论文信息
论文标题:Debunking Rumors on Twitter with Tree Transformer论文作者:Jing Ma、Wei Gao论文来源:2020 , COLING论文地址:download 论文代码:download1 Introduction出发点:Existing conversation-based techniques for rumor detection either just strictly follow tree edges or treat all the posts fully-connected during feature learning.
【谣言检测——《Debunking Rumors on Twitter with Tree Transformer》】创新点:Propose a novel detection model based on tree transformer to better utilize user interactions in the dialogue where post-level self-attention plays the key role for aggregating the intra-/inter-subtree stances.
例子:以 PLAN 模型为例子——一种帖子之间全连接的例子
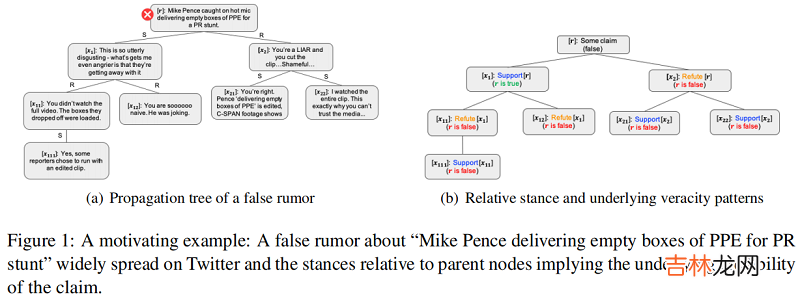
文章插图
结论:Post 之间全连接的模型只适合浅层模型 , 并不适合深层模型 , 这是由于 Post 一般只和其 Parent 相关吗 , 全连接导致 Post 之间的错误连接加重 。
2 Tree Transformer Model总体框架如下:

文章插图
2.1 Token-Level Tweet RepresentationTransformer encoder 框架:
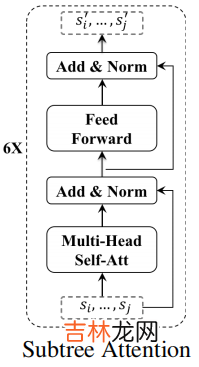
文章插图
给定一条表示为 word sequence $x_{i}=\left(w_{1} \cdots w_{t} \cdots w_{\left|x_{i}\right|}\right)$ 的推文 , 每个 $w_{t} \in \mathbb{R}^{d}$ 是一个 $d$ 维向量 , 可以用预先训练的单词嵌入初始化 。我们使用多头自注意网络(MH-SAN)将每个 $w_{i}$ 映射到一个固定大小的隐藏向量中 。MH-SAN 的核心思想是共同关注来自不同位置的不同表示子空间的单词 。更具体地说 , MH-SAN 首先将输入字序列 $x_i$ 转换为具有不同线性投影的多个子空间:
$Q_{i}^{h}, K_{i}^{h}, V_{i}^{h}=x_{i} \cdot W_{Q}^{h}, \quad x_{i} \cdot W_{K}^{h}, \quad x_{i} \cdot W_{V}^{h} \quad\quad\quad(1)$其中 , $\left\{Q_{i}^{h}, K_{i}^{h}, V_{i}^{h}\right\}$ 分别为 query、key 和 value representations , $\left\{W_{Q}^{h}, W_{K}^{h}, W_{V}^{h}\right\} $ 表示与第 $h$ 个头关联的参数矩阵 。然后 , 应用 attention function 来生成输出状态 。
$O_{i}^{h}=\operatorname{softmax}\left(\frac{Q_{i}^{h} \cdot K_{i}^{h^{\top}}}{\sqrt{d_{h}}}\right) \cdot V_{i}^{h} \quad\quad\quad(2)$
其中 , $\sqrt{d_{h}}$ 是 放缩因子 , $d_{h}$ 表示第 $h$ 个头的子空间的维数 。最后 , 表示的输出可以看作是所有头 $O_{i}=\left[O_{i}^{1}, O_{i}^{2}, \cdots, O_{i}^{n}\right] \in \mathbb{R}^{\left|x_{i}\right| \times d}$ 的连接 , $n$ 为头数 , 然后是一个归一化层(layerNorm)和前馈网络(FFN) 。
$\begin{array}{l}B_{i}=\operatorname{layerNorm}\left(O_{i} \cdot W_{B}+O_{i}\right) \\H_{i}=\operatorname{FFN}\left(B_{i} \cdot W_{S}+B_{i}\right)\end{array} \quad\quad\quad(3)$
其中 $H_{i}=\left[h_{1} ; \ldots ; h_{\left|x_{i}\right|}\right] \in \mathbb{R}^{\left|x_{i}\right| \times d}$ 是表示 tweet $x_i$ 中所有单词的矩阵 , $W_{B}$ 和 $W_{h}$ 包含 transformation 的权值 。最后 , 我们通过 maxpooling 所有相关 words 的向量 , 得到了 $x_i$ 的表示:
$s_{i}=\max -\operatorname{pooling}\left(h_{1}, \ldots, h_{\left|x_{i}\right|}\right) \quad\quad\quad(4)$
其中 , $s_{i} \in \mathbb{R}^{1 \times d}$ 为 $d$ 维向量 , $|\cdot|$ 为单词数 。
2.2 Post-Level Tweet RepresentationWhy we choose Cross-check all the posts in the same subtree to enhance the representation learning:(1) posts are generally short in nature thus the stance expressed in each node is closely correlated with the responsive context;
经验总结扩展阅读














- 一 CPS攻击案例——基于脉冲宽度调制PWM的无人机攻击
- 一篇文章带你掌握主流服务层框架——SpringMVC
- 如何检测手机
- Linux命令系列之top——里面藏着很多鲜为人知的宝藏知识
- 2 Libgdx游戏开发——接水滴游戏实现
- 水质检测笔多少为正常
- 1 Libgdx游戏学习——环境配置及demo运行
- 翅尖有毒是谣言吗
- 一篇文章带你掌握主流基础框架——Spring
- Go设计模式学习准备——下载bilibili合集视频