
文章插图
如:
1、gremlin
g.V("李雷").outE('friend').has('age',gt(30)).otherV().where(out('friend').(hasId('李雷'))).limit(100)2、cypher
match (a)-[r1:friend]->(b)-[r2:friend]->(c) where a.mid='李雷' and r1.age>30 and a=c return id(b) limit 100以上两种写法等价 , 只是使用的图查询语言有区别 。
图算法除了明确规则的查询外 , 我们也可以利用图算法对图进行分析 。毕竟图中蕴含的信息量远比表面看上去多 , 这个时候我们希望通过图算法揭示图中更多的信息 , 如发现节点之间隐含关系 , 分析节点重要性 , 对业务场景进行行为预测等 。
下表列出了目前不同类型具有代表性的图算法:
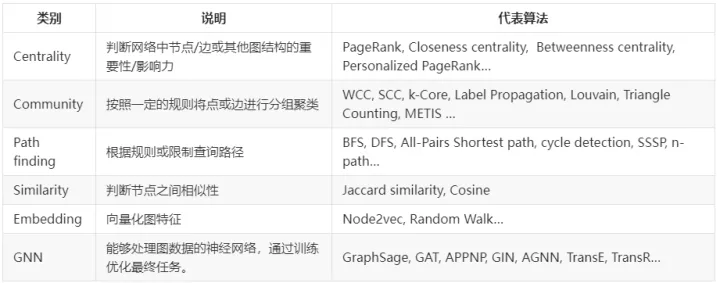
文章插图
实际的场景中 , 我们需要同时兼顾算法的效果和执行成本 。这也是很多使用场景所面临的trade-off问题 。正如我们前面所说 , 大部分情况下不需要用到非常高深的图算法 , 特别是在在线任务中 , 我们更看重时延和效率 。
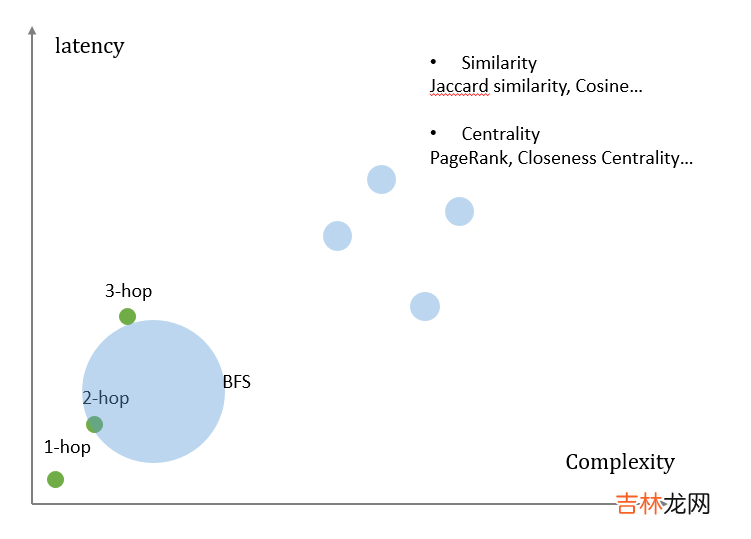
文章插图
亦或者说 , 在线场景中 , 重查询轻算法;而在离线场景中 , 重算法而轻查询 。
事实上 , 图查询与图算法的边界并没有那么泾渭分明 。或者说 , 图算法算是某种程度上的特殊图查询 。我们普遍认为算法较查询需要更多的计算资源 , 会占用更多的CPU与内存 。

文章插图
比如上图的多跳查询和BFS algorithm , 本质上是同一个查询 。灰色模块显示的是gremlin与cypher的查询方法 , 蓝色模块显示的是不同图数据库中BFS算法的执行方式 。但他们的结果都是一致的 , 均为点Tom的三度邻居 。也就是在业界 , N跳查询即可以作为广度/深度优先算法/khop算法单列出来 , 也可以作为图遍历/图查询中一种常用模式存在 。
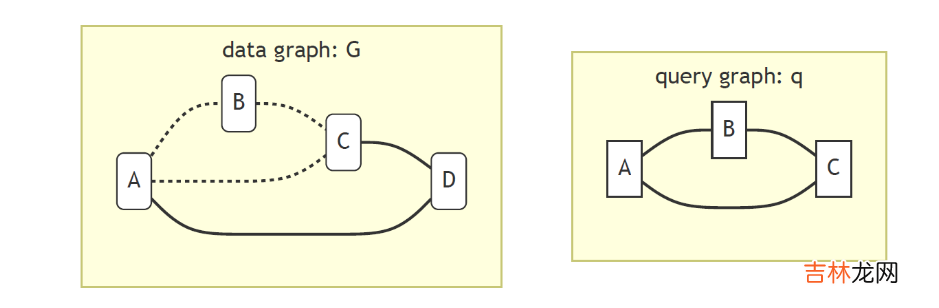
文章插图
除此以外 , subgraph matching也是一个图查询与图算法同时存在的研究课题 。如上图 , 我们输入目标子图q , 在图G中寻找其同构图 , 这其实是一个NP-Hard问题 。
