
文章插图
3)const:这个表至多有一个匹配行,
Const为常量的意思,他可能想要表达出查询的效率非常高,跟查一个常量式的,用我们的唯一索引,或者主键的时候,因为无重复值,所以查询效率非常高

文章插图
4)eq_ref:多表连接中使用primary key或者 unique key作为关联条件,使用唯一性索引进行数据查找,也就是被关联表上的关联列走的是主键或者唯一索引这可能是在const之外最好的联接类型了,简单的select查询不会出现这种type

文章插图
5)ref:使用了非唯一性索引进行数据的查找或者非唯一性索引的部分前缀
5.1)简单查询(非唯一索引)

文章插图
5.2)关联表查询,idx_user_address_id是address_id和user_id的联合索引,这里使用到了user_address的左边前缀address_id部分

文章插图
6)ref_or_null:对于某个字段即需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式,简单得来说就是二级索引等值查询也能搜索到值为null得行 。(注意,此时在表中添加了一行为null得数据)

文章插图
7)index_merge:在查询过程中需要多个索引组合使用

文章插图
8)range:表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, 或者 IN()

文章插图
9)index:全索引扫描这个比all的效率要好,主要有两种情况,一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取,或者是使用了索引进行排序,这样就避免数据的重排序,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比All快一些

文章插图
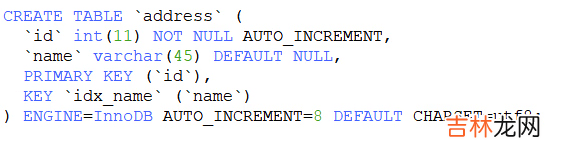
文章插图
那么这里提出一个问题,address表中其实有两个索引,一个是主键索引,一个是二级索引idx_name,那么为什么这里会使用二级索引而不是主键索引呢?
打开address表你会发现 。。Address只有两个字段一个id,一个name,而idx_name这个索引树中就包含了name和id,而要查的字段都存在于idx_name索引树中,mysql有一个这样的优化原则,凡是我查找结果集的分析我查找出来,如果这个结果集的几个字段在我们所有索引里面都有,他会优先选择二级索引去查,因为二级索引小不管是主键索引还是二级索引都是从叶子节点的第一个开始找,遍历到最后一个
11)all:全表扫描,扫描你的聚簇索引的所有叶子节点,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要增加索引来进行优化了 。

经验总结扩展阅读















- 迷你世界10月19日激活码是多少
- 幼儿园国庆节放假通知及温馨提示
- 头伏吃什么二伏吃什么三伏吃什么
- SpringBoot+Vue3 AgileBoot - 手把手一步一步带你Run起全栈项目
- 能够满足你一切少女心的星座男
- 越容易追到你就越容易抛弃你的星座
- 运动 减肥的尽头,其实是提高代谢,10个方法让你从125瘦到95斤
- 怎么p图(手机怎么p图改数字)
- 怎么判断自己是不是恋爱脑 这8种表现有你吗
- 短而精的个性签名有内涵 你一定会喜欢的签名