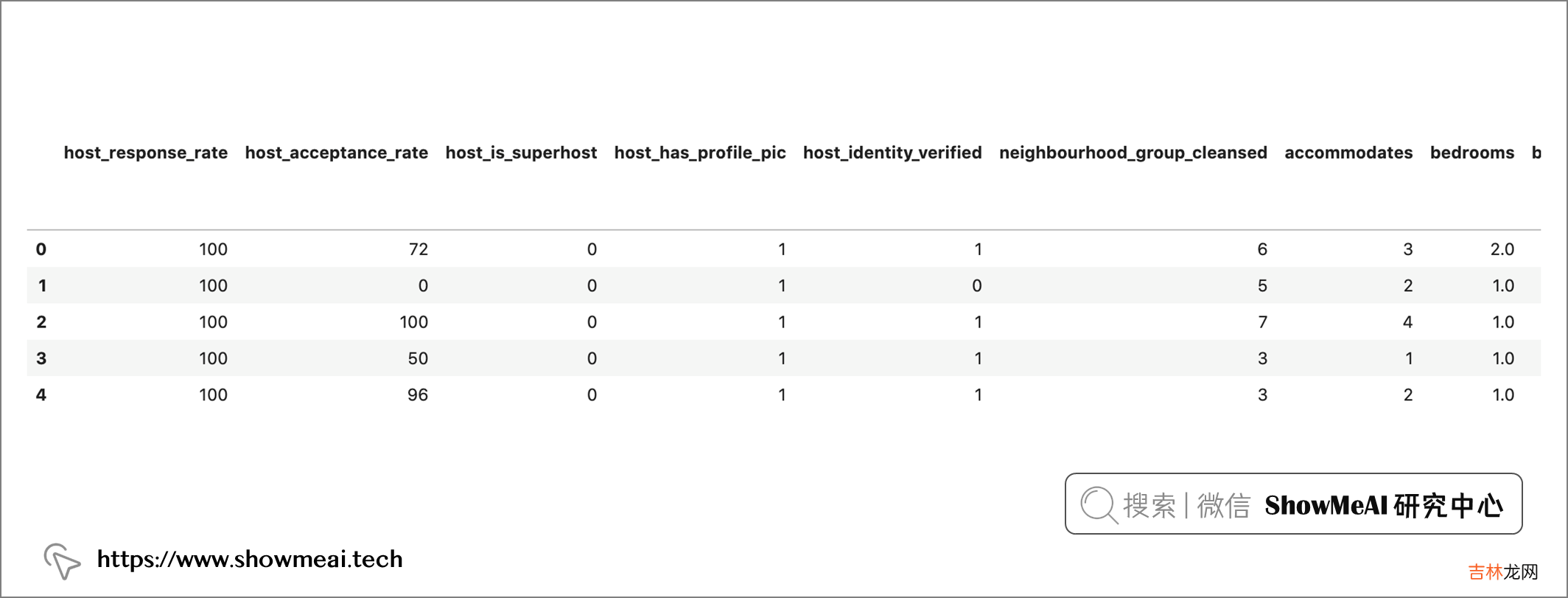
# 计算VIFvif_model = gm_regression_df.drop(['price'], axis=1)vif_df = pd.DataFrame()vif_df['feature'] = vif_model.columnsvif_df['VIF'] = [variance_inflation_factor(vif_model.values, i) for i in range(len(vif_model.columns))]# 选出小于10的特征vif_df_new = vif_df[vif_df['VIF']<=10]feature_list =vif_df_new['feature'].to_list()# 选出这些特征对应的数据model_df = gm_regression_df.filter(items=(feature_list))model_df.head()
文章插图
我们拼接上
price目标标签字段,可以构建完整的数据集price_col = gm_regression_df['price']model_df = model_df.join(price_col)机器学习算法我们在这里使用几个典型的回归算法,包括线性回归、RandomForestRegression、Lasso Regression 和 GradientBoostingRegression 。关于机器学习算法的应用方法,欢迎大家查阅ShowMeAI对应的教程与文章,快学快用 。线性回归建模
- 机器学习实战:手把手教你玩转机器学习系列
- 机器学习实战 | SKLearn入门与简单应用案例
- 机器学习实战 | SKLearn最全应用指南
def linear_reg(df, test_size=0.3, random_state=42):'''构建模型并返回评估结果输入: 数据dataframe输出: 特征重要度与评估准则(RMSE与R-squared)'''X = df.drop(columns=['price'])y = df[['price']]X_columns = X.columns# 切分训练集与测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = test_size, random_state=random_state)# 线性回归分类器clf = LinearRegression()# 候选参数列表parameters = {'n_jobs': [1, 2, 5, 10, 100],'fit_intercept': [True, False]}# 网格搜索交叉验证调参cv = GridSearchCV(estimator=clf, param_grid=parameters, cv=3, verbose=3)cv.fit(X_train,y_train)# 测试集预估pred = cv.predict(X_test)# 模型评估r2 = r2_score(y_test, pred)mse = mean_squared_error(y_test, pred)rmse = mse **.5# 最佳参数best_par = cv.best_params_coefficients = cv.best_estimator_.coef_#特征重要度importance = np.abs(coefficients)feature_importance = pd.DataFrame(importance, columns=X_columns).T#feature_importance = feature_importance.Tfeature_importance.columns = ['importance']feature_importance = feature_importance.sort_values('importance', ascending=False)print("The model performance for testing set")print("--------------------------------------")print('RMSE is {}'.format(rmse))print('R2 score is {}'.format(r2))print("\n")return feature_importance, rmse, r2 linear_feat_importance, linear_rmse, linear_r2 = linear_reg(model_df)
文章插图
随机森林建模
# 随机森林建模def random_forest(df):'''构建模型并返回评估结果输入: 数据dataframe输出: 特征重要度与评估准则(RMSE与R-squared)'''X = df.drop(['price'], axis=1)X_columns = X.columnsy = df['price']X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)# 随机森林模型clf = RandomForestRegressor()# 候选参数parameters = {'n_estimators': [50, 100, 200, 300, 400],'max_depth': [2, 3, 4, 5],'max_depth': [80, 90, 100]}# 网格搜索交叉验证调参cv = GridSearchCV(estimator=clf, param_grid=parameters, cv=5, verbose=3)model = cvmodel.fit(X_train, y_train)# 测试集预估pred = model.predict(X_test)# 模型评估mse = mean_squared_error(y_test, pred)rmse = mse**.5r2 = r2_score(y_test, pred)# 最佳超参数best_par = model.best_params_# 特征重要度r = permutation_importance(model, X_test, y_test,n_repeats=10,random_state=0)perm = pd.DataFrame(columns=['AVG_Importance'], index=[i for i in X_train.columns])perm['AVG_Importance'] = r.importances_meanperm = perm.sort_values(by='AVG_Importance', ascending=False);return rmse, r2, best_par, perm# 运行建模r_forest_rmse, r_forest_r2, r_fores_best_params, r_forest_importance = random_forest(model_df)
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 常熟旅游景点有哪些 常熟必去十大景点
- 2023年农历八月十二旅游吉日 2023年9月26日旅游好不好
- 一篇文章带你了解NoSql数据库——Redis简单入门
- 旅游发圈的精致句子出游短句唯美
- 两个人去张家界旅游三天大概需要多少钱
- 2023年9月27日旅游黄道吉日 2023年9月27日是旅游的黄道吉日吗
- 2023年2月2日是旅游的黄道吉日吗 2023年2月2日适合旅游吗
- 带你去看海底星空是什么意思
- 带你去看海底星空是什么梗
- 一篇文章带你了解服务器操作系统——Linux简单入门











