文章插图
# 查看private_bath字段gm_regression_df['private_bath'].value_counts()

文章插图
gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("private bath", "pb", case=False)gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("private baths", "pbs", case=False)gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("shared bath", "sb", case=False)gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("shared baths", "sb", case=False)gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("shared half-bath", "sb", case=False)gm_regression_df['bathrooms_text'] =gm_regression_df['bathrooms_text'].str.replace("private half-bath", "sb", case=False)gm_regression_df = split_bathroom(gm_regression_df, column='bathrooms_text', text='bath', new_column='bathrooms_new')gm_regression_df['shared_bath'] = gm_regression_df['shared_bath'].str.split(" ", expand=True)gm_regression_df['private_bath'] = gm_regression_df['private_bath'].str.split(" ", expand=True)gm_regression_df['bathrooms_new'] = gm_regression_df['bathrooms_new'].str.split(" ", expand=True)# 填充缺失值为0gm_regression_df = gm_regression_df.fillna(0)gm_regression_df['shared_bath'] = gm_regression_df['shared_bath'].replace(to_replace='Shared', value=https://www.huyubaike.com/biancheng/0.5)gm_regression_df['private_bath'] = gm_regression_df['private_bath'].replace(to_replace='Private', value=https://www.huyubaike.com/biancheng/0.5)gm_regression_df['bathrooms_new'] = gm_regression_df['bathrooms_new'].replace(to_replace='Half-bath', value=https://www.huyubaike.com/biancheng/0.5)# 转成数值型gm_regression_df['shared_bath'] = pd.to_numeric(gm_regression_df['shared_bath']).astype(int)gm_regression_df['private_bath'] = pd.to_numeric(gm_regression_df['private_bath']).astype(int)gm_regression_df['bathrooms_new'] =pd.to_numeric(gm_regression_df['bathrooms_new']).astype(int)# 查看处理后的字段gm_regression_df[['shared_bath', 'private_bath', 'bathrooms_new']].head()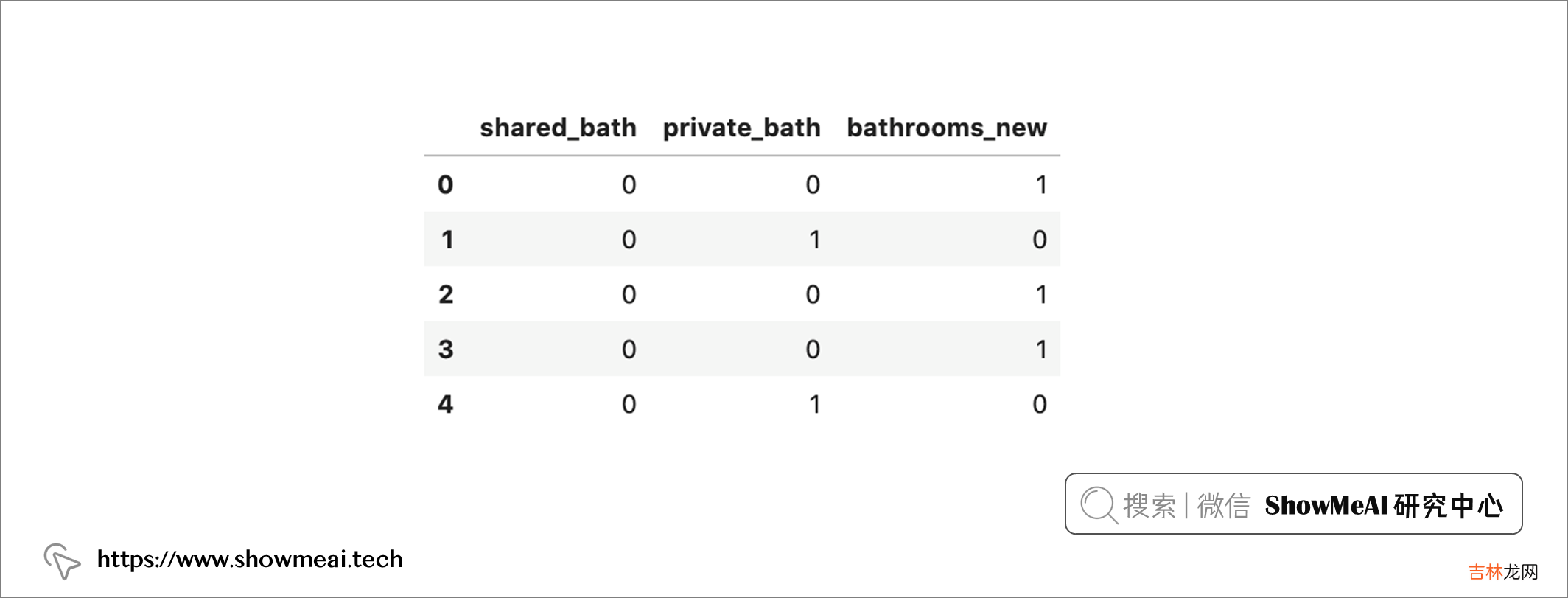
