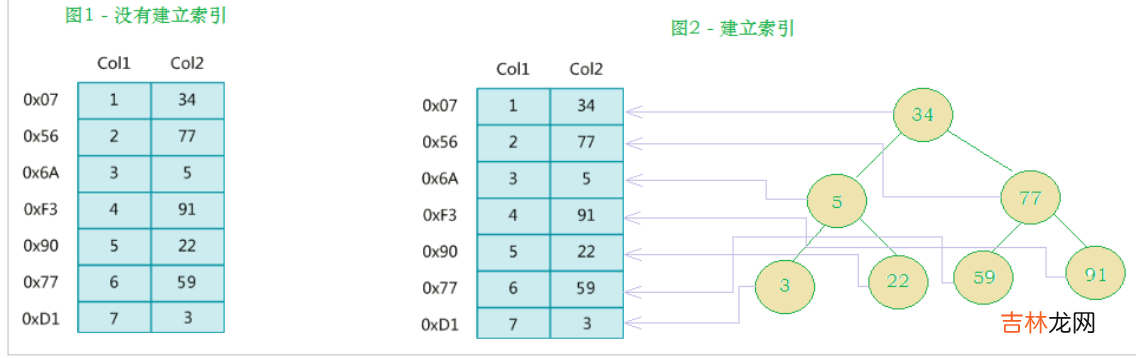
MySQL中的B+TreeMySql索引数据结构对经典的B+Tree进行了优化 。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针(整体类似一个双向链表的结构),就形成了带有顺序指针的B+Tree,提高区间访问的性能 。?
细心的同学可以看出,这张图跟我们的二叉查找树简图的一个最大区别是什么?
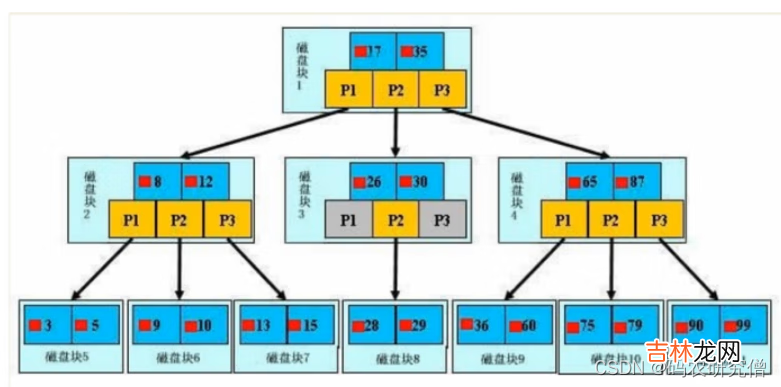
- 从二叉查找树过渡到B树,有一个显著的变化就是,一个节点可以存储多个数据了,相当于一个磁盘块里边可以存储多个数据,大大减少了我们的 IO次数!!
文章插图
二叉查找树简图:
文章插图
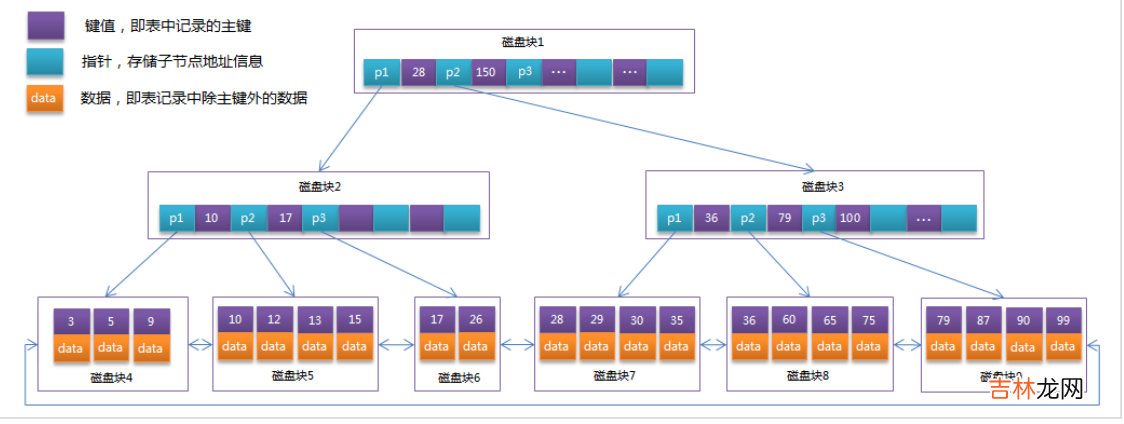
索引原理BTree索引:
文章插图
初始化介绍浅蓝色的称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块 。
- 真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99 。`
- 非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中 。`
索引分类在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表 。又因为前面我们提到的,InnoDB使用了B+树索引模型,所以数据都是存储在B+树中的 。?