当然了 , 即使子图查询是一个非常困难的问题 , 大部分图查询语言还是提供了相应的match语法用于基于模式匹配的搜索功能 , 如neo4j使用的Cypher , 或者支持指令式和声明式查询的Gremlin 。而在图算法领域 , subgraph matching则是一个极重要 , 极复杂的研究课题 。下表中列出来一部分具有代表性的子图匹配算法的分类 。(来源于paper[In-Memory Subgraph Matching: An In-depth Study]) 。
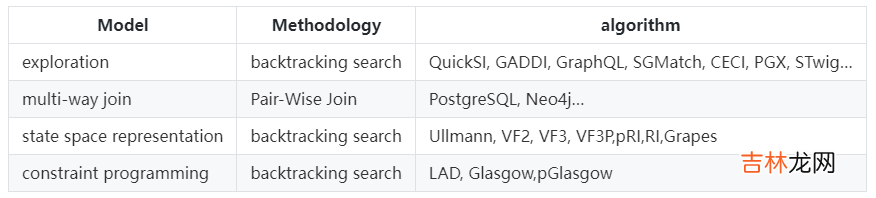
文章插图
图的应用下面让我们从一个具体的例子中体会一下图在场景中的使用 。
假设我们需要在社交关系中为用户推荐好友 , 在不同的场景中 , 可以使用不同类别的查询和算法 。如果用于在线推荐 , 我们可以将二度邻居作为其推荐结果 , 即2跳查询 , 这在大部分的图数据库中是一个代价非常小的查询 , 大多可在100ms以内完成 , 甚至可以在10ms内返回;如果用于离线推荐 , 则会倾向于使用推荐效果更优秀的图算法 。例如 , 利用社团算法louvain, labelPropagation, Strongly Connected, k-Core获得每个点的社团分类 , 并将分类结果作为点上embedding的vector参与后续downstream task计算;或者直接使用图上Node embedding算法(Node2vec, FastRP, Weisfeiler-Lehman等)得到一个完整的点上Embedding的结果用于后续训练;当然 , 也可以直接使用图相似性算法(Cosine, Jaccard等)直接得到针对某个点的推荐结果 。
经验总结扩展阅读













- 咸鱼之王龙鱼义从怎么搭配
- 哪些星座女婚后从不乱花钱
- 考研数学三具体怎么复习啊
- 微信红包表情怎么设置
- 妈妈写给儿子生日祝福语
- 零钱通挣钱吗?
- 男人开始美容才能推动社会进步
- 高铁从哪个门下车
- 2023年10月18日是举行成年礼吉日吗 2023年10月18日举行成年礼好吗
- 2023年10月18日是举办成人仪式的黄道吉日吗 2023年农历九月初四举办成人仪式吉日