文章插图
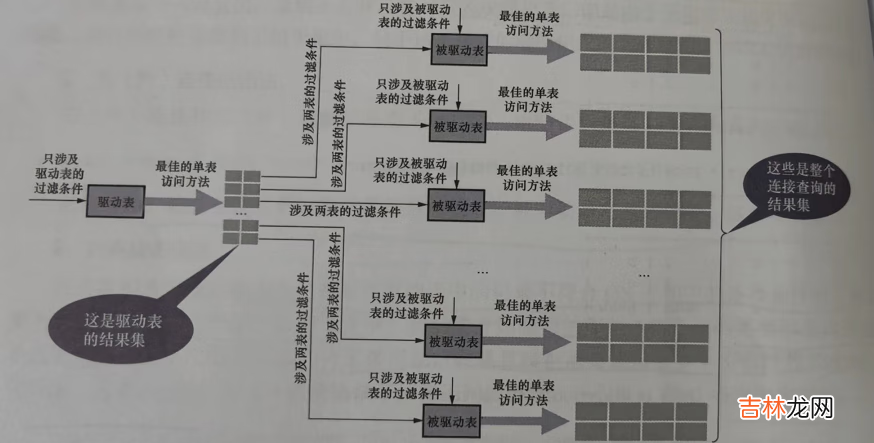
这样就将夺多表的连接查询 , 转化为多次单表查询 , 其中驱动表只需要访问依次 , 但是被驱动表需要访问多次 , 访问的次数取决于驱动表执行单表查询后的结果集具备多少条记录 。
这或许就是为什么外连接建议使用小表join大表
6.2 使用索引加载连接速度在获取到驱动表的单表查询后的一条记录后 , 需要在被驱动中找到符合条件的记录
select * from a left join b on a.id=b.id where a.name like '%陈%' and b.age>10首先是执行
select * from a wherea.name like '%陈%' ,在a表中得到a.id=1和a.id=2的记录 , 然后去b中执行select * from b where b.id=1 and b.age>10 和select * from b where b.id=2 and b.age>10如果id是b表的索引 , 这时候就可以使用到索引 , 或者age是b表的索引也同样可以使用到索引,由于查询的是
*如果索引B+树叶子节点的内容无法覆盖 , 那么将进行回表6.3 基于块的嵌套连接查询上面我们说到
嵌套循环连接 , 每次在驱动表中获取到一条记录都需要去被驱动表中进行查询 , 如果驱动表查询到了很多条数据 , 被驱动表数据量很大 , 且无法使用到被驱动表的索引 , 那么需要对被驱动表进行多次全表扫描 , 导致IO代价非常大 , 所以需要减少被驱动表的访问次数解决的办法便是 , 将被驱动表的记录加载到内存 , 一次性和驱动表中的多条记录进行匹配 。mysql有一个
join buffer,在执行连接查询的时候申请一块固定大小的内存 , 先把若干条驱动表结果集 , 转载join buffer中 , 然后开始扫描被驱动表 , 然后被驱动表的记录一次性与join buffer进行匹配 , 由于匹配是在内存中进行的 , 这样可以显著减少被驱动表的io代价 。Join buffer的大小可以通过join_buffer_size,如果实在无法在被驱动表上使用到较好的索引 , mysql服务所在的机器内存比较大 , 可以调大对连接查询进行优化 。Join Buffer并不会存储驱动表的所有字段 , 只会存储涉及到查询条件的字段和查询列表中的字段 , 所以尽量不要使用select * 可以让join buffer存放更多的数据五丶基于规则的优化&子查询优化1条件化简
- 移除不必要的括号 , 虽然我们sql里面写了无用的括号(方便人阅读)但是mysql会将括号移除掉
- 常量传递
select * from a where a.age=10 and a.b>a.age会被优化为select * from a where a.age=10 and a.b>10
- 移除无用的条件
恒成立的条件会被移除
- 表达式计算
对于select * from a=5+1会被优化为a=6
但是对于abs(a)>5则不会优化 , 且无法使用索引
- having子句和where 子句合并
查询语句中没用sum , max等聚集函数以及group by子句 , 那么having会和where子句合并起来
select * from user ugroup by u.name having sum(u.age)>4比如这条将无法和where 合并
但是select * from user u having u.age>4等同于select * from user u where u.age>4经验总结扩展阅读
- 手机怎样连接我的电脑(手机怎么访问自己电脑)
- MYSQL-->InnoDB引擎底层原理
- 浅谈MySQL、Hadoop、BigTable、Clickhouse数据读写机制
- Docker | Compose创建mysql容器
- 一文读懂 MySQL 索引
- 如何优雅的备份MySQL数据?看这篇文章就够了
- 【博学谷学习记录】超强总结,用心分享|MySql连接查询超详细总结
- day08-MySQL事务
- MySQL 窗口函数
- 线上服务宕机,码农试用期被毕业,原因竟是给MySQL加个字段