?

文章插图
?
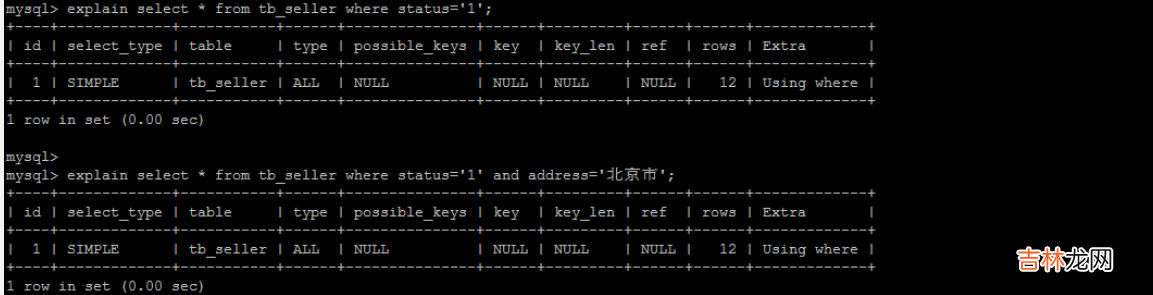
根据上面的索引结构,我们来讨论一个问题:基于主键索引和辅助索引的查询有什么区别??
- 如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
- 如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次 。这个过程称为回表 。
除非说,我们所要查询的数据,刚好就是我们索引树上存在的,此时我们称之为覆盖索引--即索引列中包含了我们要查询的所有数据 。同时,二级索引又分为了如下几种(先简单略过即可,后续我们再慢慢了解):?
- 唯一索引(Unique Key) :唯一索引也是一种约束 。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引 。建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率 。
- 普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL 。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据 。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符 。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术 。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引
我们建立了一个复合索引(name,status),索引中也是按这个字段来存储的,类似图中这样:
复合索引树(只存储索引列和主键用于回表)
namestatusid(主键)小米101小米212我们执行这样一条语句:
SELECT * FROM tb_seller WHERE name like '小米%' and status ='1' ;- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推 。最左前缀原则所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:?
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

文章插图
- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
文章插图
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)
经验总结扩展阅读














- 我的世界怎么用附魔台附魔书(我的世界用高级附魔台怎么附魔)
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- 30 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android7.0以上的Https包-番外篇
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?
- 轻奢极简店名美甲 名字高级小众美甲店名
- llinux下mysql建库、新建用户、用户授权、修改用户密码
- RedHat7.6安装mysql8步骤
- 我不完美但我独一无二签名 很高级酷酷的签名
- 29 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android7.0以上的Https包-终篇
- 究极无敌细节版 Mysql索引