大家好,我是melo,一名大三后台练习生专栏回顾
- 索引的原理&&设计原则欢迎关注本专栏:MySQL高级篇
- 详解explain分析SQL
- 索引失效的几个场景
- ......
- SQL优化的几个场景
- 大批量插入
- order by
- group by
- limit分页
- insert操作
- 嵌套查询
- or条件
注意,本文MySQL版本为5.6.43,部分结论在其他版本可能不适用!!!
- 本篇篇幅较长,全文近8500字,可以收藏下来慢慢啃,没事就掏出来翻阅翻阅 。
建议通过侧边栏目录检索对您有帮助的部分,其中有emoji表情前缀属于重点部分,觉得对您有帮助的话,melo还会持续更进完善本篇文章和MySQL专栏 。好,现在我们已经掌握了索引的基本原理和使用方法了,要来大干一场优化SQL了!等等,我们要优化什么SQL来着,裤子都脱了,结果没对象可以.....

文章插图
别着急,这篇既然挂着MySQL高级篇,自然MySQL还是很高级的,给我们提供了几种方法,来为我们找到SQL,并分析SQL 。本篇,我们先着重讲解如何分析,具体如何找到SQL,后续的实战篇,我们再来详细谈一谈 。
【一、explain】分析SQL

文章插图
explain中,包含了如下几个字段(不同版本可能会有所差异):
字段含义idselect查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序 。select_type表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等table输出结果集的表partitions查询时匹配到的分区信息,对于非分区表值为NULL,当查询的是分区表时,partitions显示分区表命中的分区情况 。type表示表的连接类型,性能由好到差的连接类型为( system ---> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index ------> all )possible_keys表示查询时,可能使用的索引key表示查询时,实际使用的索引key_len索引字段的长度,可用来区分长短索引rows扫描行的数量filtered表里符合条件的记录数所占的百分比extra执行情况的说明和描述
看完是不是很懵,感觉好多要记忆的,别着急,下边我们通过实际案例,来加深记忆idid 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序 。id 情况有三种 :?
- 此处只是单表查询,id只有一个

文章插图
- id一样,则从上到下
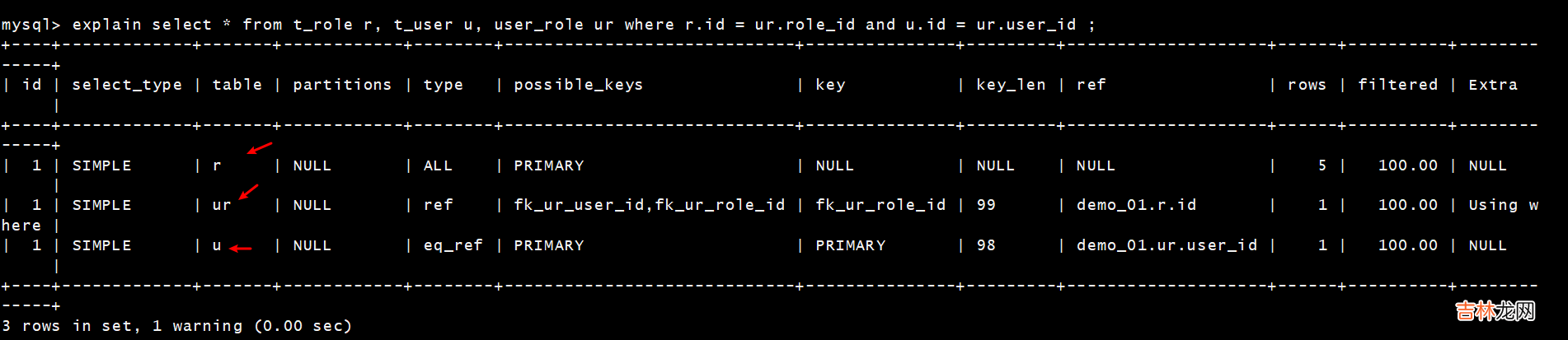
文章插图
- id不同,则id值越大,优先级越高
此处是嵌套子查询,最内部的子查询,自然是最先执行的

文章插图
简而言之:
- id值越大,优先级越高;
- id值一样,则从上到下;
经验总结扩展阅读
- 31 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android系统中Flutter应用程序的包
- 「MySQL高级篇」MySQL索引原理,设计原则
- 我的世界怎么用附魔台附魔书(我的世界用高级附魔台怎么附魔)
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- 30 《吐血整理》高级系列教程-吃透Fiddler抓包教程-Fiddler如何抓取Android7.0以上的Https包-番外篇
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?
- 轻奢极简店名美甲 名字高级小众美甲店名
- llinux下mysql建库、新建用户、用户授权、修改用户密码
- RedHat7.6安装mysql8步骤
- 我不完美但我独一无二签名 很高级酷酷的签名











