【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships( 二 )
我们在两个中国知识驱动的自然语言处理任务上进行了实验 , 即实体类型和关系分类 。实验结果表明 , 通过充分利用包含实体和细粒度关系的结构化KG , KLMo比BERT和现有的知识增强PLMs有了很大的改进 。我们还将发布一个中国的实体类型数据集 , 用于评估中国的PLMs 。
- 02模型描述
文章插图
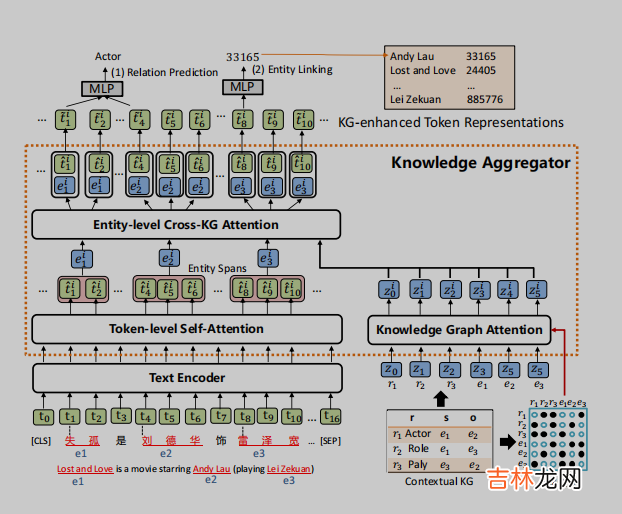
图2:模型体系结构的概述 。
2.1知识聚合器
如图2所示 , 知识聚合器被设计为一个M层知识编码器 , 将KG中的知识集成到语言表示学习中 。它接受token序列的隐藏层和KG中实体和关系的知识嵌入作为输入 , 并融合来自两个单独嵌入空间的文本和KG信息 。它接受token序列的隐藏层和KG中实体和关系的知识嵌入作为输入 , 并融合来自两个单独嵌入空间的文本和KG信息 。知识聚合器包含两个独立的多头注意力机制:token级自注意力和知识图谱注意力(Veliˇckovi‘cetal. , 2017) , 它对输入文本和KG进行独立编码 。实体表示是通过汇集一个实体片段中的所有token来计算的 。然后 , 聚合器通过实体级的交叉KG注意力 , 将文本中的实体片段与上下文KG中的所有实体和关系之间的交互进行建模 , 从而将知识融入到文本表示中 。
Knowledge Graph Attention (知识图谱注意力机制)
由于KG中的实体和关系组成了一个图 , 因此在知识表示学习过程中考虑图的结构是至关重要的 。我们首先通过TransE(Bordes et al. , 2013)表示上下文KG中的实体和关系 , 然后将它们转化为一个实体和关系向量序列{z0 , z1 , ... , zq} , 作为知识聚合器的输入 。然后 , 知识聚合器通过知识图谱注意力对实体和关系序列进行编码 , 知识图谱注意力通过将可见矩阵M引入传统的自注意机制来考虑其图结构(Liu et al. , 2020) 。可见矩阵M只允许在表示学习过程中 , KG中的相邻实体和关系彼此可见 , 如图2的右下角所示 。
Entity-level Cross-KG Attention(实体级别交叉KG注意力机制)
为了计算KG增强实体表示 , 给定一个实体提及列表(entity mention list )Ce = {(e0 , start0 , end0) , ... , (em , start m,end m)} , 知识聚合器首先计算实体片段表示{e?i0... , e?im} , 通过在文本中实体范围内的所有tokens上pooling计算得到文本中实体片段表示(Lee et al. , 2017) 。实体片段嵌入{e?i0 , ... , e?im}可以扩展到所有标记{e?i0 , ... , e?in} , 方法是为不属于任何实体片段的token创建e?ij=t?ij , 其中t?ij表示来自的第j个标记的表示token-level的自注意力 。
经验总结扩展阅读













- 【Java8新特性】- 接口中默认方法修饰为普通方法
- 美团外卖和饿了么如何实现盈利
- 蓼茸是什么东西
- qq物联是什么
- 炸萝卜饺子怎样做
- 怎样联系上下文理解词语的意思
- 美瞳什么牌子好
- 墙衣如何清洁
- 一天二十四小时有多少秒
- 怎么虚化背景