文章插图
下面我们对类别型字段进行编码,根据字段含义的不同,我们使用「序号编码」和「独热向量编码」等方法来完成 。
# 序号编码def encoder(df):for column in df[['neighbourhood_group_cleansed', 'property_type']].columns:labels = df[column].astype('category').cat.categories.tolist()replace_map = {column : {k: v for k,v in zip(labels,list(range(1,len(labels)+1)))}}df.replace(replace_map, inplace=True)print(replace_map)return df gm_regression_df = encoder(gm_regression_df)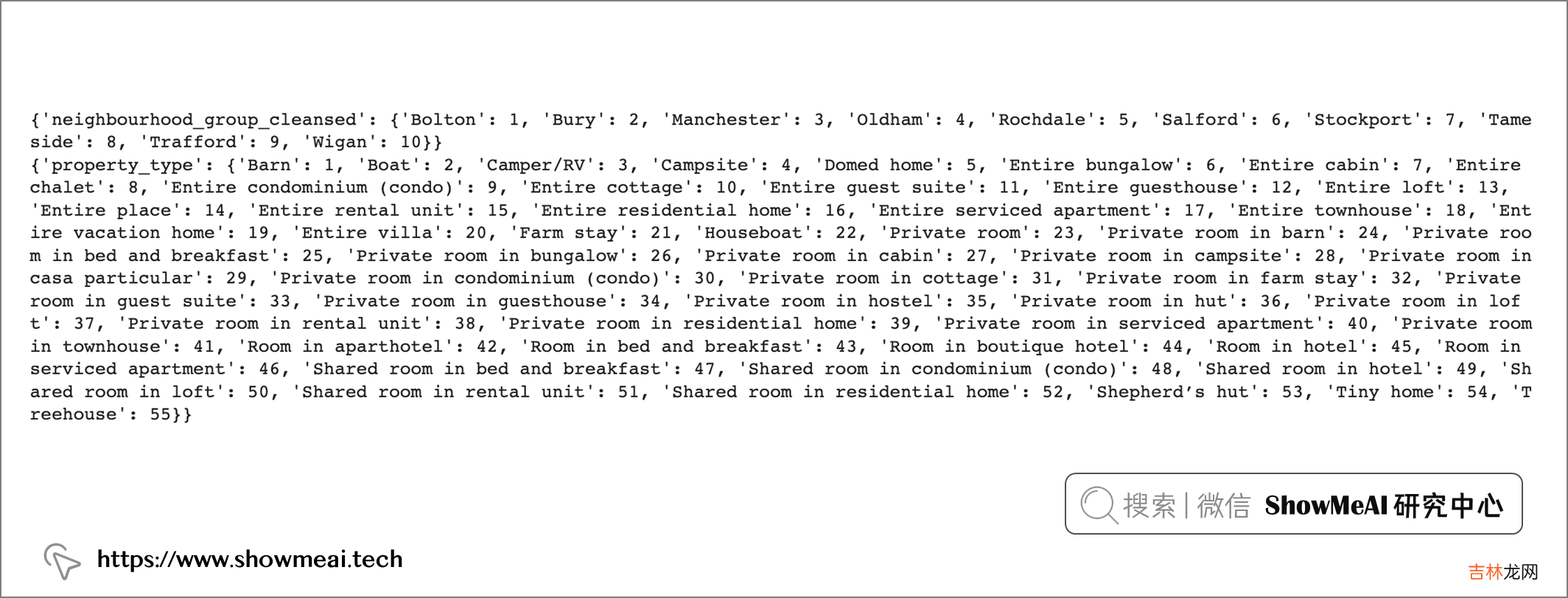
文章插图
我们对于
host_response_time和room_type字段,使用独热向量编码(哑变量变换)host_dummy = pd.get_dummies(gm_regression_df['host_response_time'], prefix='host_response')room_dummy = pd.get_dummies(gm_regression_df['room_type'], prefix='room_type')# 拼接编码后的字段gm_regression_df = pd.concat([gm_regression_df, host_dummy, room_dummy], axis=1)# 剔除原始字段gm_regression_df = gm_regression_df.drop(columns=['host_response_time', 'room_type'], axis=1)我们再把之前处理过的df_amenities做一点处理,再拼接到数据特征里df_3 = pd.DataFrame(df_amenities.sum())features = df_3['amenities'][:150].to_list()amenities_updated = df_amenities.filter(items=(features))gm_regression_df = pd.concat([gm_regression_df, amenities_updated], axis=1)查看一下最终数据的维度gm_regression_df.shape# (3584, 198)我们最后得到了198个字段,为了避免特征之间的多重共线性,使用方差因子法(VIF)来选择机器学习模型的特征 。VIF 大于 10 的特征被删除,因为这些特征的方差可以由数据集中的其他特征表示和解释 。
经验总结扩展阅读












- 常熟旅游景点有哪些 常熟必去十大景点
- 2023年农历八月十二旅游吉日 2023年9月26日旅游好不好
- 一篇文章带你了解NoSql数据库——Redis简单入门
- 旅游发圈的精致句子出游短句唯美
- 两个人去张家界旅游三天大概需要多少钱
- 2023年9月27日旅游黄道吉日 2023年9月27日是旅游的黄道吉日吗
- 2023年2月2日是旅游的黄道吉日吗 2023年2月2日适合旅游吗
- 带你去看海底星空是什么意思
- 带你去看海底星空是什么梗
- 一篇文章带你了解服务器操作系统——Linux简单入门