KLMo:建模细粒度关系的知识图增强预训练语言模型
(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
论文地址:https://aclanthology.org/2021.findings-emnlp.384.pdf
- 摘要
- 01引言
2001年 , 郎朗参加了BBC的毕业舞会 , 但他在中国直到2012年在《幸福三重奏》中亮相才很受欢迎 。
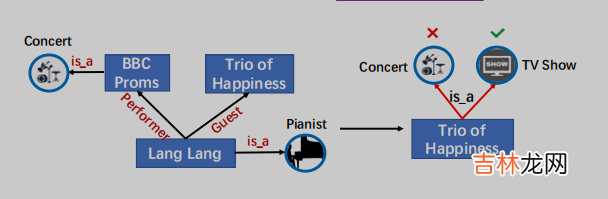
文章插图
图1:将知识合并到PLMs中的一个示例 。KG中的关系对于正确预测Trio of Happiness的类型至关重要 。
【【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships】以图1为例 , 实体类型 , 没有明确地知道细粒度Lang Lang和Trio of Happiness的关系是客人(Guest) , 这是不同于关系表演者(Performer)LangLang和BBC Proms , 不可能正确预测Trio of Happiness作为电视节目的类型 , 因为输入句子字面上意味着Trio of Happiness和BBC Proms属于同一类型 。KG中实体之间的细粒度关系为实体提供了特定的约束 , 从而在知识驱动任务的语言学习中发挥重要作用 。为了明确地将KG中的实体和细粒度关系合并到PLMs中 , 我们面临的一个主要挑战是文本-知识对齐(TKA)问题:很难为文本和知识的融合进行token-关系和token-实体对齐 。为了解决这个问题 , 我们提出了KG增强的预训练语言模型(KLMo)来将KG(即实体和细粒度关系)集成到语言表示学习中 。KLMo的主要组件是一个知识聚合器 , 它负责从两个单独的嵌入空间即token嵌入空间和KG嵌入空间 , 进行文本和知识信息的融合 。知识聚合器通过实体片段级的交叉KG注意力机制 , 建模文本中实体片段和所有实体和关系之间的交互 , 使tokens注意KG中高度相关的实体和关系 。基于KG增强的token表示 , 利用关系预测目标 , 基于KG的远程监督 , 预测文本中每对实体的关系 。关系预测和实体链接目标是将KG信息集成到文本表示中的关键 。
经验总结扩展阅读

















- 【Java8新特性】- 接口中默认方法修饰为普通方法
- 美团外卖和饿了么如何实现盈利
- 蓼茸是什么东西
- qq物联是什么
- 炸萝卜饺子怎样做
- 怎样联系上下文理解词语的意思
- 美瞳什么牌子好
- 墙衣如何清洁
- 一天二十四小时有多少秒
- 怎么虚化背景