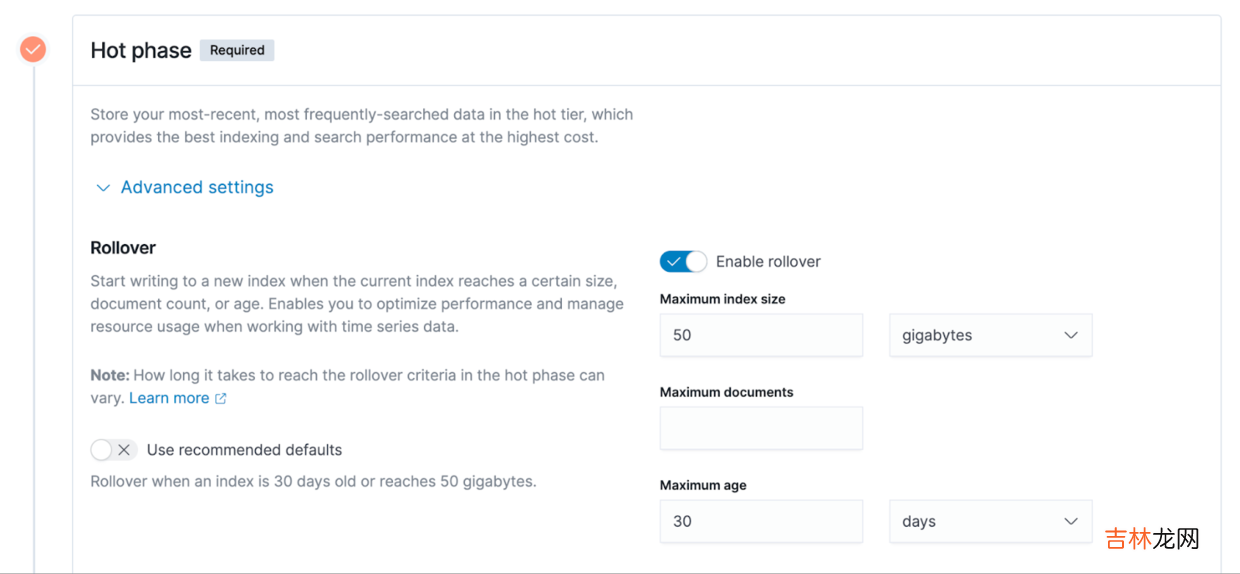
文章插图
- 索引的大小,示意图上的例子是 50GB,当索引的大小超过 50GB 的时候,就会把它从热数据阶段滚动到温数据阶段 。
- 最大的文档数,ES 里索引的单元是文档,用户数据是以文档的形式写入 ES 中的,所以文档数也是一个可以衡量的指标 。
- 最大索引创建时间,这里的示例是 30 天,假设某个索引已经创建了 30 天了,这个时候就会触发刚刚提到的从热数据阶段到温数据的滚动 。
- Table: 在图片的最右边是一个最大的概念,用户最开始要创建或者能够直接接触到的就是 Table;
- Partition:是一个更小的维度或者更小的粒度 。在 ClickHouse 里,数据分成 Partition 来存储,每个 Partition 会有一个标识;
- Part:在每个 Partition 中,又会再进一步地细分为多个 Part 。如果查看 ClickHouse 磁盘上存储的数据格式,可以认为每一个子目录就是一个 Part;
- Column:在 Part 里会看到一些更小粒度的数据,即 Column 。ClickHouse 的引擎使用的是列式存储,所有的数据都是按照列存的方式来组织 。在 Part 目录里会看到很多列,比如 Table 可能有100 列,就会有 100 个 Column 文件;
- Block:每个 Column 文件里是按照 Block 的粒度来组织 。
经验总结扩展阅读
















- 花园蚊子多有什么办法
- 2023年10月21日打官司行吗 2023年10月21日适合打官司吗
- 2023年10月21日进货行吗 2023年10月21日进货好吗
- 合欢花花语
- 华为怎么在手机桌面上创建文件夹
- 嘀嗒出租车怎么注册
- 拯救者Y7000P独显模式和混合模式对比
- 爬蚱几点到几点最多
- 小腹胖是什么原因
- 锁芯一般在哪里有卖