每一个索引在InnoDB里面对应一棵B+树 。假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引 。这个表的建表语句是:
mysql> create table T(id int primary key,k int not null,name varchar(16),index (k))engine=InnoDB;表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两棵树的示例示意图如下: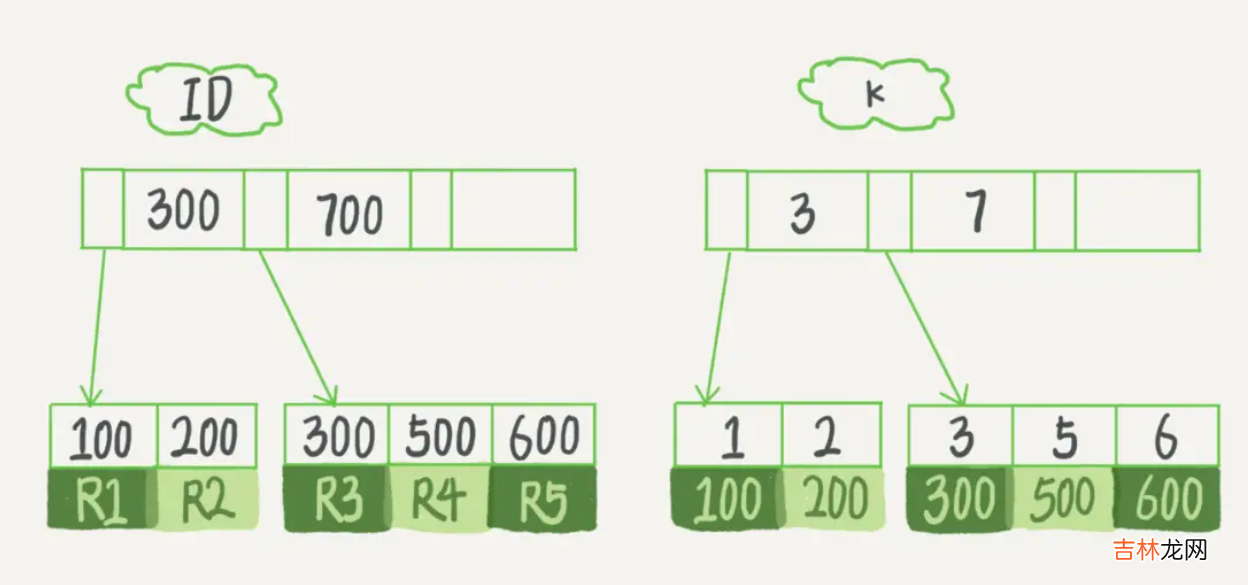
文章插图
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引 。
主键索引数据表的主键列使用的就是主键索引,且会默认创建,这也是为什么,我们还没学索引的时候,老师经常跟我们说根据主键查会快一点,原来主键本身就建好了索引 。主键索引的叶子节点存的是整行数据 。在InnoDB里,主键索引也被称为聚簇索引(clustered index) 。
辅助索引辅助索引的叶子节点内容是主键的值 。在InnoDB里,辅助索引也被称为二级索引(secondary index) 。?
如下图:
- 主键索引存放了整行数据
- 辅助索引只存放了自己本身,以及id主键用于回表查询
经验总结扩展阅读
- 我的世界怎么用附魔台附魔书(我的世界用高级附魔台怎么附魔)
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- 30 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android7.0以上的Https包-番外篇
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?
- 轻奢极简店名美甲 名字高级小众美甲店名
- llinux下mysql建库、新建用户、用户授权、修改用户密码
- RedHat7.6安装mysql8步骤
- 我不完美但我独一无二签名 很高级酷酷的签名
- 29 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android7.0以上的Https包-终篇
- 究极无敌细节版 Mysql索引