摘要:本文结合图解和问题,教你一次性搞定HashMap本文分享自华为云社区《java中HashMap的设计精妙在哪?用图解和几个问题教你一次性搞定HashMap》,作者:breakDawn 。
HashMap核心原理
文章插图
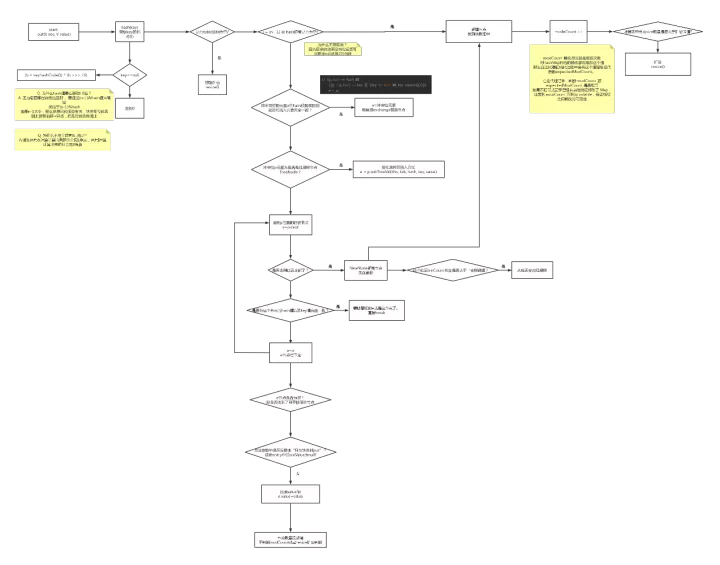
HashMap完整的put过程以下是对上图的详细解释:
- 首先,要获取key的哈希值 。如果为空,就统一是0否则,调用对象的.hashCode()方法,接着再与自己的右移16位进行异或,以便充分利用高位信息 。
- 接着判断内部node数组是否为空,如果是,先进行初始化扩容 。默认为16 。
- 根据(n-1)&hash值,获取哈希表索引位置 。
- 哈希表的node数组中,存放的是每组链表的头节点 。先检查头节点是否和自己要存放的key完全匹配 (hash值相同,key值相同,先hash再key,是因为hash的判断简单,key的equals判断可能会复杂) 。如果匹配,得到需要替换的节点 。
- 头节点和自己要放的key不匹配,则判断一下这个头节点是否是红黑树节点,如果是,说明已经升级成红黑树了,调用putTree插入到红黑树中 。
- 如果不是红黑树,那就是遍历链表,完全匹配就得到需要替换的节点 。如果到尾部了,也没匹配的,则插入新节点 。
- 如果前面找到了要替换的节点,则判断一下是否可以替换(是否没要求putIfAbsent,或者value为null),是就替换,不是就结束
- 如果前面是插入了新节点,非替换,则要modCount++(方便迭代器确认map是否更新),同时++size,然后和扩容阈值做判断,如果太大,就resize进行扩容
- 当resize时,新建一个数组newTable
- 遍历原table中的每个链表和节点,重新hash,找到新的位置放入
- 放入的方式是头插法,即始终插在链表的头节点 。
- 不再每个点rehash放置,而是最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标. 避免了频繁的哈希计算和搬移过程 。
- 使用尾插法在链表上插入节点
- 桶内元素超过8个,链表转成红黑树
B线程则同时完成线程扩容,但是map里都是引用,浅拷贝,** 因为是头插法,会导致顺序变化**,原本a->b->c 变成了c->b->a 。因此A恢复时,链点还是a,next还是b,于是往下走到了b,取bbs的next时,已经变成了a,于是发生了a->b->a的循环导致后续操作的next都是错误操作,引发环形指针 。
java8里改成尾插法,这样做resize时,a->b->c 如果仍然哈希到同一个节点,顺序是不会发生变化的 。
虽然解决了死循环问题,但java8的hashMap仍然是线程不安全的,为什么?A:因为缺乏同步,导致同节点发生哈希碰撞时,if条件的判断都可能是有问题的,导致本该插在链表头节点后面的,结果直接作为链表头覆盖到数组上了 。
具体到底满足什么情况,才会resize扩容呢?A:HashMap负载因子 LoadFactor,默认值为0.75f 。衡量HashMap是否进行Resize的条件如下:HashMap.Size >= Capacity * LoadFactor
另一种情况 。JDK1.8源码中,执行树形化之前,会先检查数组长度,如果长度小于64,则对数组进行扩容,而不是进行树形化
扩容后,capacity扩容多少倍呢?为什么A:哈希表每次扩容是两倍 。初始长度为2的幂次方,随后以2倍扩容的方式扩容,元素在新表中的位置要么不动,要么有规律的出现在新表中(二的幂次方偏移量),这样会使扩容的效率大大提高 。另外,hashmap采用二倍扩容还有另外一个好处:可以使元素均匀的散布hashmap中,减少hash碰撞 。
经验总结扩展阅读













- 在中国举办的奥运会是哪一年
- 生石灰怎么变熟石灰
- 2023年9月26日装修行吗 2023年9月26日装修好不好
- 2023年9月26日修建仓库好吗 2023年9月26日修建仓库行吗
- 2023年9月26日是建造仓库吉日吗 2023年9月26日建造仓库黄道吉日
- 拔罐是中国的还是西方的
- 2023年9月26日打地基黄道吉日 2023年9月26日打地基行吗
- 崩坏3阿波尼亚怎么获取
- 古代四大美女的体重身高
- 2023年9月26日建造船只吉日一览表 2023年9月26日建造船只黄道吉日