另外一种方法就是把字符串转换成rune切片,这样也会正确打印结果:
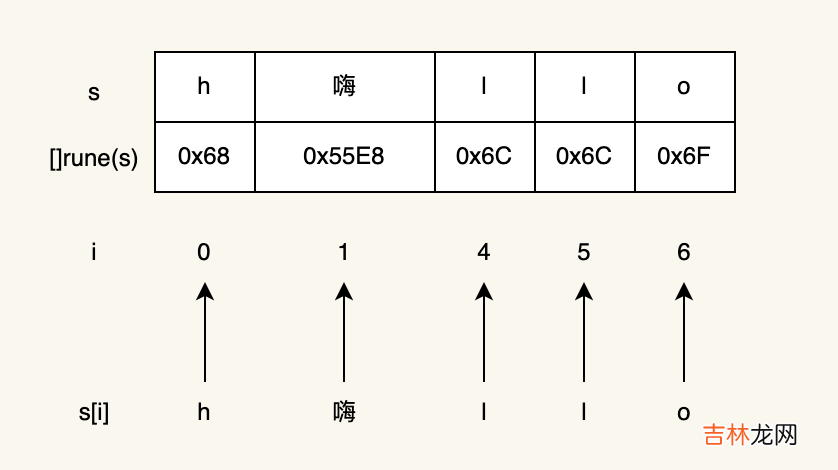
package mainimport ( "fmt" "unicode/utf8")func main() { s := "h嗨llo" b := []rune(s) for i := range b {fmt.Printf("字符位置 %d: %c\n", i, b[i]) } fmt.Printf("len=%d\n", len(s)) fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))}go run 7.go字符位置 0: h字符位置 1: 嗨字符位置 2: l字符位置 3: l字符位置 4: olen=7 rune len=5下面是rune切片遍历的过程(中间省略了将字节转换为rune的过程,需要遍历字节,复杂度为O(n))
文章插图
4、字符串trim开发中我们经常会遇到去除字符串头部或者尾部字符的操作 。比如我们现在有个字符串
xohelloxo,现在我们想去除尾部的xo,可能我们会像下面这样写:package mainimport ( "fmt" "strings")func main() { s := "xohelloxo" s = strings.TrimRight(s, "xo") fmt.Println(s)}go run 7.goxohell可以看到这不是我们期望的结果 。我们可以看下TrimRight的工作原理:- 从右侧取出第一个字符o,判断是否在xo中,在就移除
- 重复步骤1,知道不符合条件
如果我们只想删除最后xo可以使用TrimSuffix函数:
package mainimport ( "fmt" "strings")func main() { s := "xohelloxo" s = strings.TrimSuffix(s, "xo") fmt.Println(s)}go run 7.goxohello当然也有对应的从前面删除的函数TrimPrefix 。5、字符串连接开发中我们经常会用到连接字符串的操作,在go中我们一般有2种方式 。
我们先看下+号连接的方式:
package mainimport ( "fmt" "strings")func implode(values []string, operate string) string { s := "" for _, value := range values {s += operates += value } s = strings.TrimPrefix(s, operate) return s}func main() { a := []string{"hello", "world"} s := implode(a, " ") fmt.Println(s)}go run 7.go hello world这种方式的缺点就是,由于字符串的不变性,每次+号赋值的时候s不会被更新,而是重新分配内存,所以这种方式对性能有很大影响 。还有一种方式就是使用strings.Builder:
package mainimport ( "fmt" "strings")func implode(values []string, operate string) string { sb := strings.Builder{} for _, value := range values {_, _ = sb.WriteString(operate)_, _ = sb.WriteString(value) } s := strings.TrimPrefix(sb.String(), operate) return s}func main() { a := []string{"hello", "world"} s := implode(a, " ") fmt.Println(s)}go run 7.gohello world首先,我们创建了一个 strings.Builder 结构 。在每次遍历中,我们通过调用 WriteString 方法构造结果字符串,该方法将 value 的内容附加到其内部缓冲区,从而最大限度地减少内存复制 。WriteString 的第二个参数返回的是error,但是error的值会一直为nil 。之所以有第二个error参数是因为我 strings.Builder 实现了 io.StringWriter 接口,它包含一个方法:WriteString(s string) (n int, err error) 。
我们看下WriteString的内部是什么样的:
func (b *Builder) WriteString(s string) (int, error) { b.copyCheck() b.buf = append(b.buf, s...) return len(s), nil}我们可以看到b.buf是一个字节切片,而里面的实现是使用了append方法 。我们知道如果切片很大,使用append会让底层数组不断扩容,影响代码执行效率 。我们知道解决这个问题的方法是,如果事先知道切片的大小,我们可以在初始化的时候就分配好切片的容量 。
所以上面的字符串连接还有一种优化方案:
package mainimport ( "fmt" "strings")func implode(values []string, operate string) string { total := 0 for i := 0; i < len(values); i++ {total += len(values[i]) } total += len(operate) * len(values) sb := strings.Builder{} sb.Grow(total) // 这里会重新分配b.buf的长度和容量 for _, value := range values {_, _ = sb.WriteString(operate)_, _ = sb.WriteString(value) } s := strings.TrimPrefix(sb.String(), operate) return s}func main() { a := []string{"hello", "world"} s := implode(a, " ") fmt.Println(s)}
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 牛奶和可乐的化学反应
- 银杏在佛教中的寓意
- 肖凯是哪部电视剧中的中的人物?
- DevOps|从特拉斯辞职风波到研发效能中的不靠谱人干的荒唐事
- 美惠子黑旋风是什么电视剧中的人物?
- 老干棒姜红果是什么电视剧中的人物?
- 12星座恋爱中最心酸的事是什么?
- 羊儿是什么电视剧中的人物?
- 罗同彪是什么电视剧中的人物?
- 怎样转发微信内容到朋友圈(如何将微信中的内容转发到朋友圈)















