前言今天我们一起来看一下如何使用LabVIEW实现语义分割 。
一、什么是语义分割图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图 。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解,比如下图的语义就是一个人牵着四只羊;分割的意思是从像素的角度分割出图片中的不同对象,对原图中的每个像素都进行标注,比如下图中浅黄色代表人,蓝绿色代表羊 。语义分割任务就是将图片中的不同类别,用不同的颜色标记出来,每一个类别使用一种颜色 。常用于医学图像,卫星图像,无人车驾驶,机器人等领域 。

文章插图
- 如何做到将像素点上色呢?

文章插图
二、什么是deeplabv3DeepLabv3是一种语义分割架构,它在DeepLabv2的基础上进行了一些修改 。为了处理在多个尺度上分割对象的问题,设计了在级联或并行中采用多孔卷积的模块,通过采用多个多孔速率来捕获多尺度上下文 。此外,来自 DeepLabv2 的 Atrous Spatial Pyramid Pooling模块增加了编码全局上下文的图像级特征,并进一步提高了性能 。
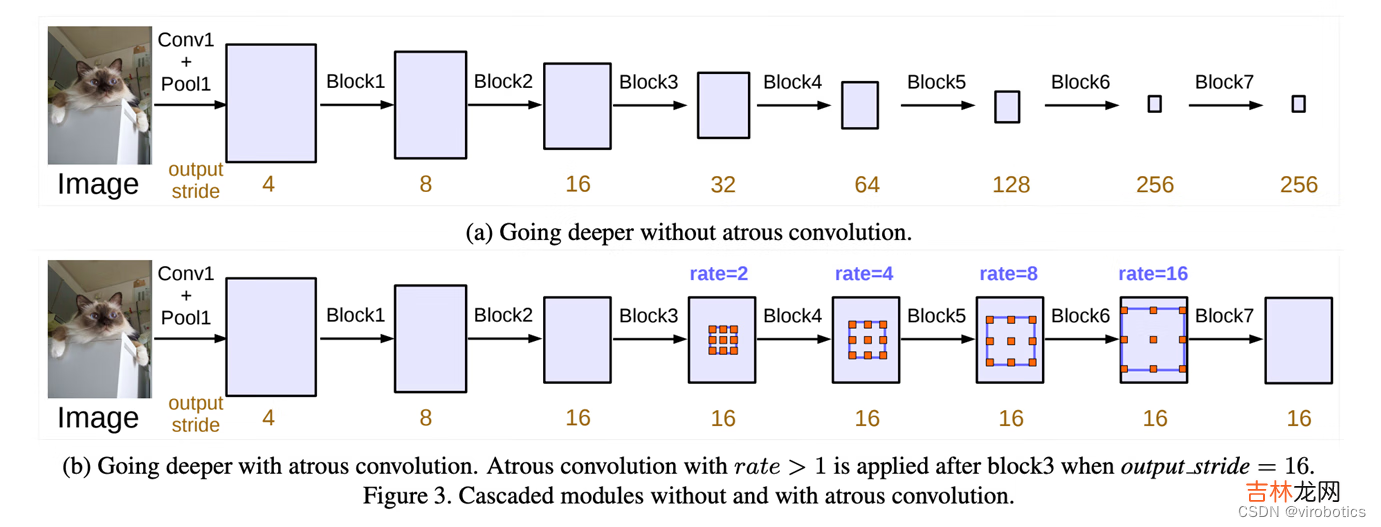
文章插图
三、LabVIEW调用DeepLabv3实现图像语义分割1、模型获取及转换
- 安装pytorch和torchvision
- 获取torchvision中的模型:deeplabv3_resnet101(我们获取预训练好的模型):
- 转onnx

文章插图

文章插图
1 def get_pytorch_onnx_model(original_model): 2# define the directory for further converted model save 3onnx_model_path = dirname 4# define the name of further converted model 5onnx_model_name = "deeplabv3_resnet101.onnx" 6 ? 7# create directory for further converted model 8os.makedirs(onnx_model_path, exist_ok=True) 9 ?10# get full path to the converted model11full_model_path = os.path.join(onnx_model_path, onnx_model_name)12 ?13# generate model input14generated_input = Variable(15torch.randn(1, 3, 448, 448)16)17 ?18# model export into ONNX format19torch.onnx.export(20original_model,21generated_input,22full_model_path,23verbose=True,24input_names=["input"],25output_names=["output",'aux'],26opset_version=1127)28 ?29return full_model_path完整获取及模型转换python代码如下:
文章插图
文章插图
1 import os 2 import torch 3 import torch.onnx 4 from torch.autograd import Variable 5 from torchvision import models 6 import re 7 ? 8 dirname, filename = os.path.split(os.path.abspath(__file__)) 9 print(dirname)10 ?11 def get_pytorch_onnx_model(original_model):12# define the directory for further converted model save13onnx_model_path = dirname14# define the name of further converted model15onnx_model_name = "deeplabv3_resnet101.onnx"16 ?17# create directory for further converted model18os.makedirs(onnx_model_path, exist_ok=True)19 ?20# get full path to the converted model21full_model_path = os.path.join(onnx_model_path, onnx_model_name)22 ?23# generate model input24generated_input = Variable(25torch.randn(1, 3, 448, 448)26)27 ?28# model export into ONNX format29torch.onnx.export(30original_model,31generated_input,32full_model_path,33verbose=True,34input_names=["input"],35output_names=["output",'aux'],36opset_version=1137)38 ?39return full_model_path40 ?41 ?42 def main():43# initialize PyTorch ResNet-101 model44original_model = models.segmentation.deeplabv3_resnet101(pretrained=True)45 ?46# get the path to the converted into ONNX PyTorch model47full_model_path = get_pytorch_onnx_model(original_model)48print("PyTorch ResNet-101 model was successfully converted: ", full_model_path)49 ?50 ?51 if __name__ == "__main__":52main()
经验总结扩展阅读

















- 高压锅买回来可以直接使用吗
- 天猫精灵cc7怎么使用_天猫精灵cc7使用方法
- 砂锅第一次使用怎样开锅
- iPadmini6使用体验_iPadmini6使用感受
- 高光的使用是用在定妆之前还是之后?
- 皙之密1到9号使用步骤是什么?
- FrameLess Qt--无边框窗口完美实现,包含缩放和移动功能重写。
- 西瓜水弄衣服上怎么洗干净
- Nginx 使用自签名证书实现 https 反代 Spring Boot 中碰到的页面跳转问题
- BI系统打包Docker镜像及部署的技术难度和实现