优化模型Tensorflow Lite 和 Tensorflow Model Optimization Toolkit (Tensorflow模型优化工具包)提供了最小优化推理复杂性的工具,可将优化推断的复杂性降至最低 。深度神经网络的量化使用了一些技术,这些技术可以降低权重的精确表示,并且降低存储和计算 。 TensorFlow Model Optimization Toolkit 目前支持通过量化、剪枝和聚类进行优化 。
剪枝:剪枝的工作原理是移除模型中对其预测影响很小的参数 。剪枝后的模型在磁盘上的大小相同,并且具有相同的运行时延迟,但可以更高效地压缩 。这使剪枝成为缩减模型下载大小的实用技术 。
未来,TensorFlow Lite 将降低剪枝后模型的延迟 。
聚类:聚类的工作原理是将模型中每一层的权重归入预定数量的聚类中,然后共享属于每个单独聚类的权重的质心值 。这就减少了模型中唯一权重值的数量,从而降低了其复杂性 。这样一来,就可以更高效地压缩聚类后的模型,从而提供类似于剪枝的部署优势 。
开发工作流程
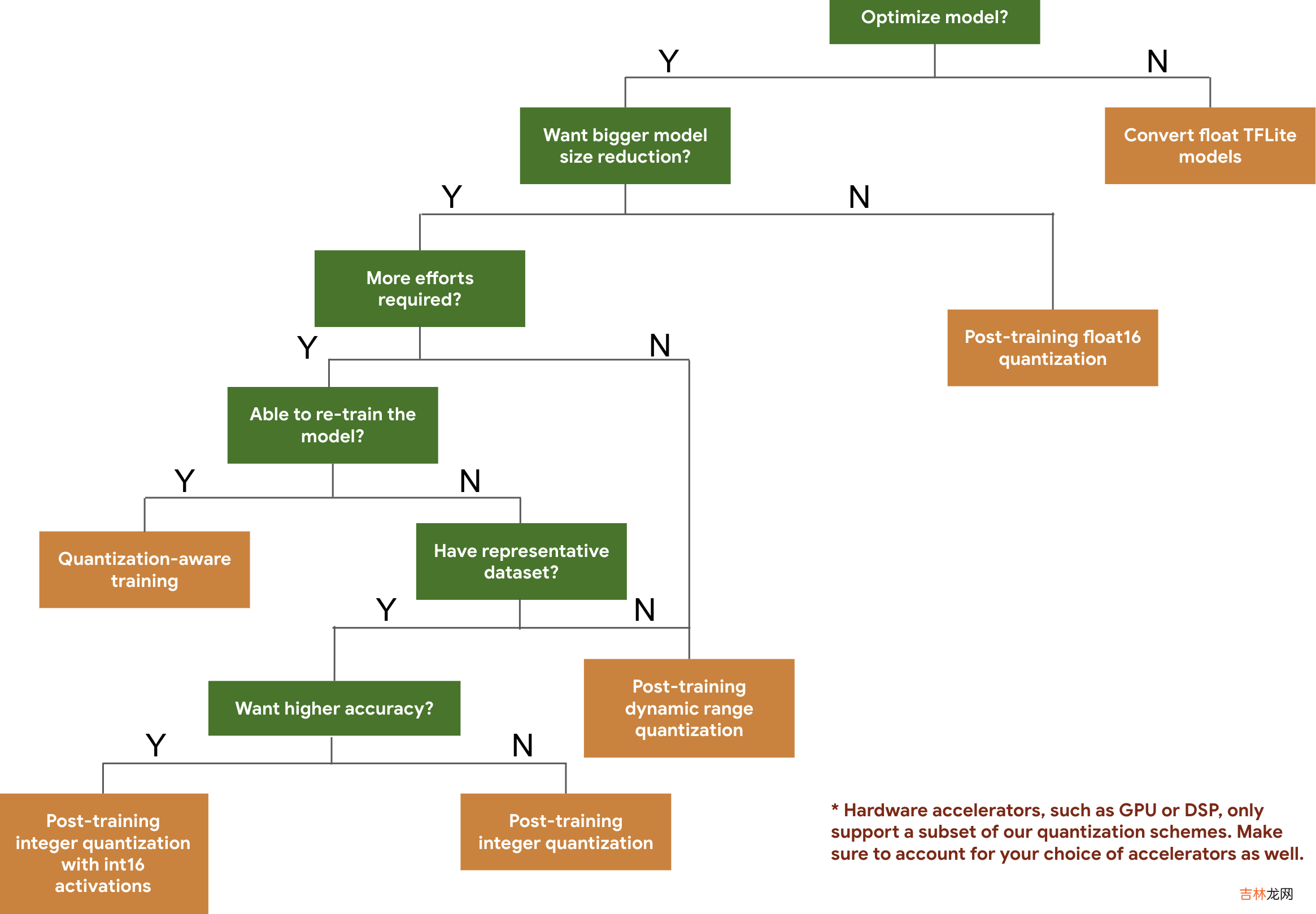
- 首先,检查托管模型中的模型能否用于您的应用 。如果不能,建议从训练后量化工具开始,因为它适用范围广,且无需训练数据 。
- 对于无法达到准确率和延迟目标,或硬件加速器支持很重要的情况,量化感知训练是更好的选择 。请参阅TensorFlow Model Optimization Toolkit下的其他优化技术 。
- 如果要进一步缩减模型大小,可以在量化模型之前尝试剪枝和/或聚类 。
量化感知训练等我将代码进行了训练后量化后,再来整这个量化感知训练
训练后量化量化的工作原理是降低模型参数的精度(默认情况为 32 位浮点数) 。这样可以获得较小的模型大小和较快的计算速度 。TensorFlow Lite 提供以下量化类型:
