企业数据越存越多,存储容量与查询性能、以及存储成本之间的矛盾对于技术团队来说是个普遍难题 。这个难题在 Elasticsearch 与 ClickHouse 这两个场景中尤为突出,为了应对不同热度数据对查询性能的要求,这两个组件在架构设计上就有一些将数据进行分层的策略 。
同时,在存储介质方面,随着云计算的发展,对象存储以低廉的价格和弹性伸缩的空间获得了企业的青睐 。越来越多的企业将温、冷数据迁移至对象存储 。但如果将索引、分析组件直接对接至对象存储时会发生查询性能、兼容性等问题 。
这篇文章将为大家介绍这两个场景中冷热数据分层的基本原理,以及如何通过使用 JuiceFS 来应对在对象存储上存在的问题 。
01- Elasticsearch 数据分层结构详解在介绍 ES 如何实现冷热数据分层策略之前先来了解三个相关的概念:Data Stream,Index Lifecycle Management 和 Node Role 。
Data StreamData Stream(数据流)是 ES 中一个重要概念,它有如下特征:
- 流式写入:它是一个流式写入的数据集,而不是一个固定大小的集合;
- 仅追加写:它是用追加写的方式将数据更新进去,且不需要修改历史数据;
- 时间戳:每一条新增的数据都会有一个时间戳记录是什么时候产生的;
- 多个索引:在 ES 里有一个索引的概念,每一条数据最终会落到它对应的一个索引中,但是数据流是一个更上层、更大的概念,一个数据流背后可能会有很多索引,这些索引是根据不同的规则来生成的 。一个数据流虽然由很多的索引来构成,但是只有最新的索引才是可写的,历史索引是只读的,一旦固化好之后就不能再修改 。
下图是一个数据流建立索引的简单示例,在用数据流的过程中,ES 会直接写到最新的索引,而不是历史索引,历史索引不会被修改 。随着后续更多新的数据生成,这个索引也会沉淀成为一个老的索引 。
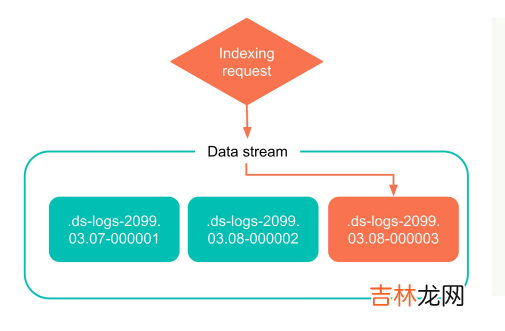
文章插图
下图,当用户往 ES 里面去写数据时,大致分为两个阶段:
- 阶段 1:数据会先写到内存的 In-memory buffer 缓冲区;
- 阶段 2:缓冲区根据一定的规则和时间,再落到本地磁盘上,就是下图绿色的持久化的数据,在 ES 中叫做 Segment 。

文章插图
Index Lifecycle ManagementIndex Lifecycle Management,简称 ILM,就是索引的生命周期管理 。ILM 将索引的生命周期定义为 5 个阶段:
- 热数据(Hot):需要频繁更新或者查询的数据;
- 温数据(Warm):不再更新,但仍会被频繁查询的数据;
- 冷数据(Cold):不再更新,且查询频率较低的数据;
- 极冷数据(Frozen):不再更新,且几乎不会被查询的数据 。可以比较放心地把这类数据放在一个相对最低速最便宜的存储介质中;
- 删除数据(Delete) : 不再需要用到,可以放心删除的数据 。
Node Role在 ES 中,每一个部署节点都会有一个 Node Role,也就是节点角色 。每一个 ES 节点会分配不同的角色,比如 master、data、ingest 等 。用户可以结合节点角色,以及上文提到的不同生命周期的阶段来组合进行数据管理 。
经验总结扩展阅读
















- 花园蚊子多有什么办法
- 2023年10月21日打官司行吗 2023年10月21日适合打官司吗
- 2023年10月21日进货行吗 2023年10月21日进货好吗
- 合欢花花语
- 华为怎么在手机桌面上创建文件夹
- 嘀嗒出租车怎么注册
- 拯救者Y7000P独显模式和混合模式对比
- 爬蚱几点到几点最多
- 小腹胖是什么原因
- 锁芯一般在哪里有卖