技术数据要求大小缩减准确率训练后 Float16 量化无数据高达 50%轻微的准确率损失训练后 动态范围量化无数据高达 75%,速度加快 2-3倍极小的准确率损失训练后 int8 量化无标签的代表性样本高达 75%,速度加快3+倍极小的准确率损失量化感知训练带标签的训练数据高达 75%极小的准确率损失以下决策树可帮助您仅根据预期的模型大小和准确率来选择要用于模型的量化方案 。
文章插图
动态范围量化权重(float32) 会在训练后量化为 整型(int8),激活会在推断时动态量化,模型大小缩减至原来的四分之一:
TFLite 支持对激活进行动态量化(激活始终以浮点进行存储 。对于支持量化内核的算子,激活会在处理前动态量化为 8 位精度,并在处理后反量化为浮点精度 。根据被转换的模型,这可以提供比纯浮点计算更快的速度)以实现以下效果:
- 在可用时使用量化内核加快实现速度 。
- 将计算图不同部分的浮点内核与量化内核混合 。
我们来吃一个完整的栗子,构建一个MNIST模型,并且对它使用动态范围量化,对比量化前后的精度变化:
经验总结扩展阅读















- 幼师好还是护士好 哪个更吃香
- 2023年2月6日是买衣服的黄道吉日吗 2023年2月6日买衣服黄道吉日
- 2023年2月6日适合制作寿衣吗 2023年2月6日是制作寿衣吉日吗
- 2023年2月6日买鸡黄道吉日 2023年2月6日买鸡行吗
- 2023年2月6日买牛好不好 2023年2月6日买牛吉日一览表
- 2023年2月6日画画好不好 2023年农历正月十六画画吉日
- 2023年10月1日入学行吗 2023年农历八月十七入学吉日
- 2023年10月1日是举办成人仪式的黄道吉日吗 2023年10月1日举办成人仪式吉日一览表
- 2023年10月1日上学好不好 2023年10月1日适合上学吗
- 2023年10月1日清扫房屋好吗 2023年农历八月十七宜清扫房屋吗